Graphs have long been treated as a challenging data type in the system and architecture community, due to excessive random accesses from the irregular graph structures and significant load imbalance from the power-law degree distribution. Beyond traditional graph analytics such as PageRank and single-source shortest path, graph mining (this is actually a slight abuse of terminology, which we will re-visit at the end of this article) is an emerging problem that locates all the subgraphs isomorphic to the given pattern of interest. These subgraphs are called the embeddings of the pattern in the input graph. The key capability of graph mining is to discover rich structural information, such as cliques, motifs, and other application-specific patterns, which offers critical insights in many important applications. For example, bio/chem-informatics discovers 3D motifs in proteins, genes, and chemical compounds; social science identifies dense cliques among groups of people through social network connections; and spam/fraud detection matches specific abnormal patterns of communication and financial relationship.
However, despite its powerful capabilities, graph mining is fundamentally much more compute- and memory-intensive than traditional graph algorithms, resulting in poor scalability. Due to combinatorial explosion, the set of possible patterns and the number of embeddings for each pattern grow super-linearly or even exponentially with the input graph size. Even a moderately large graph with few thousands of edges may generate several millions of intermediate embeddings. Such difficulties have been driving the recent algorithm evolution and hardware acceleration of graph mining.
Algorithm evolution shifts hardware acceleration
One particularly interesting thing about graph mining is how the quickly evolving algorithms guided and shifted the focus of corresponding hardware supports. Different from other domains (e.g., deep learning) with relatively mature algorithms and stable sets of kernels, for graph mining it is still unclear whether the algorithms have converged onto one most optimized mainstream. The current computational complexity and memory footprint are still so high, that a new algorithmic breakthrough could possibly contribute several orders of magnitude speedup on par with or even exceeding the benefits from hardware acceleration. This leads to an unusual scenario: more optimized algorithm paradigms constantly emerge not too long after the previous state-of-the-art, making the just proposed hardware design based on the old model even slower than the software implementation of the new one!
Indeed, starting from Arabesque in 2015, many early general-purpose graph mining frameworks adopted a “think-like-an-embedding” programming model that was inspired by the classic “think-like-a-vertex” model. This paradigm, which gradually extended more edges to the intermediate candidate subgraphs at each iteration until generating all embeddings as shown in the figure below, has been followed by many distributed frameworks with further optimizations. For example, G-Miner used task-based asynchronous execution. Fractal proposed a depth-first (DFS) strategy for subgraph enumeration instead of breadth-first (BFS) in Arabesque to reduce memory footprints. And aDFS further used an almost-DFS exploration that combined the benefits of both DFS and BFS. GRAMER, the first hardware accelerator for graph mining, was based on this programming paradigm, and showed significant speedup over the above software systems.
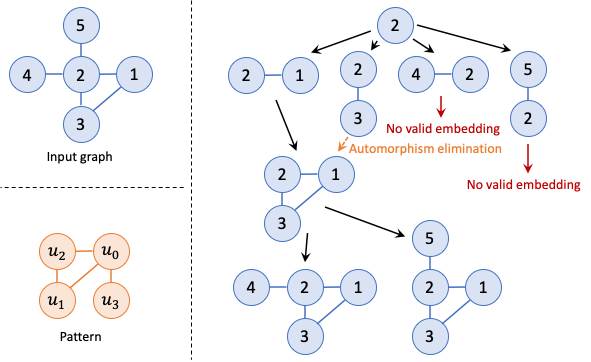
Matching a tailed triangle pattern (left bottom) in the input graph (left top). With “think-like-an-embedding”, the (partial) embeddings are the primary objects. Each iteration extend one vertex to the partial embeddings, resulting in a tree-like exploration where multiple branches represent difference choices of the newly added vertex (right). E.g., in the left most path, u0 maps to 2, u1 maps to 1, u2 maps to 3, and u3 maps to 4. The tree can be explored in either depth-first or breadth-first order.
On the other hand, some systems (e.g., BiGJoin and RStream in 2018 and Mhedhbi and Salihoglu in 2019) modeled graph mining problems as data-parallel dataflow computations, specifically as multi-way joins on the input graph edge list. They demonstrated that worst-case optimal join (WCOJ) algorithms could be a robust and efficient implementation choice. Subsequently, soon after this model was studied in software, hardware people followed up with the TrieJax architecture.
Unfortunately, neither of the two paradigms was the best. In 2019, the seminal work of AutoMine represented graph mining tasks through set intersect and subtract operations, and used a custom compiler to generate highly efficient execution plans specifically tailored to the given pattern. With further optimizations such as symmetric breaking and search order scheduling in GraphZero and GraphPi, such a pattern-aware paradigm was able to almost match the performance of specifically designed, highly optimized algorithms. Probably the most unexpected thing is that even the software implementation of the set-based paradigm was able to outperform the hardware-accelerated design of the “think-like-an-embedding” model, making it a clear winner. No surprise, hardware researchers shifted their interests once again, and produced another breed of architectures, such as FlexMiner as a standalone accelerator, IntersectX as an ISA extension to general-purpose processors, and SISA as a processing-in-memory design.
What we can do with such uncertainty
Still, no one really knows whether the set-based paradigm is the final destiny for graph mining. Nevertheless, as hardware architects, as long as we understand the intrinsic bottlenecks that are agnostic to concrete algorithm variants, we can always trust in those classic design principles taught in our architecture classes (e.g., parallelization, pipelining, amortization, and more), and quickly apply them to design accelerators for any newly emerging model.
So what are the fundamental challenges for graph mining, and what basic principles can be leveraged? First, the most distinguished characteristic of graphs is the random memory accesses to the large off-chip data. The resultant long stalls cause underutilization of compute resources. To address this problem, we could take inspirations from classic architectures, for instance, multi-threading processors and GPUs. While directly reducing the stalls is difficult, we can instead expose sufficient number of independent tasks that execute on the same hardware unit in a time-shared fashion, thus tolerating long memory latencies and improving resource utilization.
Second, graph mining workloads usually exhibit simple computations but heavy controls and data managements. For example, we mostly do only integer comparisons among vertex IDs to realize embedding extension, multi-way join, or set intersect/subtract. However, we also need large on-chip caches/buffers and complex control logic (e.g., the set-based paradigm needs a stack to manage the search over a tree-structure execution plan). This observation allows for an efficient way to improve performance, i.e., using vector-style processing that amortizes the control and data management overheads over multiple lanes of processing units.
Third, real-world graphs with power-law distributions may also result in load imbalance, which challenges the effectiveness of simple parallelization approaches. One potential solution would be to reveal multiple levels of parallelism, so that even if one level exhibits imbalance, the other levels can still work sufficiently well. This is analogous to the debate of one beefy core vs. many wimpy cores: when the application is not well parallelized into multiple threads, you still need a powerful out-of-order core with high single-thread performance, which instead exploits the instruction-level parallelism within each thread.
Actually, the above philosophies lead towards a common insight of exploiting multiple levels of fine-grained parallelism in graph mining. One example along this approach is our recent work FINGERS, which uses a pseudo-DFS order to expose enough independent tasks to well utilize resources, and computes the set operations in parallel with vectorized units.
Future directions
In fact, the term of graph mining has been sometimes misused. A more strict definition of it involves both discovering relevant (e.g., frequently occurring) patterns and locating corresponding embeddings, while graph pattern matching takes given patterns and only does the second part. Most hardware designs today focus primarily on pattern matching, and still lack direct support to efficiently discover patterns, which is challenging due to much more intermediate states to maintain. Another promising algorithm trend is approximate graph mining, e.g., ASAP, which probabilistically samples embeddings with carefully bounded errors. Approximate sampling also offers significant speedup, and could become another optimization direction besides algorithm and hardware. Finally, given the increasingly diverse set of applications on graph data, it would be interesting to consider whether we can have a unified architecture to simultaneously support traditional graph analytics, graph mining, and even other new artificial intelligence algorithms like graph neural networks and knowledge graphs.
About the Author: Mingyu Gao is an assistant professor at the Institute for Interdisciplinary Information Sciences (IIIS) at Tsinghua University. His research interests lie in the fields of computer architecture and systems, including efficient memory architectures, scalable acceleration for data processing, and hardware security.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
