
The rise of open-source software necessitated a software-engineering revolution (new standards, tools, licenses, etc.) to overcome the problems facing large distributed teams working on enormous code bases. Today, machine learning (ML) builds atop this vibrant and creative open-source ecosystem and toolchain – leading frameworks such as TensorFlow, PyTorch and Keras are open and boast thousands of contributors around the globe. But ML is utterly unlike explicitly written software and relies heavily on data to implicitly define program behavior. Shifting the importance from explicit code to data introduces an even more significant and challenging problem: too little data.
A whole new set of engineering challenges is emerging as massive data sets become vital to creating ML applications. We have yet to figure out all the tools, practices and patterns to handle billions of training examples in a large system effectively. We believe it will require a whole new discipline: data engineering.
Data engineering is not new; it’s a fast-growing IT area, boasting 50% year-over-year job growth thanks to the insatiable need for data to train ML models. A typical data engineer aids in creating data sets to train high-quality models, while data scientists handle the analytics—that is, the art of transforming the data into information. Data engineers are behind the scenes architecting, building, managing and operating the data-creation pipelines that set the stage for data scientists. As ML becomes more common, the appetite for data will grow more ravenous. It requires more data than data engineers can readily produce, presenting a challenge for ML deployment.
Although an operating system like Linux can operate by itself, an image classifier such as ResNet is a mere curiosity unless it incorporates training data. ML solutions must combine software and data with data fueling the software. The ML community does build data sets, but this endeavor is often artisanal—painstaking and expensive. We lack the high productivity and efficient tools to make building data sets easier, cheaper and more repeatable. Constructing a data set today is akin to programming before the era of compilers, libraries and other tools. So, the question is whether we can accelerate data-set creation by democratizing data engineering—that is, building computer systems (“architectures”) that can automatically produce training data cheaply and efficiently.
Open Data Sets
Data sets are often the domain of large organizations with billions of users due to their proprietary nature, licensing and privacy issues. These data sets are often inaccessible to individual developers, researchers and students, impeding progress, and this leads us to ask a fundamental question. What if we could enable the rapid development of open data sets, akin to how the community has enabled the rapid development of open-source software?
Many of the most influential data sets are open. ImageNet (first released in 2009) fueled image classification with its corpus of 14 million images. MS-COCO (first released in 2014) provides 1.5 million object instances to enable object-detection research. SQuAD (first released in 2016) helped stimulate natural-language-processing (NLP) research by offering a reading-comprehension data set containing more than 100,000 questions. These examples helped spark the ML revolution, which led to a hardware and software renaissance that unlocked amazing new applications.
To assess the impact of open-source data sets we look at how the industry has benefited from them. Specifically, we looked at ML-research publications from Facebook AI Research (FAIR), Google AI and Microsoft AI in all relevant areas, such as computer vision and NLP. We consider publications at all venues, such as ICLR, ICML, NeurIPS and CVPR. If a paper used a data set, we conducted a search to determine whether the data set is open access (e.g., whether it has a GitHub repository or a dedicated download web page). If so, we count it as using an open data set.
Our analysis includes nearly 2,000 papers from the three organizations mentioned above, published between 2015 and the end of 2020 (i.e., post-AlexNet). Figure 1 summarizes our main findings. We determined that a staggering 78.3% of industry research publications employ open data sets to publicize their research findings to the broader community. Only 21.7% of the papers used proprietary data sets, not available to the general public.
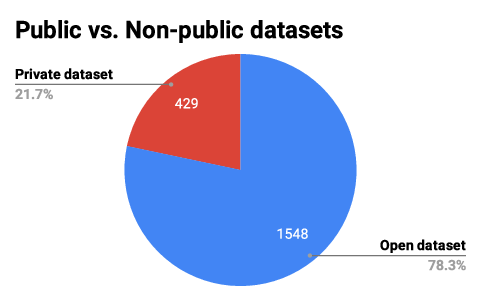
Figure 1: Percentage of ML research papers that rely on open versus nonpublic data sets.
Figure 2 breaks the data down by company; our findings remain consistent. All three organizations rely heavily on open data sets. Interestingly, the use of open data sets is increasing. This data is not shown, please refer to our MLCommons data engineering whitepaper for more analysis where we breakdown the results by year.
Leading researchers use open data sets for various reasons. The most obvious is simply accessibility. Open data sets are publicly hosted. They are free to use. Moreover, they have a broad audience. Hence, they are often the gold standard for verifiability and result reproducibility. Bootstrapping ML research, therefore, becomes quick and easy. Over time, these data sets provide a common platform for assessing ML innovation.
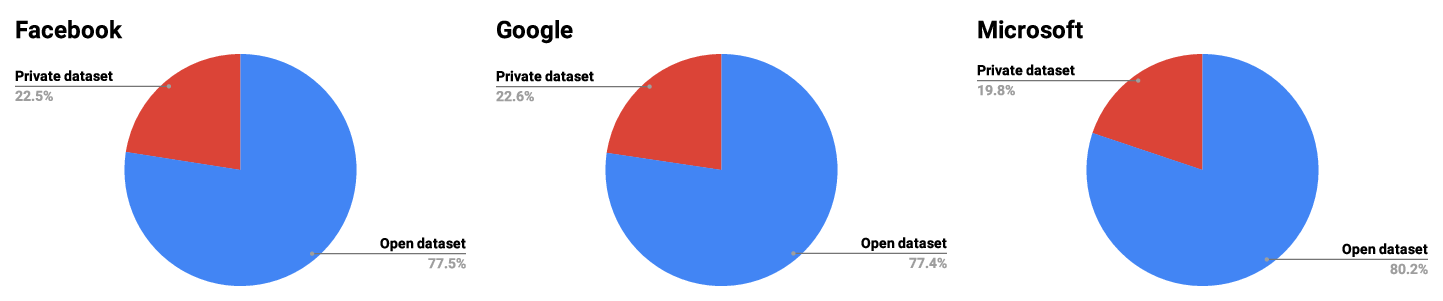
Figure 2: Breakdown of ML research papers at three organizations over recent years.
Data Engineering
Given the obvious benefits of open-source data sets, the question we face is as follows: are the data-engineering practices that we’ve followed thus far sufficient to fuel the future creation of more open-source data sets?
Researchers have been working with large ML data sets for decades, but in many cases, that work has been a sideline for exploring architectural or algorithmic problems. Engineering is about producing repeatable techniques that we can share and yield superior results quicker and more cost-effectively than artisanal approaches. Only in the last few years has data-set creation employed this kind of systematic approach.
The development of ImageNet, MovieLens, DeepSpeech, CheXpert and other well-known data sets is revealing; an especially illustrative example is ImageNet, developed by graduate students who lacked the resources to solve a seemingly insurmountable problem. Around 2005, researchers at Princeton attempted to manually find 100 images for each of the 1.5 million words in WordNet. But they estimated the project would take practically forever.
Over the next several years, a few computer-vision researchers considered how they could perform the task more efficiently. Using exclusively open-source technologies such as the Internet, information retrieval, computer-aided design, and computer vision, these researchers labeled about 10 million images on a budget of less than $40,000. In doing so, they kicked off the deep-learning revolution, which paved the way for AI’s widespread adoption.
Despite this fantastic success, we have forgotten the lesson of these data-engineering pioneers. Small groups produced high-value data sets using only 2005-era workstations. They did so by employing technologies that dramatically increased their productivity. ImageNet used Internet-search technology to expand WordNet into a custom web crawler. One student could reason about the space of interesting images and locate them across the Internet with a single query. Specially designed processes could label hundreds of images at once for just a few cents. Semi-supervised learning algorithms focused the limited labeling capacity on the most promising areas.
Today, despite vast software infrastructure (most of which is open source) for developing models like AlexNet, practically nothing is available for building open data sets like ImageNet. When running on Nvidia’s A100 or another optimized AI chip, deep-learning frameworks such as TensorFlow and PyTorch make the old AlexNet look ancient. But the technologies that the ImageNet creators employed are still bleeding edge compared with the resource-intensive human labeling pipelines that frequently serve in the industry. Can we improve the state-of-the-art?
A Call to Action
The community must now document the real-world data-set creation process to spot patterns and curate techniques, and build systems that efficiently generate data sets. This task is especially hard for academic researchers, who rely on others to create data sets. Efforts to overcome that difficulty have included identifying areas for which improved training data can have a big impact; speech is one example.
MLCommons, a community-driven ML-systems non-profit, driven to accelerate machine learning innovation to benefit everyone, is working on computer systems that can automatically produce training data cheaply and efficiently at two ends of the speech spectrum: training complex speech models and tiny keyword models.
![]()
The “People’s Speech” effort in MLCommons focuses on building a speech data set that is 100x bigger than any other available publicly. Ample public-domain speech data is on the Internet, but the task of labeling it manually has a projected price tag of $10 million. Drawing inspiration from ImageNet, we use technology to make our labelers more productive by leveraging existing compute and ML tools. As one example, we use a generative text model to create a novel text corpus that captures a vast vocabulary. We then vocalize this text data using an ML-based speech synthesis system to construct explicitly labeled speech examples. Using this approach and other techniques, we’ve collected and labeled 85,000 hours of new data within $20,000.
The “1000 Words in 1000 Languages” project focuses on speech diversity by automating the construction of custom speech-command data sets (e.g., spoken keywords such as “Alexa”) for ML-enabled IoT devices to meet the global population’s diverse needs at the end-point. The goal is to provide limited vocabulary models for the “long-tail,” or less frequently localized languages. Using open data sets such as Common Voice and the open-source DeepSpeech model, we are building a data-engineering pipeline that can take any recorded speech and automatically generate per-word timing clips that we can then use to train keyword-spotting models automatically. Usually, humans generate these clips manually—a costly and time-consuming task. Instead, we chose the Speech-to-Text APIs to automatically extract this timing information, greatly expanding the number of words we cover at a minimal cost.
Many challenges remain in open-source data engineering. Some involve defining the metrics for assessing the data sets that automatically emerge from these pipelines. Example metrics include licensing, size, quality, diversity, and ethical considerations. Industrial users, for instance, require licenses for commercial use. The rise of common licenses such as CC-BY and CC-0 has helped, similar to how BSD and Apache2 have aided open-source software. But efficiently locating and verifying licenses for millions of training-data samples remains problematic. Another emerging area is ethics. For example, even if a picture is freely available on the Internet under CC-0 or another permissive license, its owner may object to its use in improving face-identification systems for mass surveillance.
The People’s Speech and 1000 Words in 1000 Languages projects are community-driven efforts to increase data-engineering efficiency. We hope they’ll be arenas for testing and improving novel data-engineering systems and ideas. Additional details can be found here. We welcome the community’s input and assistance in democratizing data engineering. Students, researchers, enthusiasts and organizations are all welcome. Academia can help directly by faculty and students’ involvement in our projects and broadly by emphasizing data engineering in the curriculum. Programs in data engineering are less prevalent than those in data science and many students do not realize that there are a large number of jobs in this area. Join our effort at MLCommons.
Five years from now, imagine a world where we assess not how well a system performs AI tasks but how well the computer system performs at processing raw data to generate practical, verifiable data sets for training ML models.
Join the MLCommons dataset working group effort here!
About the Authors:
Vijay Janapa Reddi is an Associate Professor at Harvard University and a founding member of MLCommons. He serves on the MLCommons board of directors and oversees the MLCommons Research group as Co-Chair. He previously served as the MLPerf Inference Co-chair and currently oversees the development of the tinyMLPerf benchmark suite.
Greg Diamos leads transformation engineering at Landing AI. He is the MLCommons Data-Sets Chair and is a founding member of MLCommons.
Pete Warden is Technical Lead of TensorFlow Mobile and Embedded at Google.
Peter Mattson leads ML Metrics at Google. He is the General Chair and co-founder of MLPerf, and President and founding member of MLCommons.
David Kanter is the Executive Director of MLCommons. He is also a founding member of MLCommons, and previously served as Power chair and Inference co-chair for MLPerf.
Acknowledgements: We are grateful to Zishen Wan for helping us with collecting the data that was assimilated into the graphs presented.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
