
In Part I of this mini-series, we looked at recent advances in hardware support for ray tracing and how we might ride this wave to think more broadly about general-purpose irregular computing. Part II looks at another rising trend in graphics, i.e., the confluence of AI and rendering. We will go through a few examples where AI helps rendering, and discuss what this means for architects.
Rendering Meets AI
There is a recent explosion of research exploring AI’s role in rendering in improving both the rendering quality and efficiency. While there is no definitive answer yet, the potential paradigm shift could have profound implications on the underlying computer systems design.
Reconstruction. A promising way that AI helps rendering is to generate a low-quality image initially with impunity and then enhance the image quality in another pass using AI. Recall from Part I that physically-based rendering is sampling-based. Instead of calculating the precise value of each pixel, we sample each pixel multiple times and then reconstruct the pixel values from the samples. During reconstruction, the Nyquist–Shannon sampling theorem tells us that it’s almost impossible to have a perfect reconstruction because real-world scenes usually contain high-frequency signals that can’t be recovered with a finite amount of samples, not to mention with less than one sample per pixel1Additionally, each sample itself isn’t perfectly calculated. Recall that the rendering equation is only approximately solved using Monte Carlo integration. In reality, multiple sources usually contribute to the imperfection of the final image, and it’s hard to distinguish them.!
While a range of hand-crafted approaches were used in the past to reconstruct pixel values from (sparse) samples, recent work, not surprisingly, has started using deep learning models (trained offline). In general, these techniques allow the initial rendering to generate a low-resolution image with very few samples (and thus noisy and perhaps aliased), and then enhance the initial image, e,g., super-sample and/or denoise, to generate a high-quality image. DNN-based super-sampling and denoising are shipped in Nvidia’s products. Facebook uses DNNs for super-sampling and for reconstruction from foveated rendering, a special form of sparse sampling especially appealing to resource-constrained Virtual Reality devices.
Learn to Sample and Integrate. AI can also help decide how to wisely spend the precious sampling budget. Recall from Part I that physically-based rendering requires solving the rendering equation, which is approximated numerically through Monte Carlo integration. The theory of importance sampling tells us that the best sampling strategy in Monte Carlo integration is to draw samples with a probability distribution that is proportional to the integrand, which, however, is unavailable to us (otherwise we wouldn’t have to approximate this integration in the first place!). Historically, people have mainly relied on simple (admittedly pretty effective in many scenarios) heuristics to guess what rays are more important to sample. Recent work has started using deep learning to learn the importance so that each precious sample really counts.
Numerical integration is a fundamental technique that shows up pervasively in computer graphics (and beyond). For instance, classic volumetric rendering requires solving a continuous integration equation along rays, which can be approximated by Monte Carlo integration. However, Monte Carlo integration, and numerical methods in general, presents a fundamental trade-off between accuracy and execution time. Aiming to reconcile this trade-off, recent work started solving the entire integration problem through DNNs, bypassing conventional numerical methods.
Neural Rendering. Finally, lots of recent work starts looking at new modeling primitives that are encoded as neural networks, mostly through Multi-Layer Perceptions (MLPs). These representations are commonly referred to as neural surface representations (note the underlying representation that gets “neuralified” could either be an implicit geometric representation such as the Signed Distance Function or an explicit representation such as voxels). Neural surface representations are more memory-efficient, better at modeling certain geometry details, and, perhaps importantly, amenable to gradient-based optimizations, which lend themselves to be differentiably rendered.
What Do All These Mean for Architects?

Figure 1: Nvidia’s Turing GPU, which integrates hardware for DNN execution, ray tracing, and conventional SIMT executions (source).
The confluence of rendering and AI presents an interesting playground for architecture research. It’s fair to say that future rendering will be a heterogeneous workload, including DNNs, ray tracing, and perhaps even traditional rasterization2Many visualization applications today combine both rasterization and ray tracing. This could be a short-term trade-off when ray tracing performance is catching up. But even if ray tracing is sufficiently fast in the future, it’s unlikely to be faster than rasterization and so there could still be scenarios where rasterization, or the hybrid approach, is the preferred rendering algorithm.. Today’s GPUs are reasonably well-positioned in this potential paradigm shift, because they are optimized for all three algorithms by having three spatially separated accelerators (Figure 1). Nevertheless, many open questions remain.
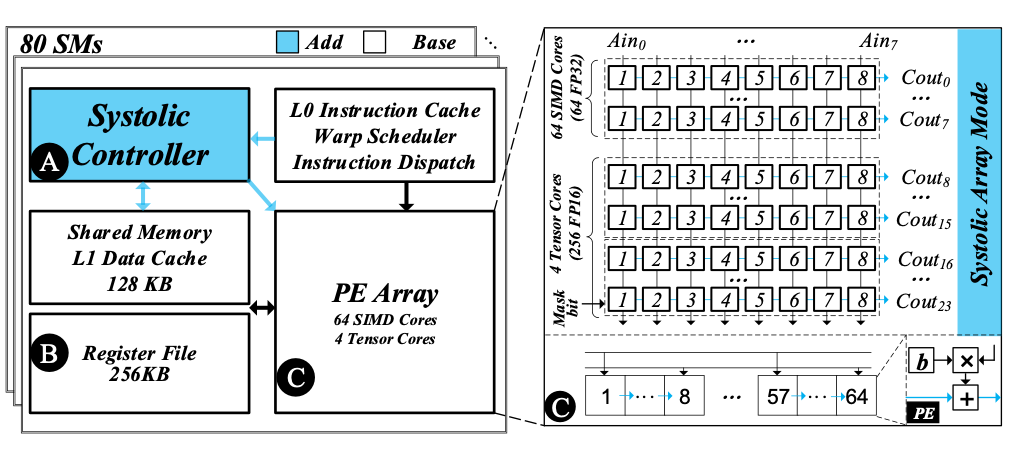
Figure 2: The SMA architecture that can reconfigure between a systolic array and a SIMT core.
If we were to design a real-time rendering hardware from a clean slate, would it make sense to have a unified architecture that simultaneously supports both the SIMT execution and DNN (admittedly ray tracing is quite different from these two)? Figure 2 shows one such architecture that can temporally reconfigure between a SIMT core and systolic array. The design starts from a SIMT core, and judiciously applies lightweight architectural augmentations to support the systolic execution for DNNs. It turns out that, with some care, much of the SIMT hardware can be directly reused or repurposed for a systolic array. For instance, the operand collector in a typical SIMT core can be used as a local buffer for storing the stationary weights. As a result, the area overhead to support reconfiguration is negligible.
Critically, such a temporally-reconfigurable architecture can benefit a wide range of applications beyond rendering. Virtually no real end-to-end applications can be exclusively mapped to only DNN accelerators or only SIMT cores. Even image segmentation, a relatively narrowly-defined task, contains both DNN accelerator-friendly stages (e.g., convolution) and other stages that are not amenable to a DNN accelerator (e.g., non-max suppression). Temporally sharing the same architectural substrate, thus improving the area efficiency, is critical to cost-sensitive markets such as autonomous driving, which is undoubtedly a highly diverse workload.
Even if we assume a spatially decoupled architecture as in Nvidia’s Turing GPUs, one can ask: how would we partition the hardware resources between SIMT cores, ray tracing cores, and DNN accelerators, and how would we dynamically schedule the workload across them? In this context, continuously co-designing the algorithms with the hardware will be the key. For instance, we ideally would want to pipeline the SIMT cores and the DNN accelerator in real-time rendering; to achieve a balanced pipeline, the ray tracing workload and the DNN workload (for denoising/super-sampling) would have to be roughly equal, which dictates the algorithm design.
Acknowledgements: Thanks to John Owens, Peter Shirley, and Adam Marrs for comments and discussions. Any errors that remain are my sole responsibility.
About the Author: Yuhao Zhu is an Assistant Professor of Computer Science at University of Rochester. His research group focuses on applications and computer systems for visual computing.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
- 1Additionally, each sample itself isn’t perfectly calculated. Recall that the rendering equation is only approximately solved using Monte Carlo integration. In reality, multiple sources usually contribute to the imperfection of the final image, and it’s hard to distinguish them.
- 2Many visualization applications today combine both rasterization and ray tracing. This could be a short-term trade-off when ray tracing performance is catching up. But even if ray tracing is sufficiently fast in the future, it’s unlikely to be faster than rasterization and so there could still be scenarios where rasterization, or the hybrid approach, is the preferred rendering algorithm.
