
Recently, we conducted a detailed study of some notable publication trends at ISCA. We used the abstracts for all the papers published at ISCA from 1973, when it was inaugurated, to 2018. This blog summarizes the main findings of the detailed article which can be found here.
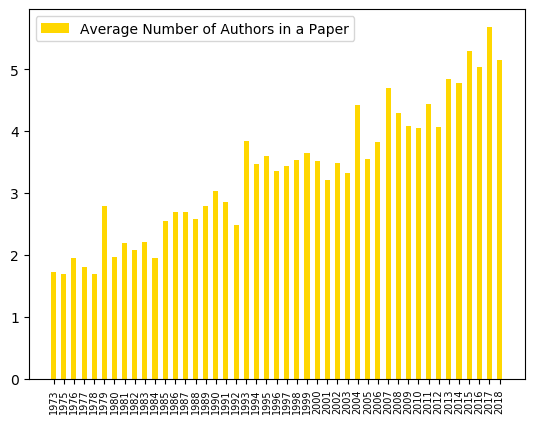
Figure 1: Average Number of Authors in a Paper
We’ll start with a few longitudinal observations. Figure 1 shows an ever-increasing trend in the average number of authors. On the other hand, Figure 2 shows a decline of papers by first authors from industry. We believe this is due to the role of publications in academic evaluations and the growing “Paper Engineering” effort to get papers accepted in tier-1 conferences like ISCA. This effort may not be justifiable for industry researchers.
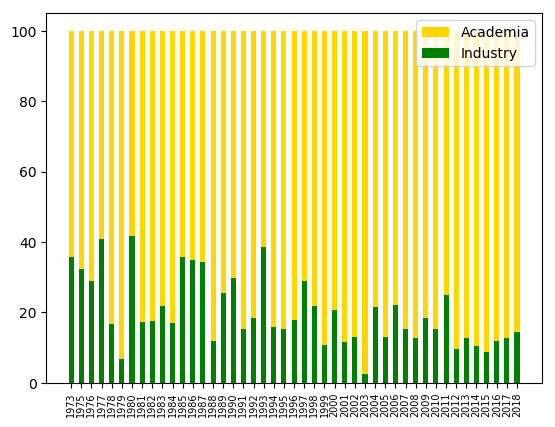
Figure 2: Percentage of industry vs. academia affiliation of first authors
For some of the major topics at ISCA, we found three types of long-term patterns, shown in Figure 3. The first type of topics, such as microprogramming and programming languages, received intensive coverage during the early phase of ISCA and interest in these topics subsided because they are either no longer of interest or have reached their maturity. The second type of topics, such as operating systems and cache coherence, receive periodic surge in coverage. Because these topics are about architecture support for key parts of computing systems, they draw research interest when industry migrates to a new technology or new paradigm. The third type, such as GPU, power consumption and energy efficiency, has received increasing coverage only in recent years.
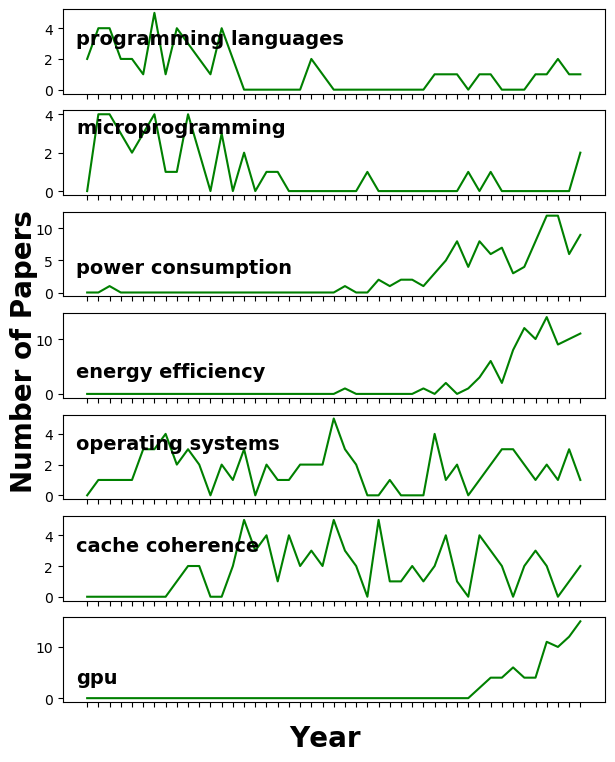
Figure 3: A long-term history of selected top topics
Another longitudinal trend in Figure 4 shows the first author affiliation trend for the last two decades of ISCA. We see a limited amount of institutional diversity – the prominent names are all academic institutions in North America.
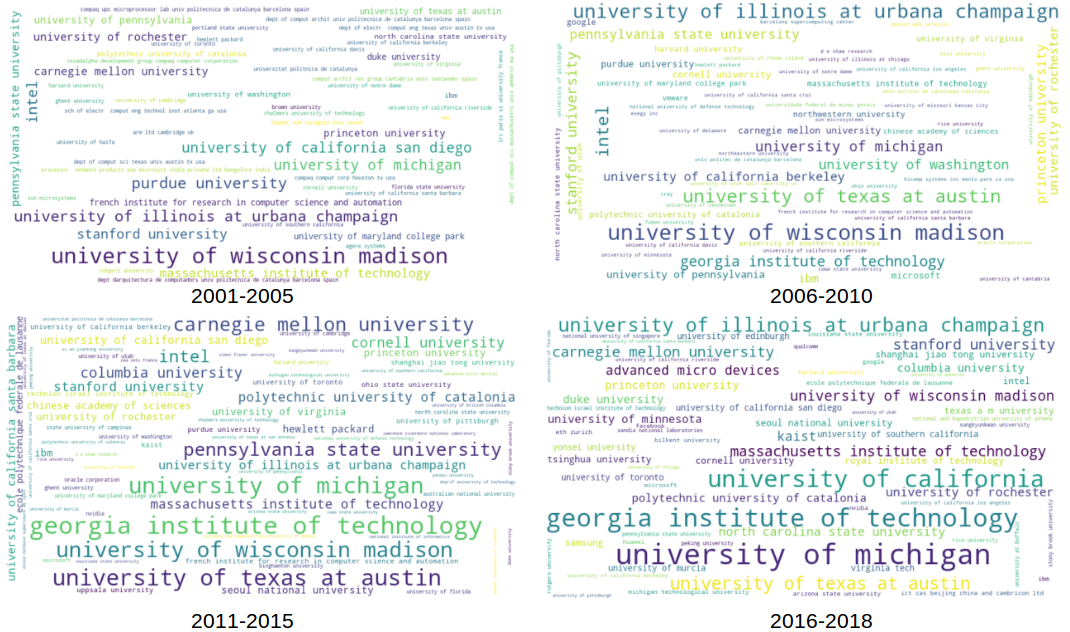
Figure 4: First author affiliation trends over the last two decades of ISCA
For a high level study for this blog, we divided ISCA publications into different decades. During the 1970s, visually captured in Figure 5, the computer industry went through a decade of innovation in the mini-computer movement with new instruction sets that were implemented with microcode. It stimulated the coverage of topics like CPU, instruction set, machine language, instruction execution, low cost, microprogramming, and writeable control. These mini-computers also accelerated the development of high-level languages and multiple of those languages are still in use. One of the lessons learned during that time was that it was not only about the language but also about computation, algorithm and memory access that needs to be reflected in the ISA, implemented by a native hardware microarchitecture through microprogramming. Microcode simplified the processor design by allowing the implementation of control logic as a microcode routine stored in the memory instead of a dedicated circuit. Additionally, the desire to better support operating systems further motivated the introduction of sophisticated instructions that helped data movement, security, and reliability.

Figure 5: Word cloud visualization of topics in 1970s
In the 1980s word cloud shown in Figure 6, the computer architecture community started to embrace parallel processing and high-performance computing. Three major components of those multiprocessing systems were processing elements, shared memory and interconnection network. During this period, challenges in parallel programming have also motivated research in data flow architectures and data-driven execution. At the same time, researchers began to develop new memory consistency models to alleviate the burden of a programmer to program systems with hundreds of processing elements. Memory latency was also a challenge for scaling parallel systems. Researchers developed new memory hierarchies and cache strategies. At the same time, RISC also gained popularity with increased clock speed through deeper pipelines and simpler instructions. The increased processor execution speed further widened the memory wall which further motivated industry to have on-chip caches as more transistors became available.

Figure 6: Word cloud visualization of topics in 1980s
During 1990’s, researchers continued their efforts to bridge the gap between memory and processor speed. Memory for multiprocessing systems were studied. A number of new techniques were also developed including instruction-level parallelism, instruction re-ordering, branch predictions and speculative execution. This was the time when a number of companies came up with superscalar processors, as we can see in Figure 7.
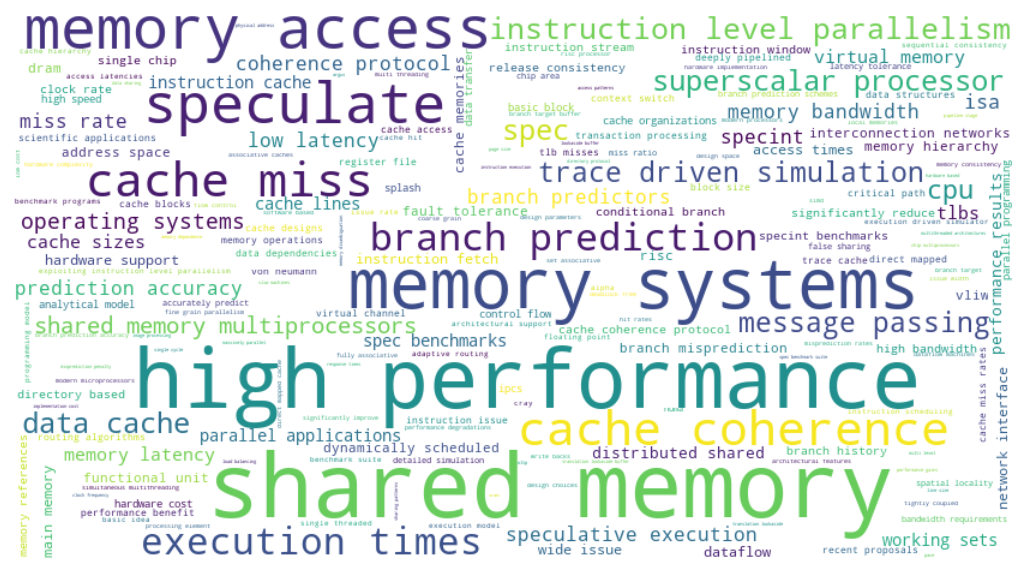
Figure 7: Word cloud visualization of topics in 1990s
The period of early 2000s also saw the peak of speculation techniques in superscalar processors and memory systems, see Figure 8. Computer architecture researchers were publishing extensively on architectural support for compile-time control speculation, data speculation and register file design. In ISCA community, while we see these efforts happening in the context of superscalar processors, we do not see much focus towards VLIW according to the data we collected.
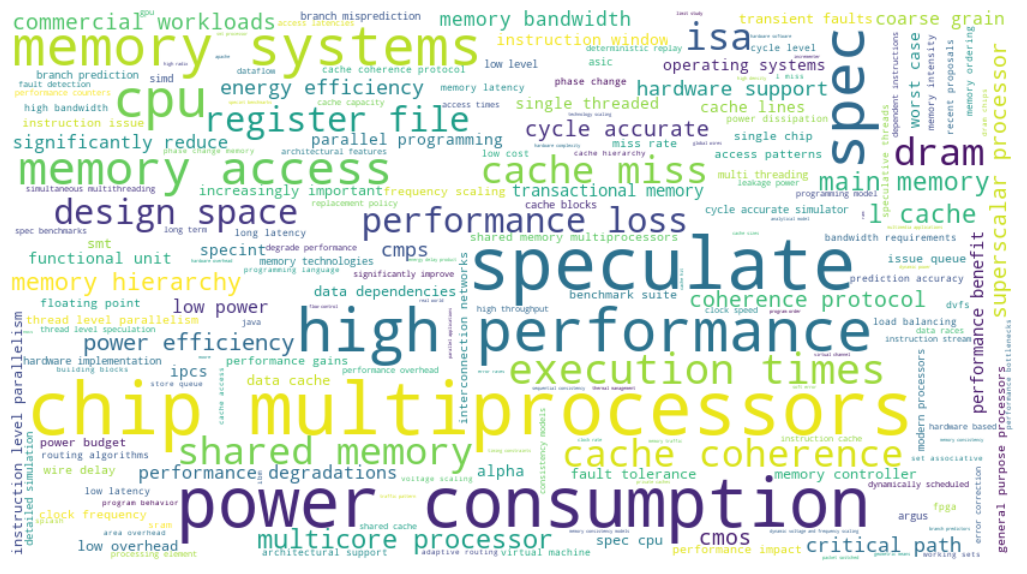
Figure 8: Word cloud visualization of topics in 2000s
By 2005, once industry had achieved super-linear scaling of high performance designs with higher clock speed, trends shifted towards energy efficiency. In order to increase performance in the same power budget, industry made a major pivot from uni-processor clock frequency and instruction-level parallelism scaling to multicore scaling around 2003. The clock frequencies and instruction-level parallelism of each CPU core largely remained the same, whereas the number of cores increased over time. NVIDIA developed GPUs with thousands of cores and developed the CUDA programming model to reduce programming effort. However, we observe that the ISCA community supported this move by industry in late 2000s.
We finally turn to the word cloud in Figure 9 which captures the 2010s, where power consumption and energy efficiency became two of the top topics for ISCA authors. “GPU” and “DRAM” were also finally embraced as major research topics. Part of the reason is the increasing popularity of machine learning in even the ISCA community. GPUs have clearly driven machine learning advances in the past decade and they serve as the baseline for next-generation accelerators.
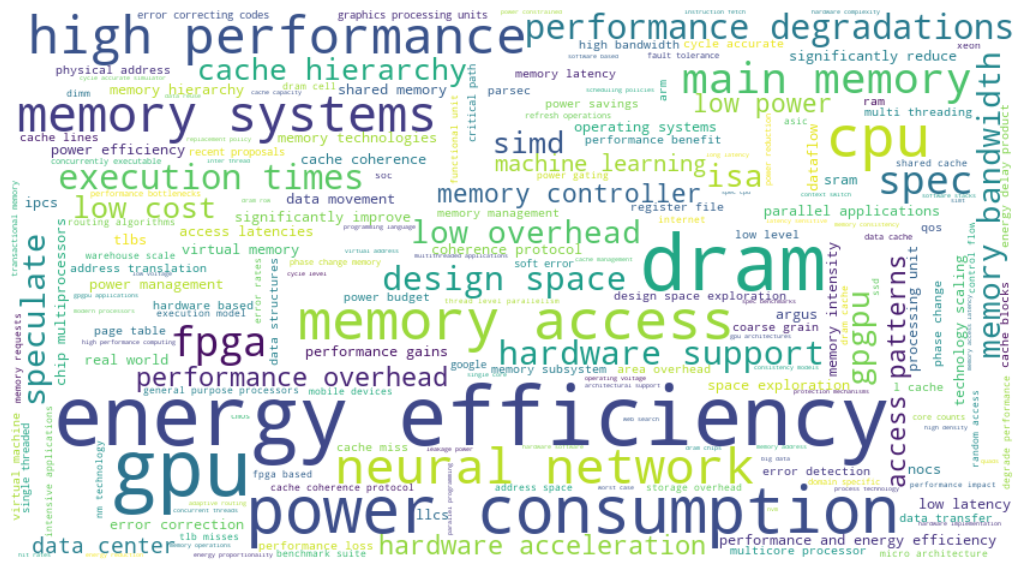
Figure 9: Word cloud visualization of topics in 2010s
Looking forward, we expect that power consumption and memory access efficiency will remain as main challenges in the next few years. We will likely see increasing research trends for near/in memory processing, targeting increased memory bandwidth along with low power consumption and increased parallelism. Proposals for redesigning memory systems are likely to continue. We fully expect the 2020s word cloud to prominently feature accelerators and deep learning. Systems will have more heterogeneity in terms of compute resources. All these changes will eventually make it difficult to program systems with existing programming languages. We believe that another wave of activity in innovative support for new programming languages will likely manifest.
Our data-driven approach gives a historical perspective of our field and we end with a few suggestions for our community:
-
We encourage more industry papers, and encourage the community to support such work and industry tracks at conferences.
-
We also encourage academia to set industry trends and consider societal impact, in addition to following industry roadmaps.
-
The ISCA community should take steps to further promote institutional diversity.
About the Authors: Omer Anjum is a post-doctoral researcher, Wen-Mei Hwu is a Professor, and Jinjun Xiong is a Program Director; all three are affiliated with the IBM-ILLINOIS Center for Cognitive Computing Systems Research.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
