
The tremendous growth in visual computing is fueled by the rapid increase in deployment of visual sensing (e.g. cameras) in many usages ranging from digital security/surveillance and automated retail (e.g. smart cameras & analytics) to interactive/immersive environments and autonomous driving (e.g. interactive AR/VR, gaming and critical decision making). As a result of these different types of usages, a number of interesting research challenges have emerged in the domain of visual computing and artificial intelligence (AI). We characterize these research challenges into four different categories as shown in Figure 1, and they are the following:
- Analyze and summarize insights from visual streams
- Generate interactive and immersive content
- Optimize media content for quality and/or bandwidth
- Orchestrate the processing flow across an end-to-end infrastructure.
Each of these categories opens up challenging problems in AI/visual algorithms, high-density computing, bandwidth/latency, distributed systems. To foster research in these categories, we provide an overview of each of these categories to understand the implications on workload analysis and HW/SW architecture research.
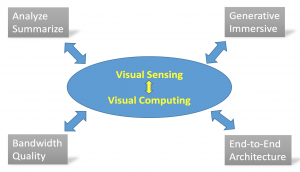
Figure 1. Four Research Areas for Visual Computing
Analyze/summarize Insights from Visual Streams
Analyzing visual data is predominantly accomplished using deep learning. Architectural research in these areas remains traditionally focused on the analysis of object detection and recognition algorithms (e.g. Yolo, ResNet50). These analysis efforts have been focused on improving compute throughput at reduced power consumption which includes exploiting task and data parallelism as well as operations with reduced precision. As we move beyond individual image and frame-based analysis, it is clear that video data is much richer and including temporal information (across frames) in addition to the spatial aspects (within a frame) adds additional attributes that should be considered in workload/architecture research. One such example is activity recognition in motion video (such as LRCN, Convnets) which may entail running combinations of both convolutional as well as recurrent neural networks simultaneously.
In addition to the combination of neural networks for a specific activity recognition or captioning task, richer analysis and summarization of visual data requires the use of knowledge bases and question/answering capabilities. Approaches such as visual data management systems and key-value memory networks need to be analyzed further to understand the architecture implications for future systems that deal with visual data streams and cognitive capabilities. Last but not least, the ability to auto-generate optimal neural networks (e.g. AutoML) and the ability to scale to outrageously large networks with a mixture of experts approach may also be applicable in this domain.
Such innovation in AI algorithms and approaches results in an increase in model size, exponential growth in the compute needs, caching of temporal states, and multiple models to run simultaneously. Architecture and workload analysis research for these growing areas including the use of QoS (multiple models), innovative caching hierarchies (capturing state), addressing compute efficiency as well as programmability becomes critical. Furthermore, as visual analysis transitions from static approaches (single model, specific task) to dynamic approaches (continuous/contextual learning, probabilistic), architectures will need to evolve significantly to support these efficiently.
Generative and Interactive Visual Workloads
Immersive workloads (AR/VR) are well understood to be computationally challenging as well as latency sensitive due to the need to capture panoramic content and deliver it from the capture location (e.g. sports arena) to the consumer (head-mounted device in the home). In addition to these, there is a new category of interactive visual workloads that is rapidly emerging due to advancements in AI. Emerging AI visual systems are going beyond understanding pixels and towards actually generating them. Based on generative techniques (GANs), AI-based systems can produce content to augment or completely replace the current content production methods. Advantages can be harnessed in terms of execution efficiency as well as realizing immersive VR usages for example.
Initial signs of this advancement are already evident in multiple areas. Artists, researchers, and engineers are already starting to harness the power of deep learning based generative models to create content. Notable among these trends are artists using GANs for style transfers, creating realistic images and videos based on narrative or context. Such models for immersive content generation leads to research in novel system architectures. Generative models process information and multiple hundreds of times per iteration to generate multiple possible pixel value proposals before choosing the most appropriate results. For immersive usages, this amounts to multi-thousand-pixel generation in multi-dimensional space. Apart from putting unprecedented strain on the computing subsystems, such workloads are heavy on data usage requiring a new way to analyze, store and retrieve data. Researchers need to be looking at how to combine efficient ways of jointly optimizing compute and memory for such immersive content generation methods.
Quality vs Bandwidth
In a traditional visual analytics pipeline, we compress the data by exploiting the redundancies in time and space. Such compression is designed to replicate the data such that the reconstruction losses are imperceptible to the human eye. As more and more data is used for machine analysis, as opposed to human consumption, new research is focusing on what optimizations can be jointly applied to compression and analysis. For many IoT applications involving wireless video sensors (e.g. surveillance, ADAS), the video data captured at the sensor is compressed and transmitted to the cloud for visual analytics. As the amount of video being streamed keeps increasing at a rapid pace, it is important to make efficient use of wireless bandwidth, while not adversely impacting the accuracy of computer vision analysis. Since the edge-devices (sensors) are often battery-powered, there is also a need to decrease the amount of computations at the edge for data-compression.
Research efforts are needed to look at jointly optimizing encoding and analysis to achieve significant gains in computation and reduction in compressed data transmission/storage. These approaches treat the joint combination of data encoding and analysis as novel workloads taking advantage of combining the traditional encoder-decoder architecture and recent advances in deep learning systems. There are multiple ways such approaches may work and many of these can be combined for more efficient results. For example, compression schemes may evolve to be analytics aware. The compression identifies saliencies and redundancies in the data as they are pertinent to the application of choice and encodes the data accordingly. Such encoders can estimate the potential locations of objects of interest in a given video frame and encode these Regions of Interest (ROIs) with higher fidelity while heavily compressing the other regions.
The ROI can also be estimated dynamically using feedback from the cloud, signaling object detections in prior frames and extrapolating those regions using motion vectors. On the other hand, analytics algorithms can also evolve to be compression aware so that the analytics can understand the artifacts and hints in the encoded data and use this information to its advantage. The compressed video data transmitted contains various syntax elements like motion vectors and macro-block types. These syntax elements indicate spatial or temporal saliency in the video. For visual analytics, we can use these bit-stream elements as side information to perform compression-aware analytics on highly compressed video data. HW/SW architecture research that analyzes and understands these joint optimizations are critical as the visual data growth keeps advancing with no end in sight.
E2E Architecture and Orchestration
In a typical data analytics pipeline, data flows between the endpoint (client or IOT device) and the cloud (server(s) in a datacenter) with a range of analytics that needs to be performed on the data depending on the use case. Visual computing, in particular, has use cases where large amounts of data can originate from the endpoint and flow towards the cloud (e.g. digital security/surveillance) or backward where end devices consume data (e.g. content streaming) or both simultaneously (e.g. live streaming) requiring endpoints communicating via the cloud. These high bandwidth visual data use cases have unique infrastructure challenges since they are a combination of significant computational needs, network bandwidth and/or stringent latency requirements.
Visual IOT describes examples of the needs of small scale to large scale visual recognition workloads. Much of workload analysis and architecture research tends to focus on either the device alone or the cloud server. However, more studies are required to understand how functions can be statically or dynamically mapped to different platforms in the end-to-end infrastructure, especially as the analytics capabilities, as well as the visual data, becomes richer over time. Orchestration of functions requires not only architecture innovation but also infrastructure innovation in order to ensure that developers and system integrators can more seamlessly optimize their end-to-end workflow for specific targets.
Summary
Overall, the rapid growth of visual computing workloads continues to pose important and challenging research areas that are ripe for emerging architecture and workload characterization research. We outlined the high level characteristics of four key areas and showed how these are evolving to raise challenges from high computational needs to intelligent memory/storage techniques to dynamic end-to-end partitioning and orchestration.
About the Authors:
Ravi Iyer is an Intel Fellow and has published 150+ papers on topics such as emerging architectures, technologies and workload characterization. He received his Ph.D. in Computer Science from Texas A&M University. He is also an IEEE Fellow. Omesh Tickoo is an Intel Principal Engineer and Research Manager. His research is focused on next-generation algorithms and platform solutions for human-computer interaction. His current research interests include probabilistic computing, interactive multi-modal scene understanding, and contextual learning. He received his Ph.D. in Electrical and Computer Systems Engineering from Rensselaer Polytechnic Institute. Nilesh Jain is an Intel Principal Engineer, his research interests include machine learning applications at the edge and in the cloud and system architecture and technologies that improve power and performance. He received an MS in computer engineering from the Oregon Graduate Institute, Portland.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
