
The demand for computing performance continues to grow exponentially in part due to video and machine learning processing for applications like augmented/virtual reality and self-driving vehicles. However, the underlying advances (Moore’s Law and Dennard Scaling) that have sustained generations of improvements in performance have been faltering.
In our view, computer architects and scientists should step up to think creatively to achieve breakthrough performance at greater efficiency. This blog post reflects on past successes via transistor parallelism and introduces Accelerator-Level Parallelism (ALP). ALP is a “knob” for achieving better performance in future computer systems. ALP is emerging in some systems, e.g., mobile systems on a chip (SoCs). It has the potential to transform future systems, provided that the community addresses the challenges we identify.
X-level Parallelism
As technology provided more and better transistors, computer architects transformed the transistor bounty into faster processing by using transistors in parallel. Effectively using repeated transistor doubling required new levels of transistor parallelism, much as repeated doublings of salary would demand new ways of spending money (not that we academics would know). Figure 1 depicts the different levels of parallelism used (on the y-axis) over many decades (on the x-axis) with black text for niche success and green for wide success:
- Bit-level parallelism (BLP) performs basic operations (arithmetic, etc.) in parallel; it was common even in early computers and later enhanced, e.g., with larger word sizes.
- Instruction-level parallelism (ILP) executes logically sequential instructions concurrently with pipelining, superscalar, and increasing speculation.
- Thread-level parallelism (TLP) uses multiple processor cores, which initially started with discrete processors and later-on got integrated as on-chip cores.
- Data-level parallelism (DLP) performs similar operations on multiple data operands via arrays and pipelines before broad general-purpose GPU success.

Figure 1: A snapshot of parallelism over the years, showing how the various forms of parallelism were exploited through different types of architectural mechanisms.
We make five observations from this parallelism history:
- Repeated transistor doubling motivated the invention of new parallelism levels. BLP and ILP, by themselves, cannot use billions of transistors.
- Levels achieve success faster when they are mostly transparent to software, such as in the case of BLP and ILP. Even hardware-only innovations often exploit deep software understanding, as is the case with ILP.
- Levels can take deep thinking over decades to mature, especially when they affect the software stack. It took DLP and TLP from the 1960s to the 21st century to flourish. DLP, in particular, morphed several times before its broad adoption and success under the GP-GPU Single-Instruction-Multiple-Thread (SIMT) guise.
- The end of Dennard scaling (shown in red in Figure 1) forced the use of levels that warranted substantial software-visible changes in the case of DLP and TLP.
- Not shown in Figure 1 are the concurrent innovations in levels of the memory hierarchy that also consumed the transistor bounty and one co-author’s attention (Hill).
As we explore and develop the next level of parallelism, we should be mindful that ubiquitously-successful abstractions require careful analysis-driven synthesis, coupled with lots of iteration to refine.
Toward Accelerator-level Parallelism (ALP)
In this blog post (and in Figure 1), we assert that another major parallelism level is revealing itself as time progresses: Accelerator-Level Parallelism (ALP). We define ALP as the parallelism of workload components concurrently executing on multiple accelerators. Each accelerator is a hardware component that executes a targeted computation class faster and usually with (much) less energy. Already today, many systems–especially Systems on Chips (SoCs)–in mobile, edge and cloud computing exploit ALP by concurrently employing multiple accelerators, even as all of these accelerators internally employ one or more of BLP, ILP, TLP, and DLP.
Modern applications are being increasingly driven by sophisticated data flows, where application tasks map to different accelerators. Figure 2 shows an example of a 4K, 60 frame-per-second video capture usecase with two paths. One path goes to the display, rendering real-time content to the end-user, and the other path goes to flash storage to save the content for offline viewing. This simple example, which is commonplace in mobile smartphones, exhibits ALP with multiple accelerators in concurrent use: ISP, GPU, Video encoder, and DSP. Hidden behind the scenes, the CPU cluster (not shown) orchestrates the dataflow between the accelerators.
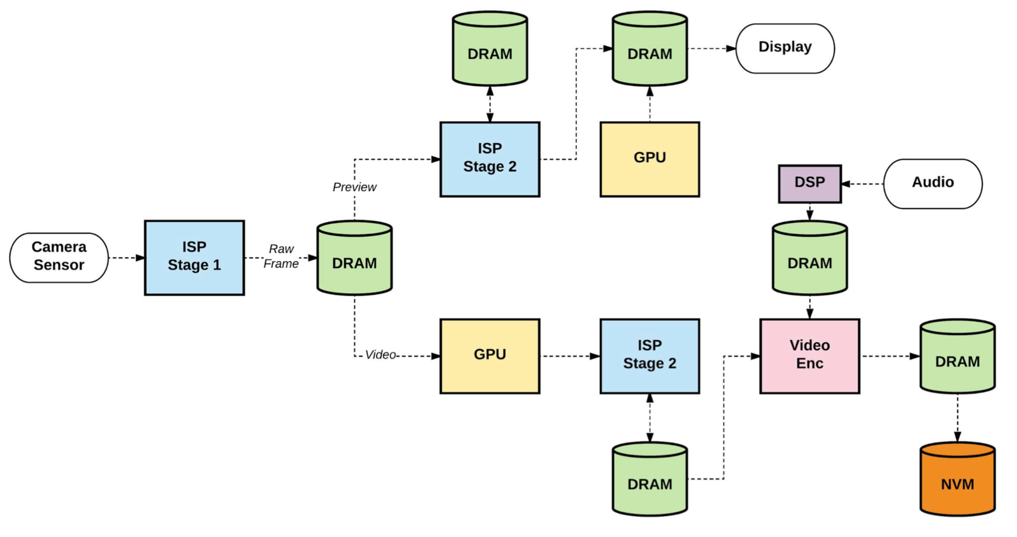
Figure 2: ALP in action in a 4K, 60 FPS video capture usecase on a smartphone
(Source: “2 Billion Devices and Counting: An Industry Perspective on the State of Mobile Computer Architecture”)
Emerging workload domains such as AR/VR and autonomous driving are even more data flow driven with plentiful ALP. Figure 3 shows the high-level concurrent tasks for autonomous driving. The perception stage continuously fuses sensor data to detect objects (pedestrians, cars, etc.). The prediction model predicts the trajectories of the detected objects so that the planning module can use that data along with the high-definition (HD) maps to generate motion trajectories for the car. Finally, the control module generates the CAN bus commands to actuate the motors and create physical motion. All of these tasks (and their sub-tasks) serve a single workload—autonomous driving—but underneath the hood, the application is comprised of multiple, concurrent tasks.
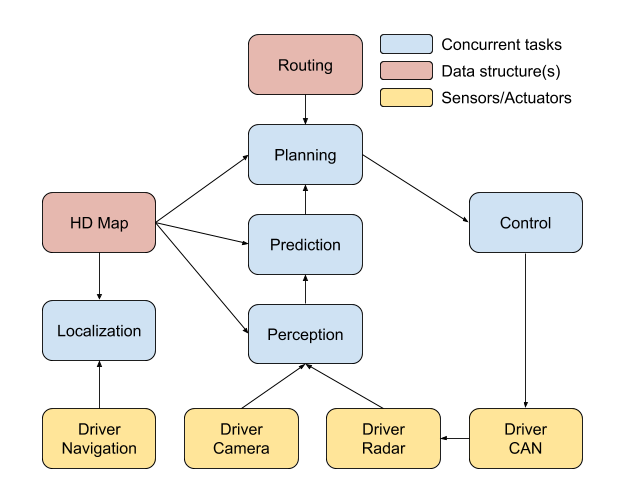
Figure 3: High-level overview of an autonomous driving framework.
(Source: Adapted from Apollo)
ALP exploitation for better latency and power efficiency is critical for applications like autonomous driving to move beyond some prototypes with too many power-hungry components. This process has already begun. At Hot Chips 2018, NVIDIA presented the Xavier SoC with multiple accelerators specially designed for “autonomous machines.” At Hot Chips 2019, Tesla presented its “Full Self-driving Computer (SDC)” that couples safety and other real-time tasks (like Figure 3) with two 40-Watt SoCs. Each SoC includes a neural network processor (NPU), an ISP, an H.265 video encoder, a GPU and multiple CPUs. These accelerators operate concurrently (i.e., ALP) to effectively support the numerous feeds from the cameras, radar, IMUs, wheels, steering wheel, ultrasonic sensors, etc.
Toward an ALP “Science”
While point solutions like NVIDIA’s Xavier and Tesla’s SDC are impressive, we see a general lack of science for exploiting ALP more broadly. We must develop a systematic set of methods for exploiting ALP. ALP as an abstraction that enables lower-level implementation freedom, similar to how BLP, ILP, TLP, and DLP allow us to develop a variety of microarchitecture solutions that exploit their characteristics. Hence, ALP is about the integration of multiple accelerator blocks into a system, mapping and scheduling the tasks onto the individual accelerators intelligently, while allowing flexibility and freedom at the underlying microarchitectural level for accelerator design.
To foster ALP progress, we charge the community to deeply explore four accelerator thrusts that are far more overlapping than separate (see: http://arxiv.org/abs/1907.02064):
- The system-level architecture design space is large for accelerators. How do we identify which accelerators matter the most? How do we automatically “generate” and size those accelerators to enable significant accelerator reuse? We need frameworks that can automatically make recommendations for accelerator designs.
- Many accelerators are running concurrently, and they compete for shared resources. As such, they tend to impose severe shared resource demands from the architecture (e.g., DRAM/network-on-chip bandwidth). Hence, we will need to understand how concurrent execution affects the overall system performance in a large SoC.
- Accelerators communicate logically with one another, but more often than not, accelerators cannot communicate with each other directly. Instead, they communicate via main memory (or shared caches) coordinated by the CPU. Handshaking between the CPU, accelerators, and memory leads to performance slowdowns and adds energy consumption. Significant effort is needed to reduce data movement in SoCs and improve point-to-point communication.
- A challenge that lurks in the dark is that programming for ALP is hard. Many accelerators are programmed in their preferred framework and treated as the sole accelerator unit in the system. We must expand our thinking beyond a single accelerator, and think of programming models that treat accelerators as a collection of execution units so that we can compile/map tasks down to maximize accelerator concurrency and efficiency. We need new programming models, software libraries, and packages that ease us into the broad exploitation of ALP.
“A New Golden Age for Computer Architecture.”
As John Hennessy and David Patterson asserted in their 2018 Turing Award Lecture, it is indeed “a new golden age for computer architecture.” ALP opens up new vistas for research as accelerators are integrated into complex SoCs. As with BLP, ILP, TLP, and DLP, we expect new paradigms for effective ALP exploitation. We do not know the endless list of possibilities. However, we do know one thing. We are sure that there are at least some hidden gemstones to be found and some significant contributions to be made. So, let’s go ahead debate, discuss and explore ALP!
About the Authors: Vijay Janapa Reddi is an Associate Professor in the John A. Paulson School of Engineering and Applied Sciences at Harvard University. Mark D. Hill is John P. Morgridge Professor and Gene M. Amdahl Professor of Computer Sciences at the University of Wisconsin-Madison. He is the 2019 Eckert-Mauchly awardee, is a fellow of IEEE and the ACM, serves as Chair of the Computer Community Consortium (2018-20) and served as Wisconsin Computer Sciences Department Chair 2014-17.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
