
I. Why a New Embedded Benchmark
The world will soon be deluged by tens of billions or even hundreds of billions of Internet of Things (IoT) devices, but we still don’t have a high quality, widely reported benchmark to fairly evaluate the embedded computers that power them. It’s way past time to fix this predicament, and we need your help to do so (see Section V).
II. Creating a New Benchmark
A small group of academics and practitioners began meeting in January 2019 to hash out the skeleton of a potential solution. We call it “Embench”, which stands for embedded benchmark. The people involved so far are Jeremy Bennett of Embecosm, Palmer Dabbelt of SiFive, Cesare Garlati of Hex Five Security, G. S. Madhusudan of the India Institute of Technology Madras, Trevor Mudge of the University of Michigan, and David Patterson of the University of California Berkeley.
We first looked at past benchmark efforts (see Table 1) to try to incorporate their good ideas and to avoid their mistakes, and drew the following seven lessons:
- Embench must be free (no cost). If the benchmark is behind a paywall, it’s simply not going to be as widely used. For example, EEMBC has 10 benchmarks behind a paywall, each of which costs thousands of dollars, plus CoreMark. Only the free CoreMark is widely reported. In particular, academics publish frequently and can promote the use of benchmarks, so being free accelerates academic adoption and hence publicizes the benchmarks to the rest of the community.
- Embench must be easy to port and run. If it’s difficult or expensive to port and run, then history and common sense says the benchmark will not be as widely used. Dhrystone, Linpack, and CoreMark are widely reported presumably because they are free and easy to port and run despite not having good reputations as accurate benchmarks.
- Embench must be a suite of real programs. First, a realistic workload is easier to represent as a suite than as a single program. Second, a single program is hard to evolve. Third, real programs are more likely to be representative of important workloads than synthetic ones. Having the benchmark name be associated with a suite of, say, 20 real programs makes it possible to drop the weak ones and add enhancements over time. For example, SPEC CPU since 1989 needed 82 programs over its 6 generations, with 47 (57%) used just one generation and only 6 (7%) lasting three or more.
- Embench must have a supporting organization that maintains its relevance over time. Compilers and hardware change rapidly, so benchmarks need an organization to evolve it. We believe we can set up an Embench committee within an existing organization—such as the Free and Open Source Silicon (FOSSi) Foundation—rather than create a new benchmark organization, as was the case for SPEC and MLPerf.
- Embench must report a single summarizing performance score. If the benchmark doesn’t supply an official single performance score, then it won’t be as widely reported. Even worse, others may supply unofficial summaries that are either misleading or conflicting. Embench will include orthogonal measures, such as code size, and each would have a summarizing score.
- Embench should report geometric mean and standard deviation as the summarizing score. Friends well-grounded in benchmark statistics recommend first calculating the ratios of performance relative to a reference platform and then report the geometric mean (GM) of those ratios along with their geometric standard deviation (GSD). [Mashey, J.R., 2004. War of the benchmark means: time for a truce. ACM SIGARCH Computer Architecture News, 32(4), pp. 1-14.]
- Embench must involve both academia and industry. Academia helps maintain the goals of fair benchmarks for the whole field and industry helps ensure that the suite includes programs that are genuinely important in the real world. We need both communities participating to succeed.
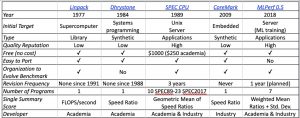
Table 1. Widely reported benchmarks. Single synthetic programs like Dhrystone and CoreMark have long been discouraged from being used as benchmarks and many criticize Linpack. Alas, benchmarks that can be used for embedded computing—such as EEMBC, MiBench, BEEBS, and TACleBench–are not widely reported, presumably because they omit features of these popular ones.
III. What’s Been Done So Far
Once we agreed on the lessons, we next moved to the definition of the benchmark itself: the types of processors to benchmark, the programs of the suite, the reference platform, the metrics, and so on. Keeping the group small allowed rapid iterations and extensive conversations face-to-face to reach a sensible foundation relatively quickly.
Agile Development. We’re following the agile benchmark philosophy of MLPerf. You release a version, and collect experience and feedback before the next more ambitious iteration. The first version we’re releasing publically is 0.5. We expect to go through versions 0.6, 0.7, … until we have refined a version good enough to call Embench 1.0.
Embedded Target. For Embench 0.5, we chose small devices where the flash (ROM) memory is ≤64 KiB and RAM is ≤16 KiB.
Candidate Programs. We expected that the next task of finding 20 solid candidates for a benchmark suite would be difficult. We were pleasantly surprised that past efforts at embedded benchmarks from MiBench, BEEBS, and TACleBench—which unfortunately are not widely quoted—have led to many free programs that are easy to port and run. We chose BEEBS because it was a recent effort that involved both academia and industry and because it already borrowed good programs from MiBench and many others. We tentatively pared it down to about 20. We then discussed the important categories missing from BEEBS and added the best examples of free versions that we could find (see www.embench.org).
Reference Platform. We then moved to the metrics for Embench 0.5. It helps if the reference platform is widely available and well-known. We tentatively chose PULP RI5CY core as the initial reference platform. The use of GM and GSD guarantees consistent results even if we change the reference platform (e.g, to an ARM M0), as happened with the SPEC CPU benchmarks.
Code Size. One unique feature of embedded computing is that code size is critical, since the cost of the memory for the code can be a significant fraction of the cost of IoT device. Thus, we’ll also report geometric mean and standard deviation of code size relative to the reference platform. We believe code size is important for IoT yet novel as part of a formal benchmark.
Context Switching Time. Another difference for embedded computing is the importance of context switch time, as IoT devices may be active running a low priority task but must switch quickly to a higher priority task. For Embench 0.5, we run a small program written in assembly language of the target platform and measure its performance for switching contexts. Again, we think context switch time is necessary for IoT yet novel as part of a formal benchmark.
IV. What’s Left to Do
While we’ve made initial progress, there are still important topics on which we could use some help.
No Interrupt Latency Yet. An important metric related to context switching is interrupt latency, as IoT devices can be idle waiting for an event to trigger them into action. Interrupts will require a lab setup to measure latency. We need volunteers to design and document how to setup and run the interrupt measurements to include it in Embench 0.5.
No Floating Point Yet. We did not include floating-point intensive programs in version 0.5 because of the large impact of having a floating point unit—which can be expensive for IoT chips—on such programs, and because many embedded applications do little or no floating point computations. We’ll consider adding a set of floating-point intensive programs in a later version of Embench, possibly with separate integer and floating-point ratings like SPECCPUint and SPECCPUfp. We need help identifying candidate programs from digital signal processing or scientific computing to be included in a future iteration.
No Power Yet. An interesting metric for IoT that we rejected for Embench 0.5 is power. SPEC does include power in some of its benchmarks, but it comes with a 33-page manual on how to fairly set up and measure power, including restrictions on altitude and room temperature. It will take a while to decide what of that applies to IoT. Also, IoT devices are systems on a chip (SoC) rather than simple microprocessors, so it’s unclear how to get “apples-to-apples” comparisons to fairly calculate performance per watt as SoCs will vary in their complexity beyond the processor and memory. A third reason is that engineers will want to benchmark soft cores, and we can’t measure their power experimentally. Finally, energy efficiency is often highly correlated with performance, so that even if we did all the work to benchmark IoT power, the results might not be enlightening. Volunteers with experience in measuring power could help us decide what if anything to include in future Embench iterations.
V. Conclusion and How You Can Contribute
Our plan is to have Embench 0.5 finalized in time to begin collecting and reporting results before the end of 2019. Given the current sorry state of widely reported benchmarks for embedded computing, we believe Embench—even in the initial 0.5 version—will be helpful to the IoT field.
Given that a small group came up with the bones of Embench, we’re hoping now to expand to include more like-minded parties to flesh it out. We need to see if others agree on our tentative decisions as well help with the pieces that we’re not yet addressed, such as interrupt latency, floating point programs, and possibly power. We hold monthly meetings, and can accomodate remote participants. If you’re interested in helping, send email to info@embench.org.
About the Author: David Patterson is a Berkeley CS professor emeritus, a Google distinguished engineer, and the RISC-V Foundation Vice-Chair. Likely his best known projects are Reduced Instruction Set Computer (RISC), Redundant Array of Inexpensive Disks (RAID), and Network of Workstations (NOW). This work led to about 40 awards for research, teaching, and service plus many papers and seven books. The best known book is Computer Architecture: A Quantitative Approach and the newest is The RISC-V Reader: An Open Architecture Atlas. In 2018 he and John Hennessy shared the ACM A.M Turing Award.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
