
At its core, all engineering is science optimized (or perverted) by economics. As academics in computer science and engineering, we have a symbiotic relationship with industry. Still, it is often necessary for us to peel back the marketing noise and understand precisely what companies are building, why their offering is better than their competitors, and how we can innovate beyond what industrial state-of-the-art provides. The more immediately relevant a problem is, the more funding and innovation the solutions will receive, at the cost of increased noise for both customers deciding where to place investments and researchers attempting to innovate without bias. In 2021, the raging machine learning accelerator war is now a well-established battleground of processors, ideas, and noise.
MLPerf Benchmarking
One solution to help remove noise from the situation is MLPerf which provides a SPEC-like benchmark suite that we hope will eventually provide clarity on the best-performing machine learning systems. However, many companies do not submit results or spend less time optimizing for the benchmark suite. It makes less economic sense for smaller companies to devote resources to make MLPerf fast over providing value to their customer’s immediate concerns. This situation poses another interesting question: In the coming age of customized accelerators, do standardized benchmark suites make sense at all anymore? Broadly, this is likely to be a challenge, but in the context of GEMM-heavy machine learning workloads, we think standardization is both possible and necessary. After all, the workloads in MLPerf (and networks used by real customers) have far more in common than the diverse set of applications run on CPUs represented in SPEC CPU.
It is also difficult for smaller companies to invest the time and resources required to tune Machine Learning (ML) hyperparameters for large batch-size training. While having competitors release their parameters ahead of the submission deadline is a good way to mitigate this, larger companies still have a competitive advantage in benchmark tuning. In addition, the current focus of MLPerf training is on raw training time, which does not account for cost, energy consumption, and area which are all practical concerns to both customers and academics. MLPerf has recently started collecting power numbers for inference, and we are hopeful that training will eventually follow suit. However, in the current climate, academics are left with limited access to the hardware new companies produce or standardized results on a particular benchmark suite, so how much can be gained by looking at public technical information?
Chip-to-Chip Comparison
In the interest of performing an unbiased comparison of competing ML training hardware, co-author Mahmoud Khairy set out to dig through public documentation and perform an apples-to-apples comparison of 16-bit mixed-precision training. In terms of raw metrics and achievable efficiency, Table 1 details a chip-to-chip comparison between recent products from four leading ML training hardware competitors: Google, NVIDIA, Cerebras, and GraphCore.
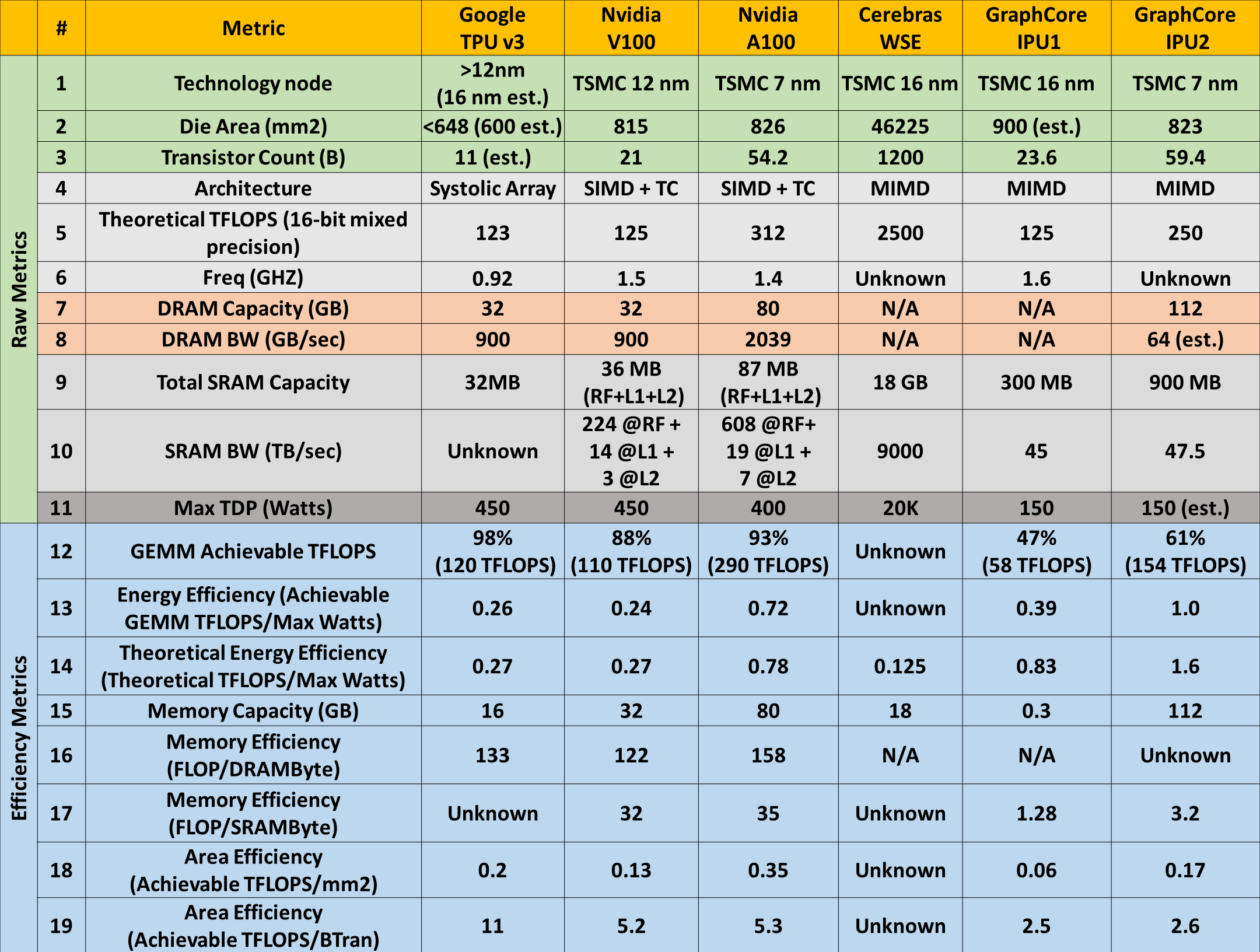
Figure 1: Chip-to-chip comparison between competing ML hardware vendors.
To understand how each chip might gain an advantage over the others, we explore these numbers in the context of different machine learning scaling methods.
Data Parallelism
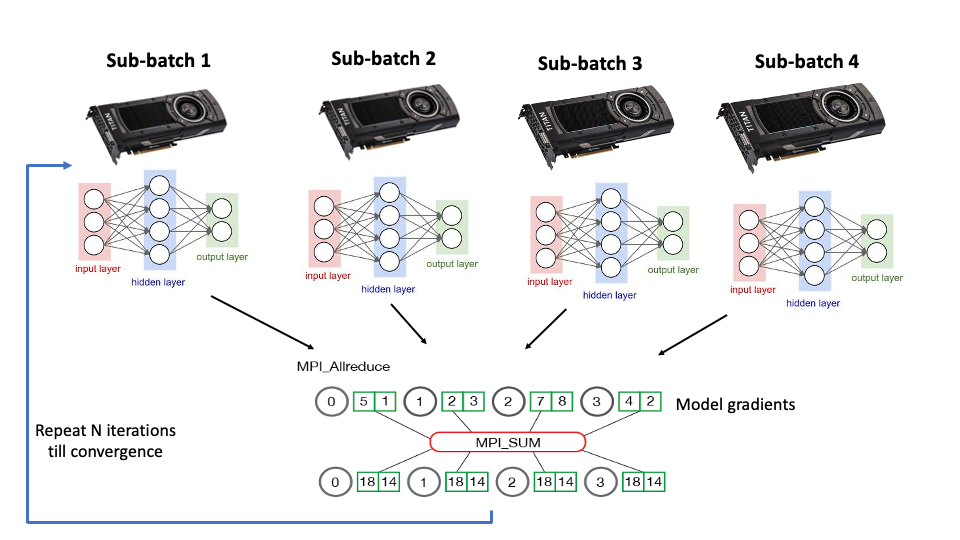
Figure 2: A graphical representation of neural network data parallelism across discrete GPUs
Generally, both NVIDIA and Google rely on data parallelism to scale performance. In this context, data parallelism refers to replicating the network model on different accelerators and assigning a fraction of each training batch to each node (Figure 2). The relatively large DRAM capacity of the TPU and GPU makes network replication feasible, and the dedicated hardware for dense GEMM operations make large batch training efficient. Both vendors have also invested significant effort in making the reduction operation across nodes as efficient as possible. However, the key to exploiting data parallelism is achieving efficient training with a large batch size, which requires a non-trivial amount of hyper-parameter tuning.
Model Parallelism
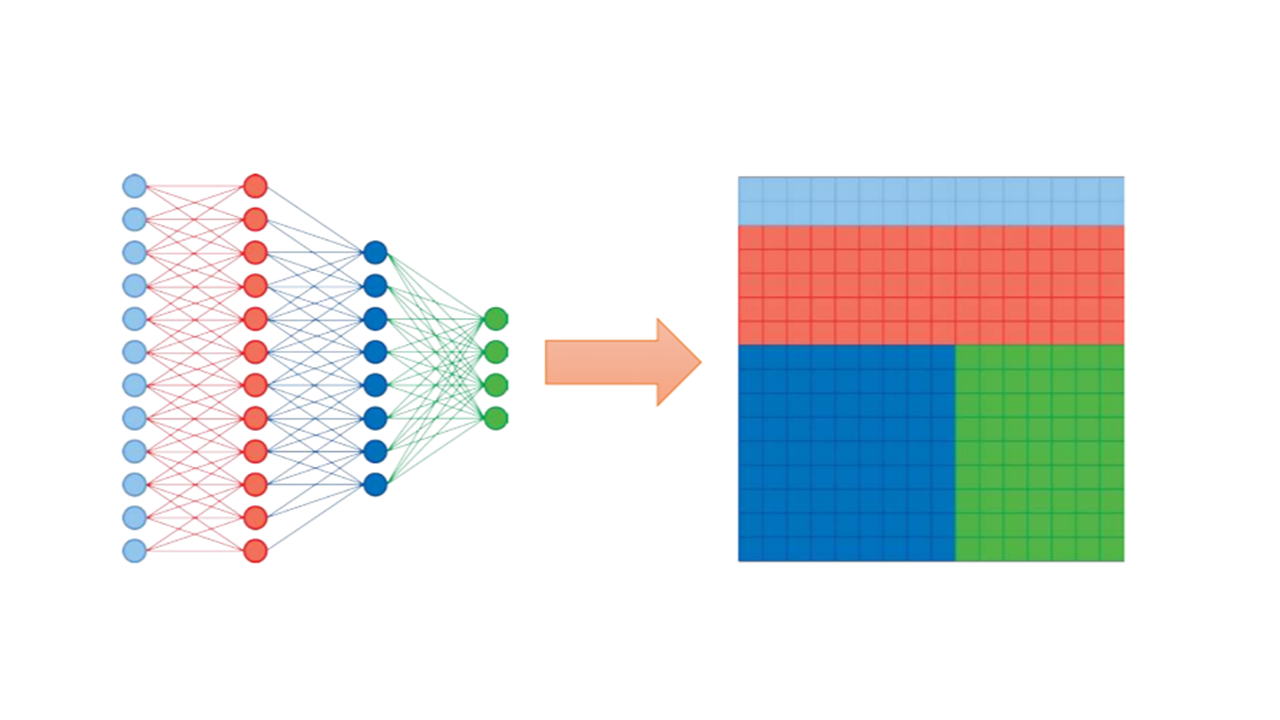
Figure 3: Model Parallelism on Cerebras’ Wafer-Scale Engine
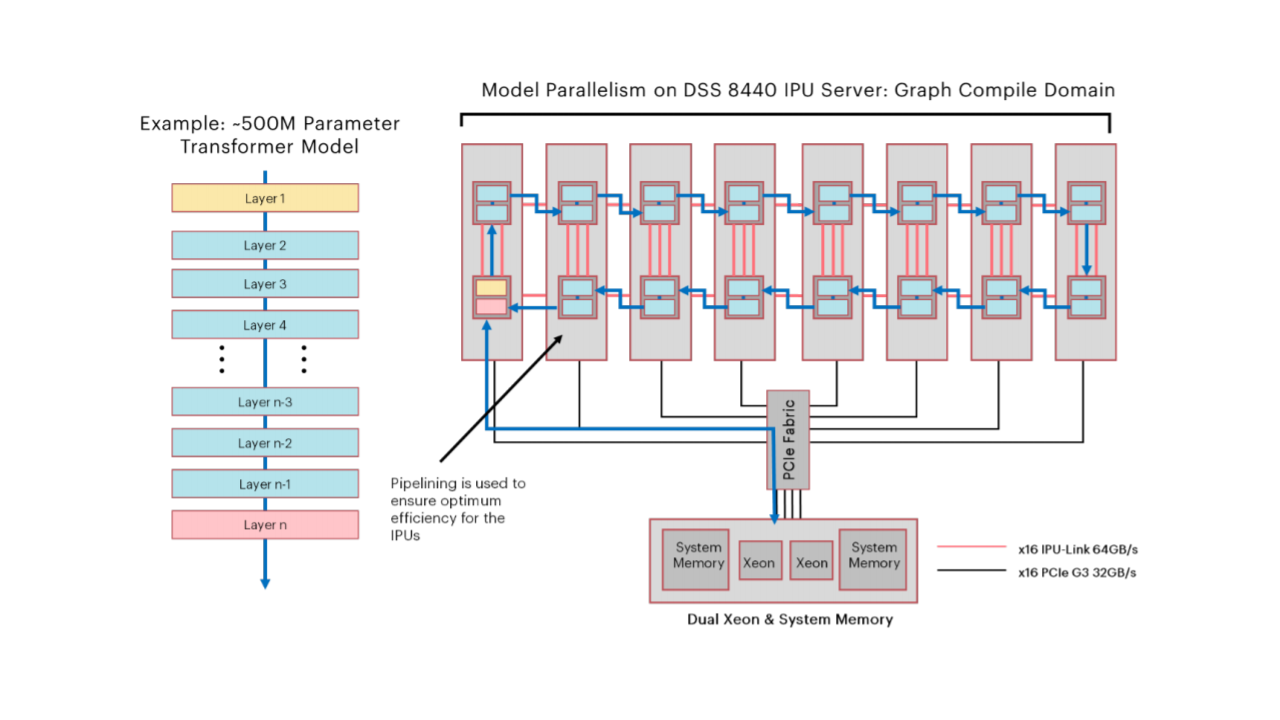
Figure 4: Model Parallelism on Graphcore’s interconnected IPUs
Figures 3 and 4 show that Cerebras and Graphcore take a different approach, focusing heavily on model parallelism. In model parallelism, each layer of a single model is mapped to hardware, and data flows between each layer, ideally to processing units on the same chip. To exploit this philosophy, both Graphcore and Cerebras devote a large portion of their silicon area to SRAM cells such that large models are placed entirely in SRAM. Cerebras achieves this with its wafer-scale chip, while Graphcore’s IPU servers consist of smaller chips linked via a ring interconnect. Of course, GPUs and TPUs can also exploit model parallelism, and Cerebras/Graphcore (particularly the IPU-v2) servers can exploit data parallelism. However, each offering has a particular type of parallelism where its design has an advantage. It seems that one open question academics can help answer is what the right balance between model and data parallelism should be. Data parallelism is difficult to scale, and excessive hyperparameter tuning gives a clear advantage to more prominent players with the time and resources to tune them. In contrast, model parallelism requires less tuning, but as soon as the model no longer fits on-chip or on-node, most of the advantages are lost. Vendors seem to be coalescing around a hybrid solution, but where will the sweet spot be in the machine learning solutions of the future?
Compute Efficiency
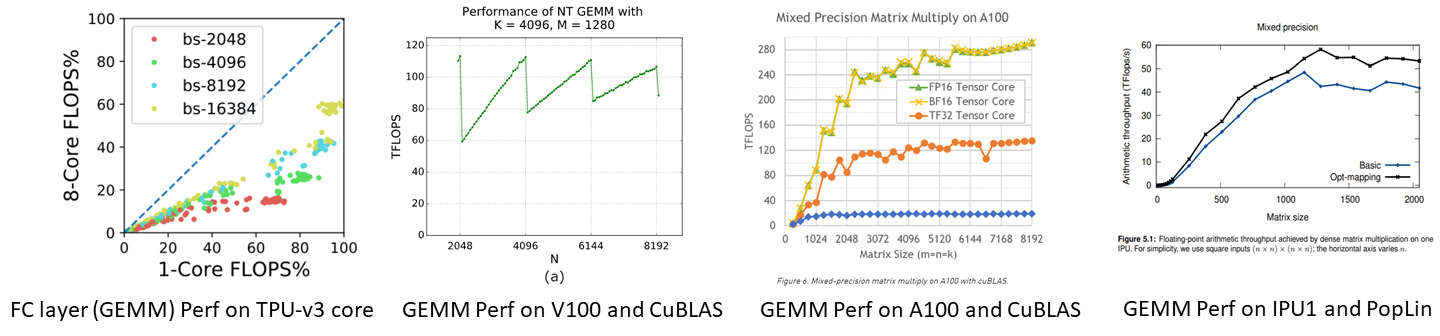
Figure 5: Achievable GEMM performance using optimized libraries on the TPU, V100, A100, and IPU-v1
Another set of metrics derived from public information are the effective FLOPs that 16-bit mixed-precision GEMMs can achieve in each respective system, shown in Figure 5, corresponding to row 12 in Table 1. We obtain these results without running any tests ourselves, relying on results published by vendors and other public sources. The clear winner in overall efficiency is the TPU. Its systolic nature is particularly well suited to dense GEMMs. NVIDIA’s GPUs are not far behind. The A100 can reach 93% of its theoretical peak when the matrix fits evenly within the GPU’s SMs. For Cerebras, there just isn’t enough public information to determine its achievable performance, and for Graphcore, the public information indicates it’s fairly far off its theoretical peak. Another metric of interest is the relative energy efficiency of the TPU versus recent GPUs. Although the ISCA 2017 TPU paper cites an order of magnitude energy efficiency gain for TPUs, rows 13 and 14 indicate that this gap has narrowed for training on more recent silicon, with the GPU rivaling the TPU. Some of this has to do with the GPU’s better technology node, but the addition of tensor cores and other architectural enhancements have made GPUs more effective at executing dense GEMMs.
As MLPerf recognizes, a heads-up chip-to-chip comparison does not tell the whole story or even a practical one. At-scale ML training today is performed with multi-chip servers scaled into a multi-server datacenter. For brevity, we will not include heads-up server-to-server and rack-to-rack comparisons from each company here. We encourage the reader to view the full article for additional analysis and speculation at scale. This post will focus on just one aspect we can extract from the public MLPerf results: performance scaling.
Performance Scaling
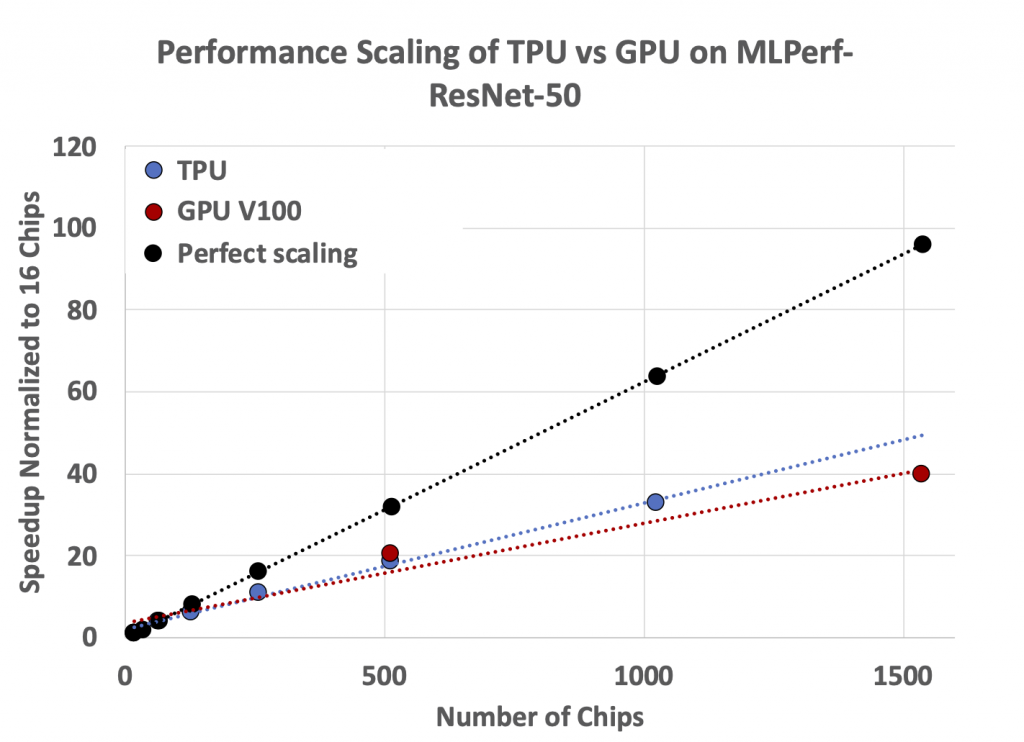
Figure 6: TPU and GPU performance scaling on ResNet as reported in MLPerf 0.6
![]()
Figure 7: TPU and GPU performance on MLPerf-Transformer 0.6
Since each company typically submits multiple results using different sized systems for the same network, we can ascertain just how well the performance of each design is scaling with more chips. Figures 6 and 7 plot these numbers for GPU and TPU entries from NVIDIA and Google in MLPerf 0.6. We highlight the data from MLPerf 0.6 here since it contains more data points than the latest MLPerf 1.0 results, but the scaling trends for 1.0 remain similar.
We note that the MLPerf results include an evaluation run every epoch, which researchers do not do in practice and make the scaling results worse for both machines. Even accounting for this slowdown, the scaling results are not great for either device, particularly on the transformer workload. The lack of scaling on these workloads comes from 2 factors: (1) the cost of communication grows as more chips are involved and (2) after 128 chips, the batch size is fixed, resulting in less work per chip. Scaling the batch size while maintaining accuracy (a hard requirement in MLPerf) ultimately limits performance scalability. It is worth mentioning that Google’s production workloads scale much better than the MLPerf benchmarks. This raises some concerns about how well MLPerf applications represent real-world workloads with large inputs.
Open Questions
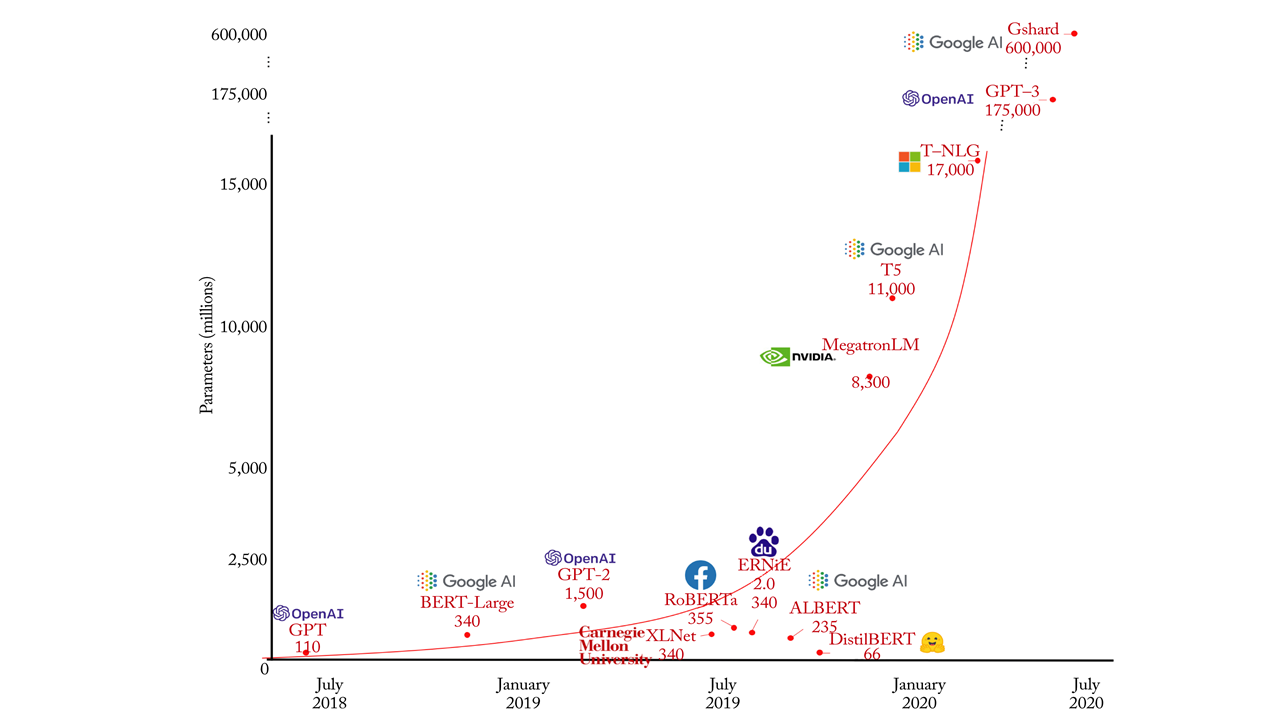
Figure 8: Number of Parameters in recent NLP Models
So, are there any conclusions we can draw from all this? The intent of this post is not to predict the war’s winner but rather predict what weapons will turn the tide. Academically, the data versus model parallelism tradeoff is interesting. If models continue to grow (Figure 8), exploiting model parallelism on the same chip, wafer-scale or not, will be infeasible. Conversely, increasing the batch size to exploit data parallelism is difficult, and larger models won’t make this easier. It seems that a hybrid approach will be the solution, and hardware that can effectively adapt to different model/data parallelism levels will likely have the most impact. Finding the right area mix between compute and on-chip storage is directly related to this point and software’s ability to achieve a high fraction of the hardware’s peak performance.
In addition to the concrete design questions we can ask, there is a larger meta-point that this exercise highlights. How do we fairly judge the ideas and innovations of new products in a fast-moving, highly competitive field where critical information is often unknown? In an ideal world, non-biased community and academic efforts like MLCommons are the best that we can do. However, removing all bias from these suites is unlikely. Moreover, by their very nature, these suites will be a step behind state-of-the-art models and lack results for hardware whose companies don’t have the resources to invest in making the benchmark look good. So, in addition to MLCommons, we think academics should be running a speculative side-hustle on any information we can get our hands-on. Although by no means complete (the inference landscape is even wilder), the analysis we performed here certainly helped us put the space into better context, even without full MLPerf results.
Finally, we note that this blog post represents an academic’s view at a particular moment in time. Some of the information here may be wrong or taken out of context as we relied on both biased company sources and neutral sources without internal details. Without a completely open and fair way to compare solutions, the analysis itself adds more noise. Still, it represents honest detective work in trying to compare devices with imperfect information. In many ways, we should embrace this wild west of information, as it is indicative of a field in flux and, at least in our opinion, nothing is better for innovation than the chaos that this kind of change brings.
About the Authors:
Tim Rogers is an assistant professor in the Elmore Family School of Electrical and Computer Engineering at Purdue University.
Mahmoud Khairy is a Ph.D. student in the Elmore Family School of Electrical and Computer Engineering at Purdue University.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
