
This is a time of great interest in new hardware. Computers are becoming much more complex. The multicore era has given way to increasingly heterogeneous computing platforms. Modern SoCs contain a tremendous variety of processors, accelerators, and peripheral devices, to extract optimal performance/watt from a limited transistor budget.
Similarly, in servers and datacenters CPUs and GPUs are increasingly accompanied by specialized processors (such as Tensor Processing Units) or FPGAs (in Amazon F1 and Microsoft Azure). Network switches are moving towards highly programmable forwarding hardware. Even processor architecture itself is moving in new directions, from complete ISAs like RISC-V to features not hitherto seen in mainstream core like enclaves (e.g. SGX), and capabilities (e.g. CHERI). All this means it’s also an exciting time for system software research. We need software to compile for, optimize, debug, multiplex, protect, interconnect, and virtualize all these new platforms.
This post, however, is about a problem this causes, from the perspective of academic OS and database researchers working particularly in the space of servers, rack-scale systems, and datacenters.
What’s the problem?
A quick glance at a top systems conference shows that most academic systems research is limited to Linux on Ethernet-connected PCs, perhaps with GPUs. Our work risks drifting into irrelevance, given that deployed platforms from phones to datacenters no longer resemble a PC, and networking is rapidly moving beyond commodity Ethernet.
However, most universities cannot get direct access to specialized or experimental hardware, and so are stuck with commodity platforms. When they can get access, it’s often remotely via cloud-like services. This works for running the applications the hardware vendor had in mind, but prevents the low-level experimentation that systems research thrives on.
Even universities with physical access to modern accelerators, server SoCs, NICs, etc. may have no access to crucial documentation for them. For many vendors, low-level programming documentation delivers no clear value to the company, and they may worry about liability. Manuals may be unavailable outside the company, or never exist at all.
Most crucial, though, is that with custom hardware, the key design decisions have already been made – it was designed for specific use-cases, and software research using it must either follow the mind of the hardware designer, or fight a cost-optimized design never intended to do what the researcher is interested in.
Hardware products now drive software research, not vice-versa
This is a problem for computing as a whole, not just academics. The pace of development of hardware now outstrips the ability for systems software (in academia or industry) to evolve. This is a new state of affairs: last century, new hardware would appear slowly and OSes, databases, etc. could be quickly ported to exploit new platform capabilities. Subsequently standardizing on PCs reinforced this, since new PC hardware had to be compatible with existing system software (like Windows or Linux).
Today the balance has changed, and new hardware designs are increasingly constrained by the need for Windows or Linux compatibility. This is bad for both hardware and software innovation: hardware (often unconsciously) is tailored to a Linux or Windows OS, and anything that doesn’t fit a monolithic kernel model is pushed into increasingly bloated device drivers and firmware. Innovating in system software is restricted by the near-impossibility of using the hardware with a non-standard OS, for example.
FPGAs will not, by themselves, save us
The recent popularity of FPGAs as platforms in systems publications is to some extent a response to this situation. In principle, FPGAs offer the flexibility to leapfrog current designs optimized for a given application area (albeit with some performance penalty).
However, to date such work remains constrained by available FPGA platforms, mostly standalone development boards or plugin PCIe accelerators. It’s clear that radically new solutions to application problems can be demonstrated on such boards, but systems design issues like how to securely multiplex or virtualize such functions, how to closely couple them with CPUs at the OS level, etc. remain largely neglected because the hardware makes it difficult to get at these questions.
What can be done?
Stepping back, the root problem here is that systems researchers are trying to re-purpose current, cost-optimized hardware for research into software for future hardware platforms. They do this because, as others have pointed out, simulators are not ideal vehicles for evaluating system software. There was a time when computer science departments regularly built their own computers for both research and general use, rather than buying commodity systems or relying solely on donations from companies.
A computer built for systems software research is potentially very different from one built as a commercial product. Rather than carefully honed to sell well into a set of clear market segments, it tries to cover as large a range of issues in computer systems research as possible.
Since it is not expected to ever sell in volume (there just aren’t that many researchers, after all), minimizing unit production cost is not that important – the margins don’t matter, and it’s best to over-engineer it.
Maximally over-engineering the machine has several benefits: first, it can reduce development cost (due to, paradoxically, conservative design) and development time (since it is racing the commercial hardware). Second, making the design as unconstrained as possible maximizes the range of research use-cases. Finally, over-engineered designs typically have redundancy that can be used for instrumentation, measurement, and support for experiments.
Universities stopped building complete operational systems because it became too complex and too expensive to design and fabricate complex circuit boards running at high clock speeds. However, advances in CAD tools, simulators, and the like have made design easier, and an ecosystem of design and fabrication houses has arisen to produce low-volume systems. It is now possible and affordable for a research group to build their own server-class computer.
Example: Enzian
One example of such a research machine is Enzian, a computer we’re building at ETH, tailored to our research focus (OSes, “Big Data”, systems for machine learning, and networking). Enzian closely couples a server-class SoC with a big FPGA. A finished Enzian system will look like this:
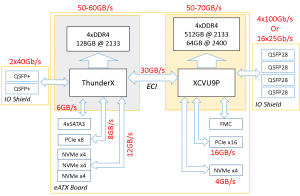
Two factors make Enzian unique for us: first, it is *balanced*: both the CPU and FPGA have ample network and I/O bandwidth, and plenty of DRAM. Second, the two main chips are closely coupled using the processor’s native cache coherence protocol. The FPGA is a full participant in the coherency protocol: it can present any view of memory to the CPU’s last-level cache, and send any coherency message desired at any time.
A single machine like this can be used for all kinds of research: smart NICs, custom DRAM or NVRAM controllers, accelerator design, cache profiling, etc. However, a bunch of them together are building blocks for a cluster or large loosely-coupled multiprocessor, for example by extending memory access to a fabric via the FPGA.
With help from Cavium and Xilinx, we built two working Enzian prototypes using development systems connected by adapter boards we designed and built ourselves; the full single-board design is outsourced to a board house in Germany.
Sharing research platforms
Research platforms like Enzian will fail unless they are widely available. Consequently, it’s important to align them with open source (both hardware and software), and build communities around them that share implementations, experiment, and best practices (as the NetFPGA research platform showed).
Such platforms are challenging to build and use, but this is also an educational boon to research students (we have all learned a lot from the project so far) and a further source of research problems to investigate. The effort involved, collectively, is surely outweighed by the resulting freedom to explore the hardware and software design space. It’s time for computer scientists to start building their own computers again.
About the Author: Timothy (Mothy) Roscoe is a professor in the Systems Group of the Department of Computer Science at ETH Zurich. He works on operating systems, netwoking, distributed systems, and recently (somewhat to his surprise) experimental computer hardware.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
