
Today streaming video accounts for over 70% of evening web traffic in the US. YouTube upload rates outpace not only CPU performance, but Moore’s Law itself, and reached 400 hours of video per minute in July 2015. In addition to sheer hours per minute, the videos themselves are getting bigger trending towards higher resolutions and frame rates.
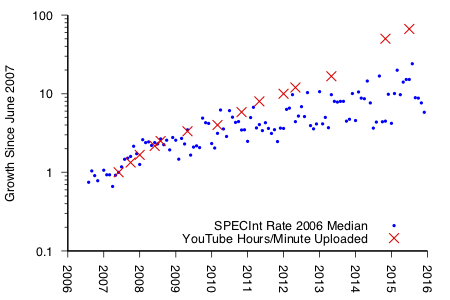
Diverging exponentials pose an urgent infrastructure challenge.
Each video uploaded by a user (as on YouTube or Facebook) or studio (as on Netflix or Hulu) is not simply a video. What appears to the user as a single title has been transcoded — re-encoded for a different format, size, or resolution — multiple times. Transcoding is taxing work, accounting for 70% of Netflix’s total computing. Each transcode task consists of a decode and a re-encoded, the latter of which dominates due to a computationally intensive compression operation. Transcoding not only brings videos down to tractable size, but lets service providers screen source media for problems, such as vulnerabilities or corruptions, and to adjust the format so it can be decoded by a diverse set of target device(s).
The sheer volume of cycles spent on video compression make this a compelling optimization target. However, its nuances can cause even well-meaning architects to report misleading or meaningless comparisons. For example, in 2014 the Netflix encoding team tested out a new HEVC encoder that purported to gain 30-40% compression efficiency. However, when Netflix tested it in their pipeline on their videos, they did not see any gains, as the vendor had used a fast real-time compression baseline and Netflix was looking to improve on their existing, non-realtime, high quality baseline compression.
So, how can architects provide meaningful and much-needed advances in transcoding? Video coding has been on our community’s radar in assorted ways for many years. PARSEC and SPEC 2006 included an H.264 decoder one and two input videos each, while in 2010 Hameed et al. used an H.264 encoder case study in their “sources of inefficiency in general-purpose chips” paper. However, reporting meaningful improvements in video transcoding requires an appreciation of the domain’s distinct characteristics and and the ecosystem in which it plays a central role.
Compression background
Video compression is lossy, exploiting the limits of human perception to cut bits in the least noticeable ways. Humans eyes, for example, are more sensitive to changes in luminosity than color. As a result, we can aggressively subsample the chroma plane while reserving more bits for the luma.

Cutting chromatic information rather than luminance is less noticeable to human eyes.
Compression also exploits redundancy within a video. Intra-frame (or spatial) redundancy occurs when large blocks of a frame are similar, and exploiting it essentially boils down to image compression. Inter-frame (or temporal) redundancy appears when temporally proximate frames contain identical or largely similar content. I highly recommend this video for a clear and visual summary. Temporal redundancy tends to exceed spatial redundancy, and thus offers the bigger opportunities. This applies even outside of compression, where just last month at ISCA’18 two vision accelerators — EVA2 and Euphrates — leveraged the results of earlier frames to speed processing of the very similar ones that follow.
Transcoding metrics
Transcoding influences some major components of a video service’s costs and revenues:
- Small videos consume less space and bandwidth in the Content Delivery Network.
- They also stream more smoothly.
- But faster transcodes reduce CPU demand.
- But visual artifacts hurt user experience.
Encoders are traditionally evaluated according to the compression they achieve and the impact of the lossiness on perceptual quality. For the former, bitrate (bits per second of video) is the widely used and accepted metric, capturing the bandwidth required to store and stream the video as well as a duration-normalized file size. As for perceptual quality, there is a larger slate of metrics ranging from imperfect but objective ones to actual humans which are subjective and hard to scale:
- Peak signal-to-noise ratio (PSNR) — Simple, objective measure of signal error.
- Structural similarity (SSIM) index — A perception-based model of error.
- Video Multimethod Assessment Fusion (VMAF) — SVM-based combination of multiple elementary metrics.
Focusing entirely on the bits and pixels lost, neglects a third important dimension, the computation time required to achieve a resultant video. During a livecast, for example, transcoding must keep up with realtime, and in doing that, bitrate and quality may deteriorate. On the other hand, Netflix streams non-live content to paying customers, and is consequently willing and able to spend extra computation time to minimize buffering events and compression artifacts.
Video content
The video content also impacts the compression time and result as some videos have low information content and some high. Compare the following two videos from vbench, both found on YouTube. The screencast on the top clocks in at 0.2 bits/pixel/second of information and is clearly simpler than the crowded celebration on the bottom which requires 6.9 bits/pixel/second. Action, crowds, scene cuts. All of these contribute new information that eats away at temporal and spatial redundancy. While a simple encoder may get the job done for a screencast, the same technique will produce significantly lower perceptual quality on a busy scene.

A relatively flat, static video with low information content.

A busy, cut-heavy video with high information content.
What’s an architect to do?
Our community knows that a good benchmark can drive a virtuous cycle. For video encoding, a benchmark must expose the tradeoffs an encoder makes and on what types of content. While any practitioner is going to want to test an encoder in their systems, using their sources, we can report meaningful results by:
- Using videos that reflect the target content, or at least be cognizant of the content-dependent behavior of encoding.
- Using the right baseline — realtime encoding for realtime services, high quality for broadcast, and so on.
- Using a common reference, so that others can compare against and improve on your results.
Here is a round up of existing public video benchmarks and video sets.
- SPEC 2006 CPU targets CPU optimizations, and includes a reference H.264 decoder and two videos.
- PARSEC focuses on multithreaded scalability, and includes a libx264 decoder and one video.
- The Netflix dataset targets subjective quality measurements, and includes videos only. There are 72 in all, 9 of which are public, all of which are 1080p.
- The xiph.org derf collection includes 41 HD videos ranging from 480p to 2160p and was used as the reference during AV1 development.
- YouTube-8M contains 7 million video URLS, all creative commons licensed, 120-500s long, and watched over 1000 times. The original target was video classification, so all videos are labeled and often used to train neural networks.
- vbench features fifteen video clips short enough for RTL simulation algorithmically selected from YouTube, open source software baseline, shared reference data, and context-aware scoring functions.
While we believe vbench will provide the richest insights, a full appreciation for the impact of videos and references is most critical.
About the author: Martha Kim is an Associate Professor of Computer Science at Columbia University where she directs the Architecture and Design (ARCADE) Lab.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
