Years ago, I came across three pioneering works (CSI-NN, Cache Telepathy, and DeepSniffer) in the field of reverse engineering neural networks that inspired my journey into side-channel attacks to uncover the secrets of modern Deep Neural Networks (DNNs). Fast forward to today, and there has been significant exploitation of side-channel attacks to discover the secrets of neural networks. It’s a good time to provide an overview of where we stand, the outlook for the future, and the challenges ahead.
Motivation: Let’s take a step back and first try to understand why we care about secrets in deep learning models. It basically boils down to two fundamental challenges associated with deep learning: i) Financial, ii) Security and Privacy challenges. In general, DNNs are intellectual property (IP), as they are products developed over years of research, implementation, and investment in computing units, and they entail significant training costs (time, energy, and labor), making them a valuable asset for their owners. Just to give a rough estimate, OpenAI’s GPT-4 costs more than $ 100 million, and its GPT-5 model is expected to be more than 5x as expensive (Cost of Training GPT). I do not know about you, but if I spent 100 million on something, I would care about protecting it. The next challenge is knowing that a model secret gives an adversary white-box knowledge, which is extremely powerful in security and privacy settings. Any adversary with knowledge of a target victim’s model architecture (e.g., model type, layer sequence, and number) and weight information, formally defined as “white-box,” can launch powerful security (adversarial attacks) and privacy threats (model inversion attacks/membership inference attacks). As highlighted in Figure 1, the attacker’s final objective in the DNN reverse-engineering attack is to gain white-box privileges either to steal IP for financial gain or to launch subsequent attacks.
In summary, in security and privacy research, defining the threat model is the first step towards any exploitation, and the underlying assumption is often that a reverse-engineering attack has successfully uncovered the model architecture, weights, and other hyperparameters.
Attack Objectives: By now, we have established that an attacker’s goal is to uncover two key properties of a victim DNN: its architecture and its parameters. However, this is an oversimplified goal and can often be misleading. To understand this, let’s consider a deep neural network as a function of x, denoted f(x). If an attacker wants to recover the exact victim model, their objective is for the stolen model to be identical to the original f(x), which is practically impossible for large-scale DNNs, whether using existing side-channel attacks or the exact victim dataset. As a result, a more practical and plausible goal for an attacker would be to achieve functional equivalence. If the stolen function is different, such as g(x), then, for incentive purposes, all an attacker cares about is that these two functions produce identical output, i.e., f(x)= g(x), for inputs x that are of the attacker’s interest. As a result, achieving functional equivalence means recovering the DNN model architecture, often as close as possible to the victim architecture’s topology. On the weight side, even if an attacker cannot extract the exact weights, they must aim for a weight-space solution that captures the victim model’s functionality.
In summary, to steal a copy of the victim model/function, an attacker must identify the victim model architecture. In modern deep learning, where most practical applications use some version of a DNN model from an existing pool (e.g., GPT, Llama), recovering the architecture often boils down to detecting the model’s topology. Once the architecture is revealed, the attacker must recover the model parameters/weights, which is often a challenging part of the attack. Then again, as we discussed earlier, exact model recovery can be challenging, but achieving functional equivalence is a modest objective. Most importantly, to achieve functional equivalence, the attacker may not need to reveal the exact numerical weights; rather, gradually recovering coarse-grained information (e.g., weight sparsity, quantization pattern, weight distribution) is often sufficient.
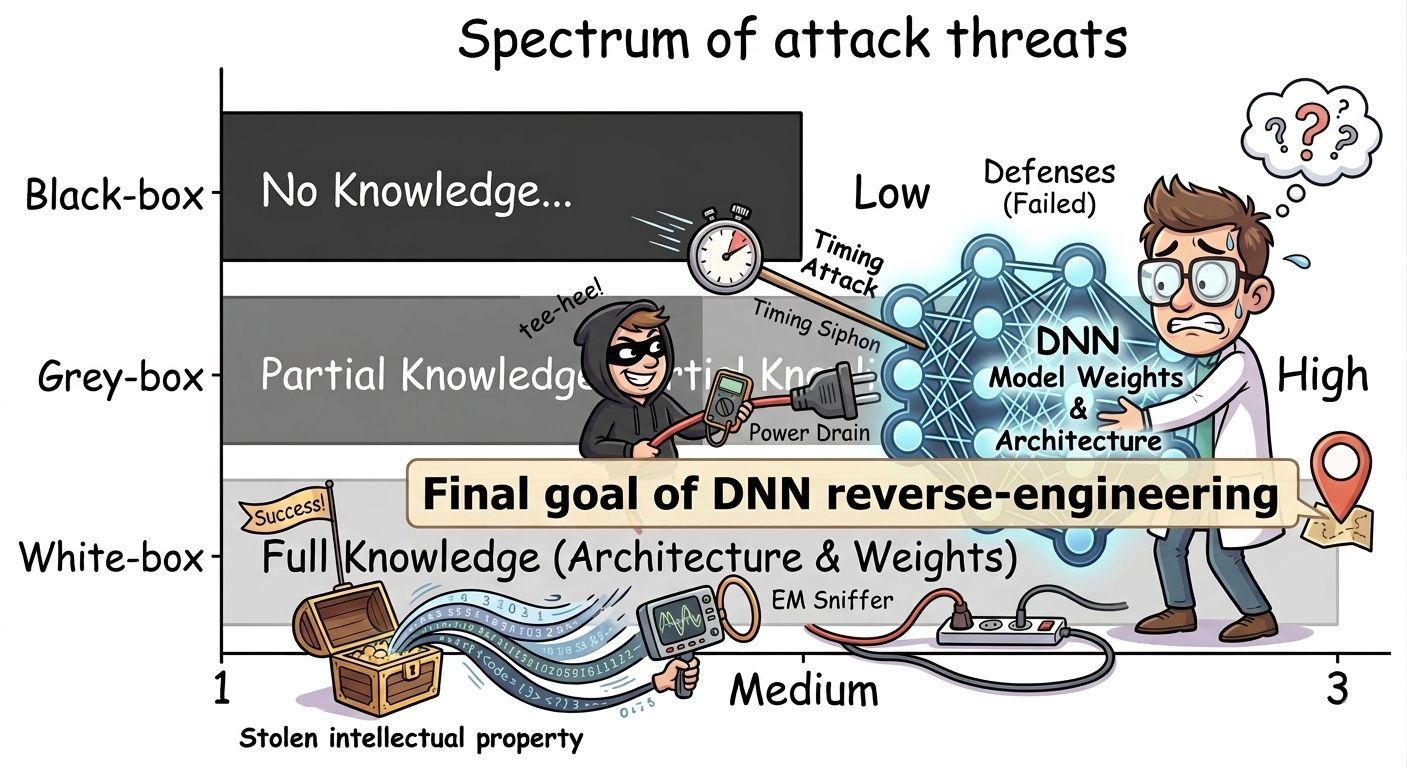
Figure 1: Spectrum of attack threats characterized by attacker’s knowledge: Black-Box (No Knowledge), Grey-Box (Partial Knowledge, e.g., architecture), and White-box (Complete knowledge of model architecture and weights), the ultimate goal of reverse-engineering (AI-generated).
Attack Techniques and Capabilities. Among the popular types of side-channel attacks, i.e., physical and microarchitectural, both can be utilized in two different threat model settings. In edge or embedded devices, the physical side channel is the dominant threat, and several works (CSI-NN, BarraCUDA) have shown that it is possible to recover the model architecture and weights of simple neural networks. On the other hand, micro-architectural side channels are a popular choice for resource-sharing cloud environments where users can upload and run their code in a colocated environment (e.g., Amazon SageMaker and Google ML Engine). Microarchitectural attacks have been successful in recovering model architecture across the board using cache timing channels, memory access patterns, and GPU context switching. I acknowledge that there are many ways to recover DNN model weights, including learning-based approaches and mathematical recovery techniques. In this blog post, I focus on side-channel attacks. At the same time, learning-based approaches can work as a complementary approach with side-channel attacks once the architecture information has already been leaked.
In summary, while side-channel attacks have been successful in leaking model architecture information, as the scale of modern DNNs, e.g., LLM weights, continues to reach new heights of billions, none of the existing side channels can scalably and predictably recover model parameter information. A common workaround would be to support these methods with a learning approach, assuming an attacker has a partial training set, which may not be practical, even in a resource-sharing environment where data remains private.
Future Challenges and Opportunities:
What is the future of architecture-recovery attacks, given the success of existing side channels?
As the next wave of vision and language domain architectures emerges, they present new challenges and opportunities for the microarchitectural side-channel attack community. These models require modern compute support, which can accelerate their inference (e.g., tensor cores), as GPUs become more modern and newer generations may leave new traces of side-channel information. Hence, these newer compute platforms (e.g., new GPUs) and their associated architectural support demand new innovation in side-channel capabilities to recover the model architecture. We must remember that architecture recovery is essential; without it, model parameter recovery is no longer useful. Moreover, as LLMs emerge as the dominant model, the question is not just about recovering weights or architecture; leaking other components, such as KV cache in a multi-tenant setting, can lead to privacy leakage.
Can a microarchitectural side channel alone ever be sufficient to recover model weight information?
The sheer scale of the modern model poses an even greater challenge for recovering weights, making direct recovery an ambitious, and even impossible, goal; instead, we should focus on functional equivalence. To achieve functional equivalence, weight recovery methods can set tiny stepping stones to augment learning-based recovery.
Complete weight recovery using a side channel at the scale of LLMs or even a smaller vision model may be too ambitious. Instead, the attacks should focus on coarse-grained information about weights, such as model sparsity levels, quantization mechanisms, weight sign recovery, and other optimization techniques. The key idea is to achieve functional equivalence by first recovering coarse-grained information, which is sufficient to support other learning-based recovery. It is time to work towards an achievable target: recovering this statistical weight-level knowledge and studying how critical their role is in improving subsequent attacks. As models and their computation units are increasingly optimized, leaking information such as sparsity levels or bit-widths will become more feasible by detecting optimized paths through side-channel leakage.
Finally, an attack is never the end goal. We probe attacks from every angle so we can study them before any attacker ever thinks about them. The endgame is always to develop subsequent defenses, which I leave for another discussion.
About the author:
Adnan Siraj Rakin is an Assistant Professor at the School of Computing at Binghamton University. He received his Master’s (2021) and PhD (2022) from Arizona State University. He works on emerging security and privacy challenges in modern AI systems and algorithms. His paper on DNN model weight recovery has been crowned as Top Picks in Hardware and Embedded Security in 2024.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
