
When I worked at Google, fleet-wide profiling revealed that 25-35% of all CPU time was spent just moving bytes around: memcpy, strcmp, copying between user and kernel buffers in network and disk I/O, hidden copy-on-write in soft page faults, checksumming, compressing, decrypting, assembling/disassembling packets and HTML pages, etc. If data movement were faster, more work could be done on the same processors.
Thought Experiment
We look here at a Gedankenexperiment: move 16 bytes per cycle, addressing not just the CPU movement, but also the surrounding system design. We will propose five new general-purpose instructions that are key to meeting this goal.
We assume a base multi-core processor four-way-issue load/store machine with 64-bit integer/address registers Rx, 128-bit (16-byte) data registers Vx, and an L1 D-cache that can do two operations per cycle, each reading or writing an aligned 16-byte memory word. A lesser design cannot possibly move 16 bytes per cycle. This base design can map easily onto many current chips.
Fails
Proposals to do in-DRAM copying fail here because source and data fields are not likely to be aligned, and are unlikely to be in the same memory chip. They also fail if the source or desired destination is somewhere in the cache hierarchy, not DRAM. Proposals to use a specialized DMA engine for movement fail for short moves if that engine has non-trivial setup and has interrupt processing at completion, and fails for long moves if the multiple processors must take out a software lock to use the single engine, causing waits when there is contention (as there will be at 25-35% use per core).
The standard memcpy(dest, src, len) function does not know the subsequent use of the dest field, so can do no better than leave it wherever it lands in the cache hierarchy. We thus eschew non-temporal loads and stores, which assume non-use of dest. (Cache pollution is addressed in a section below.)
Cache Underpinning
To move 16 bytes per cycle, the L1 D-cache must do an aligned 16-byte load and 16 byte store per cycle, while simultaneously doing cache-line refills and writebacks at the same rate, about 50 GB/sec for a 3.2 GHz processor core. Lower levels of cache must support multiple such streams, all the way out to main memory.
Instruction Underpinning
To move 16 bytes per cycle requires at least four instructions per cycle: load, store, test-done, and branch. In reality there is more to do, but modest loop unrolling can fit the rest into four instructions per cycle, as we see below.
Short Moves
We break the discussion onto three parts: short ~10 byte, medium ~100 byte, and long ~1000+ byte moves. Short moves are common in assembling/disassembling packet headers and HTML tags, moving single 1..4-byte UTF-8 characters, and moving small byte strings during compression/decompression. Medium moves are common in juxtaposing paragraphs of text or copying modest-size control blocks. Long moves are common in filling the payload part of packets and in network/disk buffer transfers.
The standard short move code tests that len is small, say < 16, and then does
while (len-- > 0) {*dest++ = *src++;}
compiling into something like
compare, sub, branch, loadbyte, add, storebyte, add
taking at least two cycles per byte, or 32 cycles for 16 bytes, far from our goal of 1 cycle.
We introduce two new instructions to handle the short move case quickly. Chips that can already do unaligned 1/2/4/8/16-byte loads and stores already have all the datapath for these; they just need small modifications to the control logic.
Load Partial
ldp V1, R2, R3
Load and zero extend 0..15 bytes from 0(R2) into V1, length specified by R3<3:0>. Length 0 does no load and takes no traps.
Store Partial
stp V1, R2, R3
Store 0..15 bytes from V1 to 0(R2), length specified by R3<3:0>. Length 0 does no store and takes no traps.
Chips that do unaligned load/store already have logic to decide whether to access one or two cache words, have logic to shift two memory words to align bytes with V1, and logic to zero-extend 1/2/4/8 byte loads. The new instructions just need control logic to detect zero data movement, and control logic to zero-extend 0..15 byte loads.
Using these instructions, memcpy with dest, src, and len already in registers becomes
memcpy:
ldp V1, 0(src), len
stp V1, 0(dest), len
andnot len, 15
bnz medium
return
The first four instructions can issue in a single cycle, moving 0..15 bytes branch-free, close to our goal. If that is the total length, the return takes a second cycle. (This is best-case timing; cache misses, branch mispredicts, and unaligned memory accesses can slow things down modestly.)
Medium Moves
After ldp/stp for 0..15 bytes, the remaining length is a non-zero multiple of 16 bytes. To cover medium moves, we increment src and dst to account for the variable-length ldp/stp and then conditionally move 16, 32, 64, and 128 bytes.
medium:
and Rx, len, 15 ; length (mod 16)
add src, Rx ; increment past the 0..15 bytes
add dest, Rx ; increment past the 0..15 bytes
Conditionally move 16 bytes with ordinary 16-byte load/store and update src/dest; 2 cycles for 16 bytes
and Rx, len, 0x10 ; does length have a 16 bit?
bz 1f
ld ; yes, move 16 bytes
st ; yes, move 16 bytes
add src, src, 16 ; increment past the 16 bytes
add dest, dest, 16 ; increment past the 16 bytes
1:
and Rx, len, 0x20 ; does length have a 32 bit?
...
The same pattern repeats for len bits 0x20/0x40/0x80 moving 32/64/128 bytes via more ld/st pairs between bz and add. These pieces all achieve 16 bytes per cycle best case.
The short plus medium code covers all lengths up to 255 bytes. We finish by testing for len > 255
andnot len, 255
bnz long
return
Long Moves
If len is more than 255 bytes, we end up here with a nonzero multiple of 256 in len<63:8>. For speed, we next want a loop that does only aligned 16-byte loads and aligned 16-byte stores and we unroll that loop modestly to fit the four overhead instructions around the load/store pairs. The loop has a previously-loaded src word, loads a new aligned src word every cycle, shifts two words to align with dest and stores the dest word.
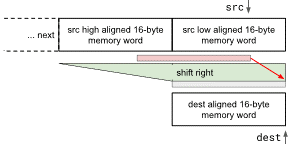
We introduce a new double-width 32-byte shift instruction to handle the alignment quickly. This is the same shift logic already in a chip’s unaligned-load path.
Byte Shift Double
shrbd V1, V2, R3
Shift the register pair V2V3 right by 0..15 bytes, as specified by R3<3:0>. Place the result in V1.
The overall long move uses ldp/stp to advance dest to the next higher multiple of 16, moves chunks of 64 bytes using load/shift/store plus room for the two pointer increments, test, and branch per iteration, fitting into 4 cycles per 64 bytes. 16 bytes per cycle exactly!
After moving multiples of 64 bytes to aligned dest addresses, there will be a tail of 0..63 bytes remaining to move. Use the medium then short patterns to finish up. This overall design comes very close to moving 16 bytes per cycle over the entire range of short, medium, and long memcpy. But we aren’t done yet …
Prefetching
With L3 cache about 40 cycles away from the CPU and main memory 200-250 cycles away, prefetching becomes important for long moves. We can’t do much about getting the initial bytes quickly, but we can prefetch subsequent bytes.
Moving 1KB at 16 bytes/cycle takes 64 cycles. This is enough time while moving 1KB to prefetch the next 1KB from L3 cache. Similarly, moving 4KB takes about 256 cycles, enough time to prefetch the next 4KB from main memory. But today’s computers only prefetch single cache lines, often 64 bytes each.
We introduce two prefetch instructions.
Prefetch_read, Prefetch_write
PRE_R R2, R3
Prefetch data for reading from 0(R2), length min(R3, 4096).
PRE_W R2, R3
Prefetch data for writing from 0(R2), length min(R3, 4096).
The 4KB upper bound on the length is important. It prevents describing a prefetch of megabytes, and it guarantees that the prefetch will need no more than two TLB lookups for 4KB or larger pages. It is big enough to give code time to start subsequent prefetches as needed, pacing prefetching to data use.
The desired implementation of PRE_W does allocation of exclusive cache lines but defers filling them with any data, except possibly partial first and last cache lines. If such a cache line is completely overwritten, the read is never done. Without this optimization, memory bandwidth goes up by 50%
The long move loop can be built as a pair of nested loops, the inner one issuing read and write prefetches and then moving 4KB at a time.
DRAM row access
DRAMs internally copy bits out of very weak capacitors to a row buffer and then serve bytes to a CPU chip from there. Row buffers are typically 1KB. Accessing bytes from an already-filled row buffer is three times faster than starting from scratch, approximately 15ns vs. 45ns. This hasn’t changed much in 40 years.
If an implementation gets a prefetch address and length to the memory controller logic at the beginning of a long prefetch, the memory controller has enough information to optimize doing row-buffer fetches, even in the presence of competing memory requests.
Cache Pollution
Quickly moving many kilobytes of data through the caches normally has the downside of evicting other data belonging to other programs. Cache isolation remains a problem in the datacenter part of our industry.
Preventing cache pollution could be done by assigning a few bits of “ownership” to each cache line fetched and using that to keep track of how many lines each CPU/etc. owns in the cache. For an L1 cache in a hyperthreaded chip, each logical CPU is an owner. In a cache shared across many cores, each physical core might be an owner. To prevent kernel code from polluting user data while doing disk and network bulk moves, “kernel” could by an owner unto itself.
Giving owners a limit on how many cache lines they can use allows an implementation to switch allocation strategies for owners that are over their limit, preferentially replacing their own lines or placing their new fills near the replacement end of a pseudo-LRU replacement list. A loose limit is good enough to prevent starving other users.
This approach is superior to fixed way partitioning of an N-way associative cache because it does not leave as many resources stranded.
An alternate approach requiring no extra ownership bits is to track each owner’s fill rate and essentially rate-limit each owner. Those over their limit get the alternate allocation strategy.
Summary
Our simple “Move 16 bytes per cycle” quest for memcpy and its ilk reveals a nuanced set of instruction-set and microarchitecture issues:
- Fail: Copy-in-RAM and DMA engines
- Both the CPU side and the memory side of caches matter
- Load/Store Partial and Double-width-shift help significantly
- Longer Prefetching matters
- Letting the memory controller know about prefetch length can be 3x faster
- Controlling cache pollution matters
We suggest a few new instructions and some cache management that can help achieve the goal.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
