
René Descartes, inspired by anatomical observations of nerve fibers, suggested in his monumental work Principles of Philosophy that (in modern terms) visual stimuli of the external world are captured and transmitted as fluids traveling through nerve fibers, leading to an internal representation that eventually becomes a perception in the mind.
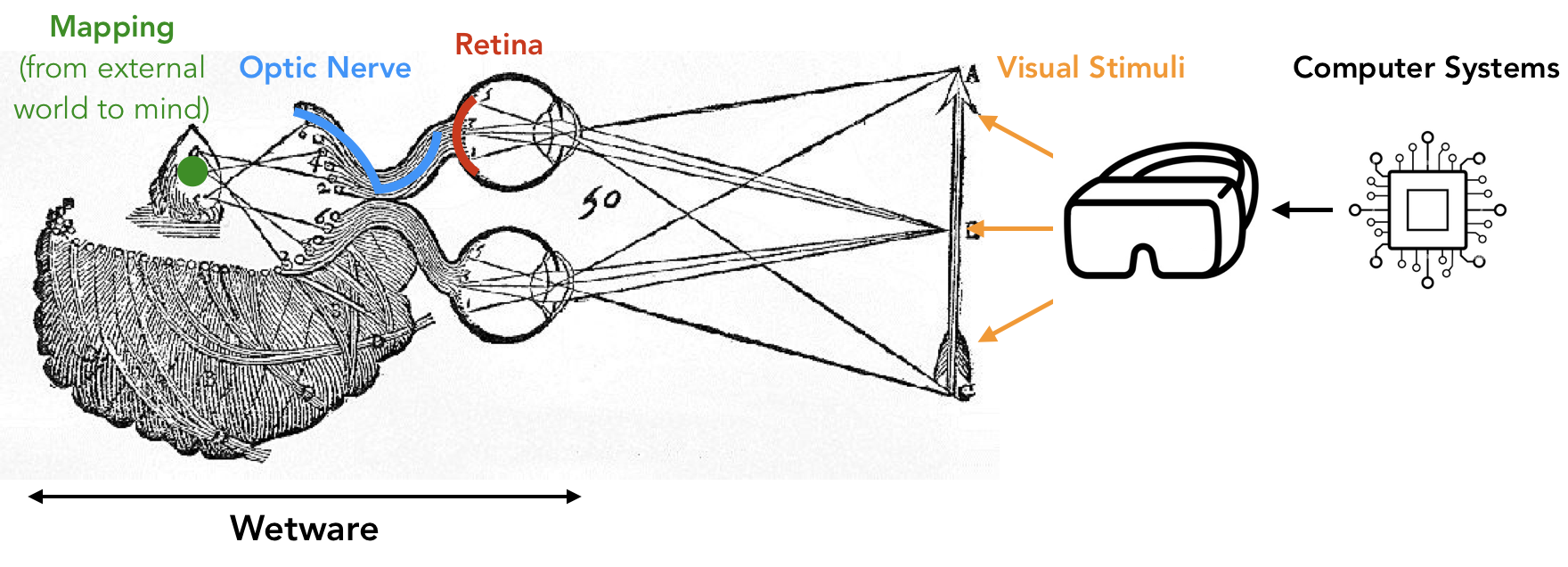
Figure 1: Adapted from Descartes’ Treatise of Man annotated with modern terms. It is important to note that while his overall intuition is correct, not all details are supported by modern science.
I sometimes wonder if the anatomical observations at least indirectly influenced his famous framing of “I think, therefore I am”: maybe the flow of fluids convinced him of the existence of consciousness and, thus, being. In any case, modern neuroscience undoubtedly points out that external visual stimuli directly affect the internal processing throughout the visual pathway, which I will loosely refer to as the wetware. In this sense, we, computing systems designers, can directly modulate human visual perception (HVP) — even without implanting a device into the human brain.
Why do we care about HVP? Apart from nobel scientific quests, I want to make the case that understanding HVP is essential in designing efficient visual computing systems, especially those of immersive nature (e.g., Virtual/Augmented Reality). This article is a (necessarily incomplete) tour of fascinating facets of HVP interspersed with opportunities for systems research. Hopefully, I can convince you that the name of the game is really wetware-in-the-loop design.
Spatial Vision
Our peripheral visual acuity is extremely bad. If you fixate straight ahead, you won’t be able to tell the details of an object in your peripheral vision. The fundamental reason is well-known: photoreceptor cell distribution is extremely non-uniform on our retina. Anatomical data show that more than 95% of the photoreceptor cells lie in the central region of the retina, called the fovea, where we say the eccentricity is 0°. As soon as we move beyond the fovea, i.e., the eccentricity increases, the density of photoreceptors drops sharply. See Figure 2.
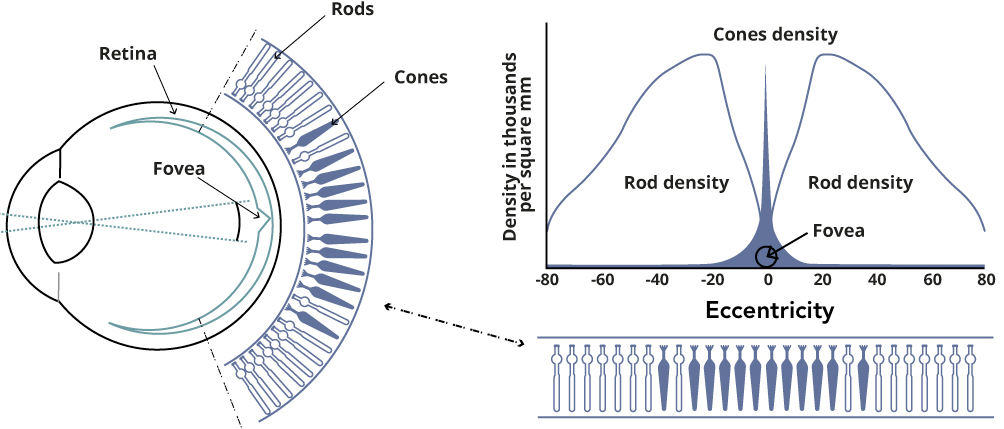
Figure 2: Illustration of non-uniform photoreceptor cell distribution on the retina. Cone cells are responsible for daylight vision, and rod cells are responsible for night vision. 95% of cone cells are concentrated at eccentricity of around 0°, a.k.a., fovea. 1Sharp readers like you might have noticed that the rod density is almost zero at fovea. This is because the rods and the cones have to compete for the physical area on the fovea; high cone density there necessarily translates to low rod density. Why that’s so is anyone’s guess, but I’d favor an evolutionary explanation: we are evolved to see better during daylight, since we can’t see much at night anyways. Beyond fovea, rod density first increases and then decreases. This means when you try to see something in a dark environment, don’t focus straight at it; instead, place it somewhere at 20° of your visual field! Image credit: Tobii.
Rendering
The low peripheral vision doesn’t quite affect how computer systems are designed for PCs and smartphones, since the visual content coming from their displays will mostly fall in the fovea. When immersed in a virtual environment (e.g., when a user wears a VR headset), however, much of the visual stimuli generated from the computer systems will fall in the peripheral of the retina. This observation gave rise to the now well-established area of foveated rendering, where one could improve the rendering speed by generating low-quality visual stimuli for the periphery with impunity. Our community has quickly picked up the idea and proposed hardware extensions to support foveated rendering in AR hologram and cloud-assisted collaborative VR rendering.
Sounds simple? Not quite so. We must answer a basic question: what exactly to render in the periphery without degrading perceptual quality? Perhaps unsurprisingly, today we simply blur or lower the resolution of the peripheral content. These empirical approaches, however, introduce suspicious artifacts, and it’s not clear whether blurring content buys us any computation saving.
A scientifically sound answer requires understanding the complex processing that takes place in the entire human visual pathway, including processing on the retina, in the Lateral Geniculate Nucleus, and by the visual cortex of the brain. Just to entertain some math, assume we could model the human visual processing as a function f, and model the original input stimulus (without any degradation) as I. What we want to find is an alternative stimulus I’ such that f(I) = f(I’), all the while minimizing the cost (of the underlying computing systems) to generate I’.
As you might imagine, the central difficulty is how to model f, which we know is highly non-linear, dynamically self-adapting, feedback-driven, and most likely non-differentiable, but no one really knows what exactly it looks like. Cognitive and neuroscience literature is rich with hypotheses and even models of bits and pieces in the entire system, but to date we simply do not know how to model f from first principles.
Since we can’t derive f from first principles (yet), we look for the next best thing: a computational model that fits experimental data. In collaboration with folks at NYU, our recent work makes a good stride in this direction by computationally modeling one specific aspect of human vision: color perception. Through over 8,000 (IRB-approved) trials of psychophysical measurements on real participants, we build a computational model that tells us, for a given reference color at a given eccentricity, the set of colors that are perceptually no different from the reference color. See Figure 3 left. Naturally, the cardinality of that set increases with the eccentricity. The peripheral color confusion is a specific instance of the low acuity of peripheral vision.
Why do we care about color? It turns out that the OLED display power is dictated by color (and brightness of course); some excellent examples that came to mind are Crayon, Into the wild, Chameleon, and a recent work by Dash and Hu. At the extremes, black means no light is emitted from the sub-pixels and consumes no power, whereas white requires all the sub-pixels to emit max amount of light and consumes the highest power. Hardware measurements (see Figure 3 right) allow us to build another computational model, this time to model the total display power as a function of color (the R, G, B values).
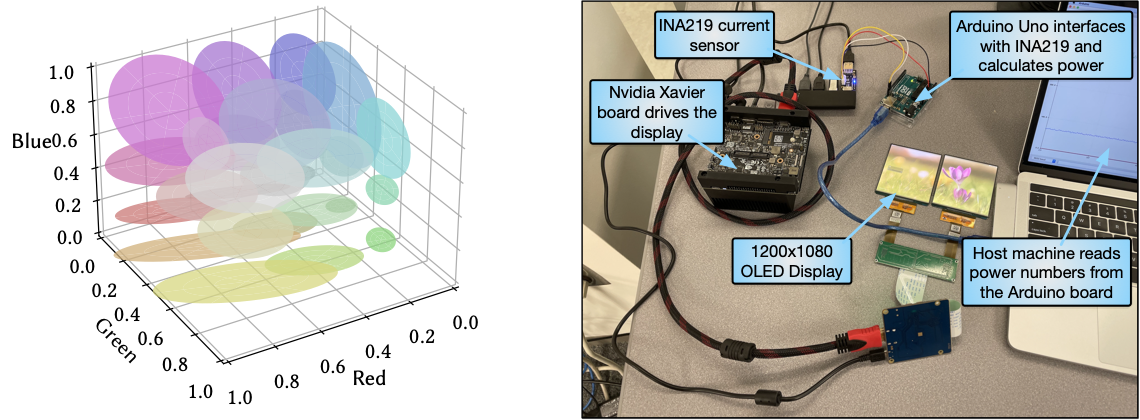
Figure 3: (Left) Each ellipsoid represents the set of colors that are perceptually similar to the color at the center of the ellipsoid. Data are for eccentricity of 25° and plotted in the linearized sRGB color space. (Right) Custom display power measurement setup.
With both a color perception model and a display power model, we have a constrained optimization problem at hand: modulate colors to minimize display power without affecting color perception. A bit of engineering effort shows that this optimization problem has a closed-form solution that can be efficiently implemented as a GPU shader. In the end, we are able to reduce the display power by 20% with little degradation in color perception (another set of user studies).
One thing that’s perhaps not talked about enough is that foveated rendering requires real-time tracking of eye gazes to dynamically estimate the foveal region. With much recent progress (including processing inside image sensors), eye tracking is becoming much more accurate and efficient. But as a transitory solution, many VR headsets today such as Oculus Quest avoid eye tracking by implementing Fixed Foveated Rendering, which assumes that you are always looking at the center of the field of view.
Compression
Immediately following foveated rendering, we can also talk about foveated compression: if a video is to be watched by humans, there is probably not much need to preserve high peripheral quality during video compression. DeepFovea combines foveated rendering and compression: during rendering the periphery is only very sparsely rendered (i.e., encoded) for higher speed and lower data volume; later a DNN takes the foveated image and reconstructs (i..e, decode) a full-resolution image.
A similar, and perhaps more widely explored, idea is saliency-based compression. Informally, saliency refers to stimuli in the scene that attract our attention. Our visual cortex builds a saliency map from the scene to guide our actions, e.g., gaze shifts. In practical terms, this means users will be more attracted to salient objects when watching a video. We could, thus, prioritize bits to perceptually more interesting visual areas, provided that we can predict scene saliency. Vignette builds a DNN to predict saliency and presents a system for video compression and storage. Our prior work EVR uses inherent object information in videos to estimate saliency and presents hardware codec extensions when saliency information is missing. Image sensing using region-of-interest is a form of saliency-based compression, too.
Imaging
The speed and power consumption of an image sensor is dictated by pixel read-out: reading out fewer pixels both improves the sensing speed and reduces sensing power. Just like human vision, machine vision applications (e.g., drones and robots) do not require high-quality data at the camera periphery. Foveated image sensing is thus a natural idea: sense the center of camera field-of-view (FOV) with high quality at the expense of low-quality periphery sensing.
Foveated imaging can be realized in camera optics and/or sensor circuits. For instance, one might use a (3D printed!) micro-lens array to expose different pixels to different FOV sizes. Alternatively, one might build the sensor circuit with non-uniform pixel shapes and sizes.
A particularly interesting approach for foveated imaging is to integrate two imagers that share the same aperture in a camera. The peripheral imager senses the entire FOV with low resolution, and the other foveated imager provides the “fine high-contrast details and color sensation of a narrow foveated region.” Conceptually, this design is reminiscent of three-chip cameras for consumer photography and multi-chip cameras for astrophysical imaging, both of which use multiple imagers to accurately capture color/spectrum information of the scene. The dual-sensor foveated imaging system has a similar idea, but applies it to foveated imaging. It’s amazing how one principle can be put into very different, but equally inspiring, practices.
Temporal Vision
All the discussions so far are concerned with the spatial characteristics of human vision. The temporal dimension provides many interesting opportunities too. The most well-known aspect of temporal vision is saccades, where our eyes move rapidly when shifting visual attention between targets. Unless purposely trained, e.g., in the military, we simply can’t avoid saccades. Our visual science colleagues at Rochester go to great lengths to measure saccades (amazing photo; you don’t want to miss it). On average, saccades occur 3-4 times per second (more frequent than heart beats) and last 20 ms – 200 ms each time, amounting to as many as 15 frames on a 90 FPS device.
Interestingly, human vision during saccades is momentarily blind, a phenomenon widely known as saccadic suppression. Application researchers use saccades to realize many interesting ideas, such as infinite walking in VR. I’m sure, before long, we will see systems work that exploits the perceptual blindness during saccades to reduce computation.
A related phenomenon is blink: our visual perception is also suppressed during eye blinks. Vision research has shown that humans are functionally blind for about ten percent of the time due to blink-induced visual suppression, another opportunity to shave some computation cost.
Finally, keep in mind that the visual stimuli are generated from the displays, which have finite refresh rates. A low refresh rate reduces the computation and display power but introduces many artifacts such as flickering and blur (low refresh rate is the main reason moving objects look blurry to you on many TVs). A high refresh rate, in contrast, increases the computational load. This contention has led to recent work on variable refresh rate systems.
Wetware-in-the-loop Visual Computing Systems
The moral of the story is that we have a better chance designing efficient visual computing systems by integrating wetware in the loop. As visual scientists keep questing for the fundamental operating principles of the HVP, systems researchers can help accelerate the rate of progress and increase the impact using our software/hardware optimization expertises. Many obvious questions follow: How to build lightweight computational models? How to leverage imperceptibility for memory compression? How to coordinate the accelerators under the perceptual constraints? How to build a proactive, rather than reactive, system that reconfigures itself by predicting human (visual) perception? Integrating a wetware model into open-source software stacks can go a long way in helping answer these questions.
Perhaps the most important question we should ask is: what are the principled abstractions of the multifaceted HVP that we should expose the computer systems to? Without a doubt new phenomena in HVP beyond what are discussed here will be discovered and lend themselves to new systems opportunities. Having principled abstractions avoids the endless game of chasing after yet another new phenomenon.
About the Author: Yuhao Zhu is an Assistant Professor of Computer Science at University of Rochester. His research group focuses on applications, algorithms, and systems for visual computing.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
- 1Sharp readers like you might have noticed that the rod density is almost zero at fovea. This is because the rods and the cones have to compete for the physical area on the fovea; high cone density there necessarily translates to low rod density. Why that’s so is anyone’s guess, but I’d favor an evolutionary explanation: we are evolved to see better during daylight, since we can’t see much at night anyways. Beyond fovea, rod density first increases and then decreases. This means when you try to see something in a dark environment, don’t focus straight at it; instead, place it somewhere at 20° of your visual field!

{kind=link}