
At the outset, a Server class system has a come a long way in terms of improvements in performance, power consumption, thermal cooling and mechanical designs, storage subsystems, I/O fabric speeds etc. In just the last few decades we have seen a technological revolution that is unparalleled. A modern server could have been a supercomputer a few decades back.
As server class systems evolve, a few themes are emerging –
- The CPU is no longer the first class citizen in a server’s compute hierarchy with unfair access to memory.
- More applications are embracing heterogeneity to solve compute needs.
- Applications need to evolve such that memory access is no longer synchronous.
On 1 and 2, the trend has roots in application users looking beyond CPUs for performance and features. Computing needs in emerging technologies like machine learning, deep learning and augmented intelligence etc. are accelerating the trend towards heterogeneous architectures.
On 3, the effect and consequences on application behavior is yet to be studied and understood well.
Traditional application memory accesses is synchronous. 80ns-200ns isn’t a big range for applications to discern or take account of memory access latency. However, with newer memory technologies access latencies can range to tens of microseconds. With this widened range, memory access latency can be noticeable in certain workloads and environments. Coupled with the fact that these memory technologies exhibit varying QoS and endurance characteristics, applications need to be aware of memory tiers.
The effect of this on application design and behavior hasn’t ben understood properly and is an active area of research for server designers.
To throw more light on this, while we have a come a long way since the early days of engaging in discussion on Von-Neumann vs Harvard architecture, we have the same three drivers of innovation in computer architecture today. As shown in Fig.1, these are loosely bucketed under the Compute, memory and I/O bubble.
I conjecture that there are some key attributes that separates these islands. If you observe carefully, the Compute bubble largely dominated by CPUs has a relationship to the memory bubble in a coherency domain. So, a CPU transaction with memory follows an unwritten rule; Coherency shall be preserved with CPU attached memory.
The Compute bubble dominated by CPUs traditionally share a non-coherent relationship with I/O. This relationship involves controlling I/O to transfer from or receive data to memory.
The I/O bubble has a relationship with memory that is defined by its relative latency distance.
With such logical separation of responsibilities traditional applications had a common template to build on the underlying compute architecture.
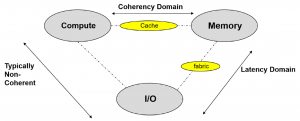
Fig 1 The main innovation bubbles in Computer architecture today
Over the years compute technology has become sophisticated with major breakthroughs in CPUs like paging, move to 64-bit, Virtualization etc. Likewise, I/O has seen major disruptions like the move from parallel I/O to serial I/O, GHz bus frequencies, storage protocol revolution (various protocols), proliferation of flash technologies etc.
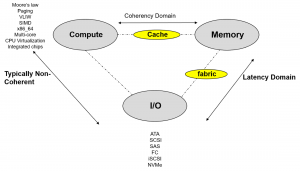
Fig 2 A survey of breakthroughs
And more recently memory has been in the news. The push for Storage Class Memory led by innovations in NVDIMM, PCM, Resistive RAM, MRAM, Carbon Nanotube RAM, 3DXpoint technologies etc. are beginning to have a ripple effect in the design of new server architectures.
And thus the innovation bubbles are being redrawn.
In a world where storage class memory becomes common, ubiquitous and commoditized with economies of scale, fig. 3 surveys such a landscape.
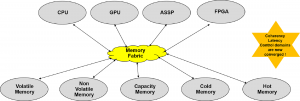
Fig. 3 Memory fabrics converging various innovation drivers.
A key takeaway from Fig 3 is that by designing server architectures using emerging memory fabrics, all previously separated domains viz. coherency, control and latency are converged and yet allow for differential treatment. This movement driven by memory fabrics like Gen-Z, CCIX and Open-CAPI are attempting to bridge the changing memory landscape to the drivers of compute acceleration.
To elaborate, the classification and QoS characteristics of fabric attached memory need to be advertised and utilized wisely by application middleware. Since GPUs, FPGA and ASSPs share the memory fabric, application middleware may need to arbitrate resource access using atomic memory locking primitives. Certain workloads will expect fabric attached memory access to be coherent and in other cases compute will manage memory using non-coherent programming constructs. In other cases memory resources can be instructed to perform compute functions using a command interface via the memory fabric and thus data may never leave a data store. In other cases large quantities of data may need to be moved closer to a compute source. Since all legacy applications cannot be expected to transform significantly, middleware will play a key role in abstracting, virtualizing and efficiently manage tiers across the memory fabric. The challenge though is to ensure that middleware does not become the cause for latency in implementing these algorithms and decisions and so careful designing is required.
And as we think about designing such frameworks for the server based datacenter some new questions come to fore. Here is a sample –
- Who allocates memory in a memory fabric? Note that two or more logically separate server nodes in different electrical domains can now share the same memory fabric and the fabric attached memory.
- Is state of the art middleware equipped to deal with fabric attached memory resiliency?
- Now that they share the same fabric, how can applications migrate easily between CPUs, GPUs and FPGAs etc.?
- Should applications be rewritten/recompiled with compilers that leverage such memory fabrics?
Going forward, I believe frameworks built on memory fabrics will become important. It remains to be seen what frameworks will emerge as we advance in this journey.
About the Author: Shyam Iyer is an architect at Dell EMC’s Office of CTO for Server based products. Shyam is involved in researching new ways to accelerate applications.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
