
The Memory (Bandwidth and Capacity) Wall
The “memory wall” problem, originally coined by Wulf and McKee in the 1990s, pointed out that the rate of improvement in microprocessor performance far exceeds the rate of improvement in DRAM memory speed. Such trend rendered the memory subsystem to become one of the most crucial system-level performance bottlenecks. Along with the memory “bandwidth’’ wall, computer system designers also noticed the emergence of a new memory wall in datacenters, one of memory “capacity’’, where the growing imbalance in peak compute-to-memory-capacity required hyperscalers to overprovision the memory size of each server to its worst-case usage, resulting in significant memory underutilization. To overcome the memory wall problem, there have been two important lines of studies pursued by computer architects, one being Processing-In-Memory (to tackle the memory bandwidth issue) and the other being memory disaggregation (aimed to address the memory capacity issue).
PIM and Memory Disaggregation for Overcoming the Memory Wall
The initial materialization of Processing-In-Memory (PIM) dates back as far as in the 1970s. By placing a lightweight compute logic near/in memory, PIM helps alleviate the memory bandwidth limitations of conventional, von Neumann computer architectures. Stone’s Logic-in-Memory computer is one of those early studies where a number of processing engines and small caches are augmented near the memory arrays. Motivated by its potential, there has been numerous follow-on work that extends PIM style approaches, well known examples being computational RAM, IRAM, Active Pages, DIVA, etc. Despite such enthusiasm from academia, however, the computing industry have been slow in embracing PIM-style approaches for commercial products due to its high design overhead (e.g., losses in DRAM density, thermal challenges) and its intrusiveness to the conventional hardware/software interface (e.g., PIM ISA support, managing data coherence, …).
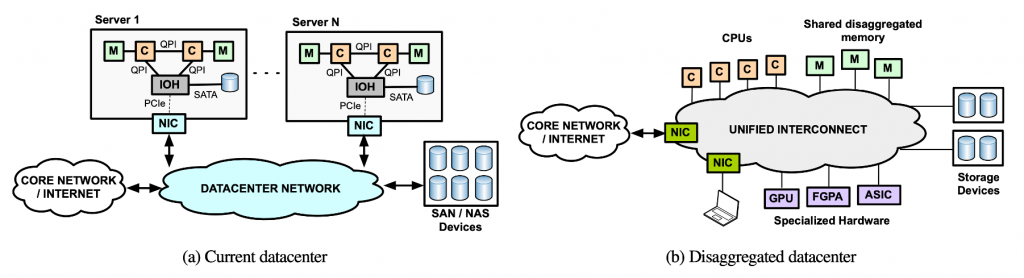
Figure 1: High-level architectural differences between conventional servers vs. resource-disaggregated datacenters. Figures are from Gao et al. “Network Requirements for Resource Disaggregation”, OSDI’16
Memory disaggregation seeks to address the memory underutilization issue by breaking the physical boundaries of datacenter’s compute and memory resources. Conventional datacenters are designed as a collection of monolithic servers, each tightly coupled with a fixed CPU and memory resources. By disaggregating CPUs and memory under separate physical entities (i.e., compute node vs. memory node), one can construct a shared “pool” of memory (and similarly, a shared pool of compute and storage) which allows the executing CPU process to dynamically (de)allocate resources from the shared memory pool on-demand, enabling higher memory utilization (Figure 1). Unlike PIM which lacked a killer application that justified its high design complexity, there is an obvious incentive for hyperscalers to embrace disaggregated server architectures as it helps optimize the TCO (total cost of ownership) of datacenters. Intel’s Rack Scale architecture, HP’s The Machine, and Facebook’s Disaggregated Rack are one of those prominent approaches, seeking to design a server platform that is more suitable for datacenters’ dynamic resource usage patterns. However, a blocking factor for realizing high-performance disaggregated server architectures have been the network, i.e., in order to achieve good application-level performance, it is vital for the network fabric to provide low latency communication. That is, disaggregated servers inevitably incur high inter-node communication between compute and memory nodes, potentially causing high performance penalties.
Recent Commercialized Products enabling PIM and Memory Disaggregation
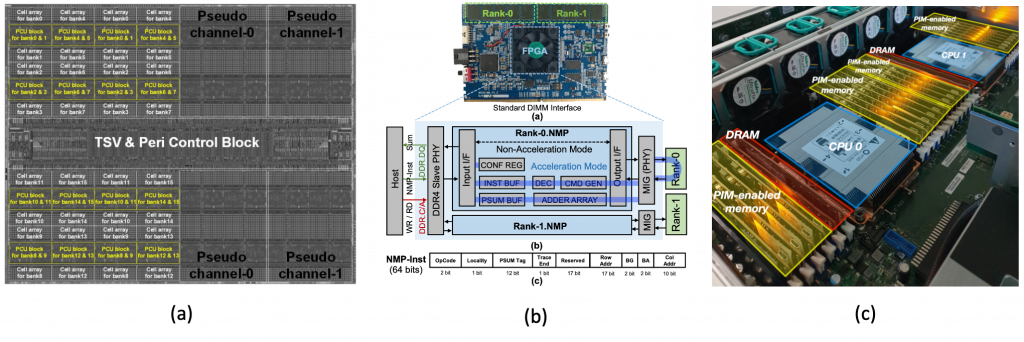
Figure 2: Recent commercial-grade products employing PIM: (a) Samsung’s HBM-PIM (Kwon et al., ISSCC, 2021), (b) Samsung-Facebook’s AxDIMM based system for accelerating AI based recommender systems (Ke et al., IEEE Micro, 2021), and (c) UPMEM’s PIM module deployed in a commodity server system (Gomez-Luna et al., arXiv, 2021).
While the lack of a killer application that justifies the overhaul in hardware/software was a key obstacle in commercializing PIM, the rise of memory-bound AI workloads is pushing key industrial players to embrace and productize PIM inspired memory solutions. Samsung’s HBM-PIM is one of those noteworthy efforts which integrates a DRAM bank-level SIMD processing unit for high-throughput PIM operations, demonstrating impressive energy-efficiency improvements over real silicon for memory-bound AI workloads (Figure 2(a)). Samsung also seems to be in the works of developing a near-memory processing solution called AxDIMM which, in collaboration with Facebook, demonstrated its efficacy for accelerating AI-based recommendation models (Figure 2(b)). And while not particularly targeting AI workloads, the French startup UPMEM also released a PIM solution which integrates a per-bank processing engine (called DPU, DRAM Processing Unit) for accelerating generic, memory-bound applications (a recent technical report from ETH Zurich provides a comprehensive characterization and analysis on UPMEM’s pros/cons, Figure 2(c)).
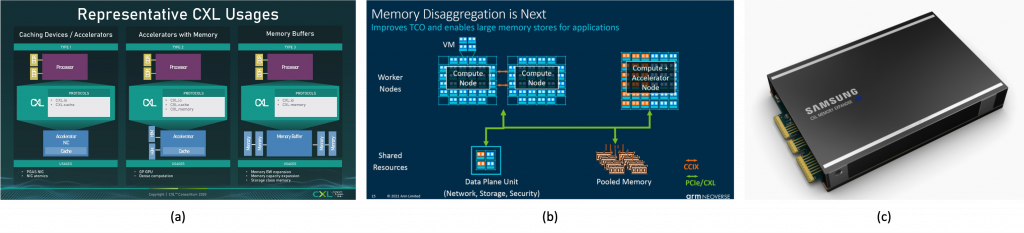
Figure 3: (a) Representative CXL use cases (type 1/2/3), (b) its utilization for memory disaggregation in upcoming ARM Neoverse servers, and (c) Samsung’s CXL-compliant DDR5-based memory expander module (type 3) for scaling memory capacity and bandwidth.
Along with the emergence of PIM enabled memory solutions, the recently standardized CXL (compute express link) interconnect is also opening up opportunities to overcome the memory (capacity) wall problem by incorporating a disaggregated/pooled memory over a fast and cache-coherent communication fabric (Figure 3). CXL, an open and industry-supported interconnect standard, is based on the PCIe (gen5) interface, which allows processors to access the disaggregated memory node in a high-bandwidth/low-latency manner. Other important features of CXL include advanced security features in memory management (e.g., secure memory allocation, secure address translations), logically partitioning the pooled memory device across multiple compute devices and more. Admittedly, this is not the first time we’ve seen a cache-coherent, high-bandwidth interconnect that embraces the concept of disaggregated memory (e.g., OpenCAPI, Gen-Z, CCIX to name a few). CXL does however appear to be one of the first to receive a broad industry-wide support, not only from major processor (Intel/AMD/ARM) and memory (Samsung/SK Hynix/Micron) vendors but more importantly from hyperscalers which will eventually become the biggest consumers of these products for mass deployment.
Remaining Challenges
Despite the availability of these commercial-grade PIM/memory disaggregation solutions, there are several remaining research challenges that must be addressed in order for these memory-centric architectural solutions to be widely deployed in commodity systems, e.g., ease of programming, compiler/HW support, virtual memory and coherence support, etc. Following is an excerpt from a technical report published by Facebook (titled “First-Generation Inference Accelerator Deployment at Facebook”), pointing out one of these important challenges, i.e., the need for enhancing the programmability of PIM.
“We’ve investigated applying processing-in-memory (PIM) to our workloads and determined there are several challenges to using these approaches. Perhaps the biggest challenge of PIM is its programmability. It is hard to anticipate future model compression methods, so programmability is required to adapt to these. PIM must also support flexible parallelization since it is hard to predict how much each dimension (the number of tables, hash size, or embedding dimension) will scale in the future (while for example, TensorDIMM only exploits parallelism across embedding dimension). In addition, TensorDIMM and RecNMP use multi-rank parallelism within each DIMM but typically the number of ranks per DIMM is not enough to provide significantly high speedup.”
It will likely take years to fully understand the implication of adding PIM and/or disaggregated memory to the overall system architecture, how to make best use of it, and what other important research challenges remain. Nonetheless, the emergence of these commercially available memory-centric technologies show that PIM/memory disaggregation is no longer a theoretical, academic pursuit, presenting exciting research opportunities with a potential for real-world deployment at massive scale.
About the author: Minsoo Rhu is an associate professor at the School of Electrical Engineering at KAIST (Korea Advanced Institute of Science and Technology). His current research interests include computer system architecture, machine learning accelerators, and ASIC/FPGA prototyping.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
