
The past five years have seen a significant change in the way cloud applications are designed. In place of large monolithic services, where the functionality of an entire application like a social network or search engine was implemented as a single codebase that compiled to a single binary, cloud services have increasingly adopted fine-grained, modular designs. As a result, concepts like microservices and serverless are becoming increasingly household terms. While the software engineering and distributed systems communities have increasingly been investigating the implications these new programming models have, these implications are not yet clear for computer architects.
This post provides an introduction to the concepts, opportunities, and challenges of serverless compute and microservices, and offers some suggestions on what their increasing prevalence means for computer architecture, such as the need for closer hardware-software integration, and the hardware support needed to satisfy their strict latency requirements.
What is serverless?
Serverless compute is an event-driven programming model with short-lived tasks, primarily used in cloud and IoT settings, which favors applications with ample parallelism and/or intermittent activity. For example, a data-parallel video encoding application is well-suited for serverless, as all independent tasks operating on video chunks can be launched concurrently, yielding orders of magnitude faster execution compared to traditional cloud resources, for a modest increase in cost. Similarly, computation tasks triggered by an edge device, like a drone, experience intermittent activity, and hence benefit from serverless by incurring much lower costs compared to maintaining long-running cloud instances.
A user uploads the tasks (serverless functions) they want to execute on the cloud, and the cloud provider handles launching, scheduling, placing, and terminating the tasks. Serverless functions themselves are mostly stateless, with most persistent state stored in a remote storage system, like S3 for AWS. Offloading management operations to the cloud provider relieves a lot of maintenance burdens from the user, ideally lowering cloud adoption overheads, and allows the cloud provider to better optimize scheduling and resource provisioning, given their global system visibility, resulting in more predictable performance and higher resource efficiency.
While current serverless offerings have not yet achieved this premise, with dependent functions communicating via high-overhead remote storage, and being limited in their resources and allowed runtime, serverless is gaining increasing traction due to its performance, cost, and ease of maintenance benefits.
Are serverless and microservices the same thing?
Serverless and microservices are often used interchangeably, despite not being the same thing. Unlike serverless, microservices refer to a software design style that favors fine-grained modularity over closely integrated designs. They are also not necessarily short-lived in the way that serverless functions are. Microservices are loosely-coupled and single-concerned. The former refers to the fact that pairs of microservices should avoid substantial back-and-forth communication, while the latter refers to each microservice being optimized for a specific operation in a complex end-to-end service. For example, a social network implemented as a graph of microservices would use one microservice to count the number of followers a user has, and a different microservice to display more accounts a user may be interested in following.
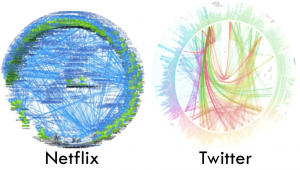

Figure 1: Representative dependency graphs from cloud providers using microservices (points on the perimeter/surface are individual microservices, edges are dependencies between them).
While it may seem that microservices replace an already complex design with one even more complex (Fig. 1 shows representative bundle graphs for microservices in a few cloud providers), they offer several advantages. First, they accelerate development and deployment, given that cloud services are updated on a daily basis, and recompiling and/or redeploying the entire application is a cumbersome and error prone process. Second, they offer better error isolation between application tiers, simplifying correctness debugging and unit testing. Third, they allow software heterogeneity, with different microservices being implemented in different programming languages according to their demands, only requiring a common API to interface with each other, typically using RPCs.
On the opposite side, microservices alter several assumptions current systems are designed with, which impacts their resource bottlenecks, and introduces cascading performance issues across dependent microservices. For a typical production system with thousands of unique microservices scaled out across machines, debugging such performance issues is a cumbersome and error prone process.
Why should I care?
Both serverless and microservices have not yet achieved their full potential. For example, current serverless offerings are resource- and time-limited, and restrict the ways dependent functions can communicate with each other. They are also prone to performance unpredictability, since resources are not dedicated to specific functions, and can be shared and reclaimed by other tenants. Similarly, microservices often fall in the trap of extreme fine-granularity, with the majority of time being spent handling network requests, as opposed to useful computation.
These issues notwithstanding, cloud services are only going to become more complex in both functionality and scale as time goes on. While microservices are not a one-pill solution that should be used in all cloud services, they offer a more practical approach to frequent updates and implementation changes, much in the same way to how modularity in hardware design helps chip architects compose complex processors from basic building blocks. Companies like Netflix, Twitter, Amazon, AT&T, EBay, and Uber, among others have already adopted the microservices model, and all public cloud providers have integrated serverless offerings in their platforms.
What does this mean for computer architects?
There are several takeaways for computer architects from these emerging cloud programming models.
1. Closer integration between cloud hardware and software
Unlike traditional cloud applications, microservices and serverless functions care about microsecond-level tail latencies (e.g., 99th percentile of requests). This means that software inefficiencies – already present in today’s systems – become much more pronounced in these new programming models, degrading performance, and preventing performance predictability. This puts more pressure on (i) better understanding the existing software stack, and (ii) co-designing cloud software and hardware.
2. Hardware support for emerging cloud programming models
The past few years have seen a great resurgence of special-purpose hardware platforms for cloud applications, either via special-purpose chips, like the TPU line, or via reconfigurable acceleration platforms, like Brainwave and Catapult. Acceleration can be profitable for microservices as well, although emphasis should be placed in accelerating common cross-microservice functionality, instead of individual applications, given their sheer scale and diversity.
Apart from accelerating application functionality, architects should also consider investing in hardware support that optimizes overheads associated with containerized, short-lived requests, such as container start-up overheads, caching, and branch prediction.
3. Network matters
As far as many computer architecture studies are concerned, a platform is limited to CPU+cache (+memory). For microservices that is no longer sufficient. Quality of service is quantified in terms of end-to-end performance (latency and/or throughput), with a large fraction of that latency corresponding to processing network requests between dependent microservice tiers. Not only should network be taken into account, but it should be a primary area of optimization, given the tight requirements for responsiveness and predictability microservices have.
4. Using representative applications in academic publications
On a practical note, advances in cloud programming models should reflect the way hardware platforms for these systems are evaluated. For example, while traditional monolithic cloud applications may be sufficient for some architectural studies, they no longer capture the way real cloud services are designed today. Using outdated programming models in architectural studies can lead to incorrect assumptions and conclusions that do not translate to real-world systems.
Overall, cloud software is a volatile and ever-changing scene. While not all new cloud programming models are here to stay, the increasing prevalence of serverless compute and microservices points to a fundamental shift in design principles, which deserves more attention from the architecture community as well.
About the Author: Christina Delimitrou is an Assistant Professor in Electrical and Computer Engineering at Cornell University.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
