
This post is a much simplified introductory chapter of an open, online textbook, Foundations of Visual Computing. Visual computing is wonderfully broad, touching everything from the sciences of human vision to the engineering of sensors, optics, displays, and computer systems. While each of these areas is well covered in excellent texts, they are rarely explored together in a single, coherent story.
Why bring them together? For architects, the ability to navigate comfortably across both computer systems and traditionally non-computing systems lets us see the whole system at once, finding connections and optimizations that are otherwise not obvious when working in isolation. For instance, a previous CAT post discusses how modeling human visual systems (HVS) leads to more efficient computer systems, and another post discusses die-stacked image sensors as a new playground for computer architecture research. For the scientifically curious, there is joy in understanding the fundamentals even without immediate application. As Edwin H. Land once put it, the true application of science is that “we finally know what we are doing.”
What is Visual Computing?
A whole host of things come to mind when thinking of visual computing. Cameras turn the world into visually pleasing images. Computer graphics algorithms simulate how visually pleasing images are captured as if there was a camera placed in the scene. Computer vision interprets visual information (i.e., images) to infer semantic information of the world (e.g., object categories). Displays generate visual information (i.e., lights) to represent an intended scene. What about Augmented Reality (AR) and Virtual Reality (VR)? Of course; in fact, AR/VR requires all the above to work seamlessly together.
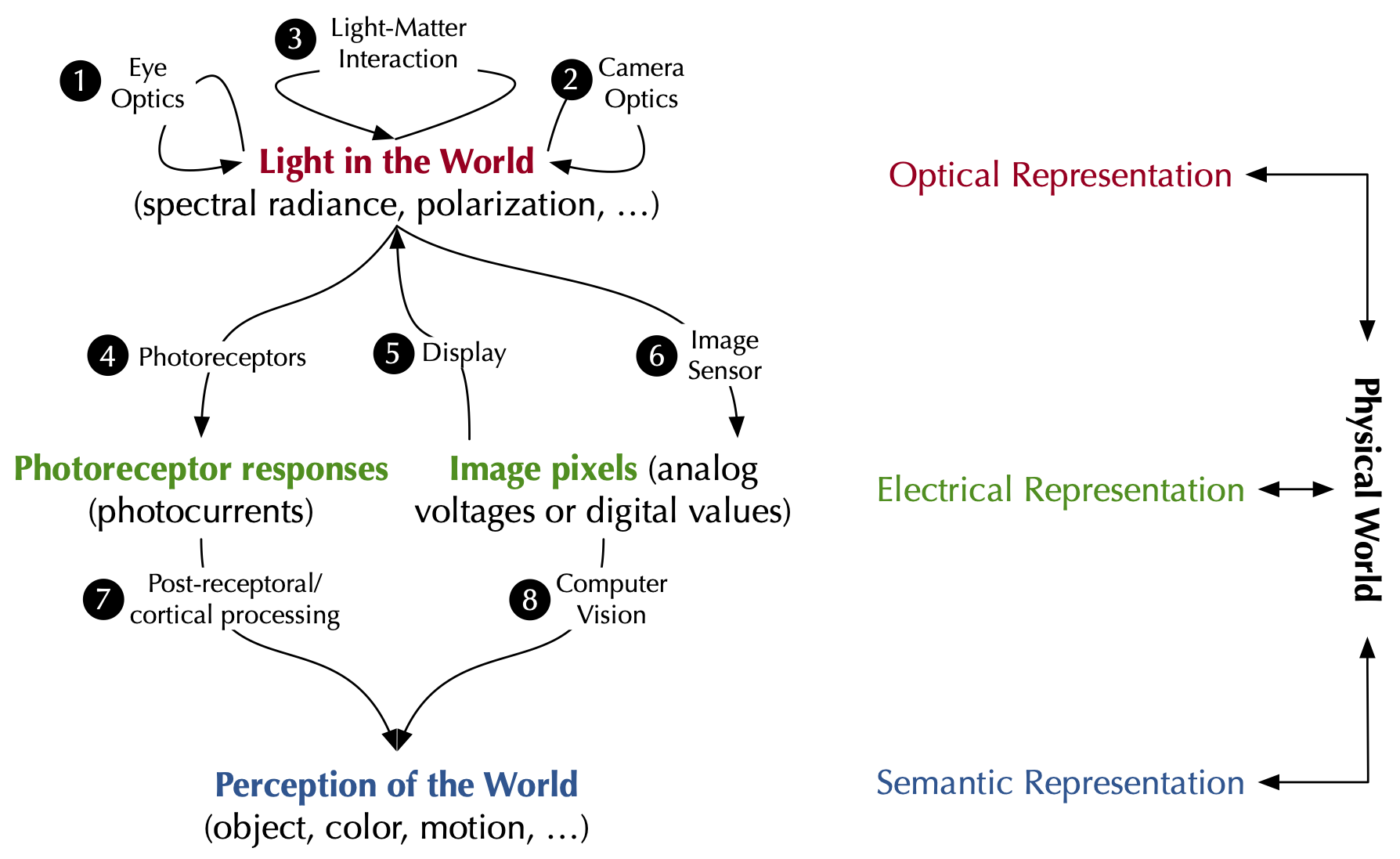
Fig. 1. A framework unifying visual computing. The fundamental building blocks are the signals represented in three fundamental information domains: optical, electrical, and semantic. Visual computing systems transform signals across, and process them within, these domains.
But what are the fundamental connections among the many ideas we can loosely group under the umbrella of visual computing? This post seeks to offer a unified perspective. Fig. 1 highlights the key concepts: (1) representing the physical world across three fundamental signal domains—the optical, electrical, and semantic; (2) processing signals within each domain; and (3) transforming signals across domains. Taking this perspective, we can then start reasoning about the opportunities and limits of building visual computing systems.
Human Visual System as a Visual Computing Platform
Imagine taking a walk through the woods and seeing a butterfly. How does your visual system allow you to notice the butterfly and that it is flying? The inputs to an HVS are lights from the butterfly and the trees in the physical world; they are information represented in the optical domain. The output of the HVS is semantic information, e.g., the color and motion of the butterfly. The HVS extracts semantic information from optical signals through a sequence of signal transformations illustrated as ① ➝ ④ ➝ ⑦ in Fig. 1.
First, lights enter your eyes by traveling through the ocular media in your eyes, such as the cornea, pupil, and lens, and eventually reach the retina. Just before the lights get processed by the retina, the optical signal is already being processed as lights propagate through the eye. This is illustrated by ① in Fig. 1. For instance, the ocular media absorb photons of certain wavelengths and transmit photons that are unabsorbed. The pupil controls how many photons are allowed in at any given time, and the lens bends and focuses lights on the retina — the chief goal of the eye.
The optical image gets transformed into an electrical representation by the photoreceptors on the retina. This is step ④ in Fig. 1. Photoreceptors absorb incident photons; once a photon is absorbed, it could, through the phototransduction cascade, generate electrical responses in the form of photocurrents (or, equivalently, photovoltages) across the cell membrane of the photoreceptor. The responses of all the photoreceptors form the electrical representation of the optical image. The rest of the visual system is “just” a hugely complicated circuit that processes the electrical signals from the photoreceptors. In this sense, the optical to electrical transformation is the first step in seeing.
The electrical signals produced by the photoreceptors are first processed by the rest of the neurons on the retina and then transmitted in the nervous system to the rest of the visual system, first to the Lateral Geniculate Nucleus (LGN) and then to the visual cortex, where the electrical signals undergo further processing and eventually the semantic meanings of the scene arise. You might now realize that the object is, in fact, a red lacewing butterfly (object recognition), that the color of the butterfly is an astonishing bright red and pale brown interlaced by black and white (color perception), and that the butterfly is flapping and flying (motion perception). We lump all the processing stages after the photoreceptor and call them “post-receptoral” processing, which is denoted by ⑦ in Fig. 1.
AR as an Engineered Visual Computing Platform
While the example above is drawn from a biological system, engineered visual computing systems such as an AR glass are fundamentally no different in that they all involve visual information represented in and transformed between different domains.
Take Augmented Reality glasses as an example. Four engineered visual computing systems are involved. The input signals — light — are in the optical domain. These first need to be converted into electrical signals by an imaging system so that a machine vision system can process them to extract semantic information–say, the orientation of a table in a room. The rendering system then simulates light transport to generate photorealistic, context-appropriate virtual objects–perhaps a mug correctly oriented on that very table. Finally, these virtual objects must be transformed back from electrical signals, in the form of pixels, into optical signals by the display system.
An end-to-end imaging system is a complicated sequence of signal transductions involving ② ➝ ⑥ in Fig. 1. Lights enter the camera and are first processed by the optics in the camera with the main goal of focusing lights (②), similar to the eye optics. After the lenses, lights hit the image sensor, whose main job is to transform optical signals to electrical signals (⑥). This is achieved by an array of light-sensitive photodiodes, or pixels, that convert photons to electric charges — using the photoelectric effect — which are then converted to digital values, i.e., image pixels. A machine vision system usually follows an imaging system to interpret the images and extract meanings from the scene (⑧).
Rendering systems generate images, where photorealism is the main goal (although not the exclusive goal). What does it take to render photorealistic images? A rendered image is photorealistic if it almost looks like a photo taken by a camera, so to render something photorealistic, we want to simulate how a photo is taken! To that end, we must simulate two things: 1) how light transports in space before entering the camera and 2) how lights are turned into pixels by a camera, which follows the signal chain in an imaging system.
Comparatively speaking, the second simulation is easier; it amounts to simulating the image formation process in a camera (i.e., ② ➝ ⑥). Since cameras are built by humans, we know exactly how they work, at least in principle. The first simulation is much harder, because it requires simulating the nature: modeling the complicated light-matter interactions (③).
The display performs an electrical to optical signal transduction, turning digital pixels to lights (⑤). The photons from the display then enter the human visual system, and what we have discussed before about the HVS applies. The HVS eventually gives rise to our perception and cognition: we see a virtual mug sitting naturally on a real table.
A Powerful Abstraction
As is hopefully evident by now, a visual computing system enlists the work of multiple stages of signal transformation. At every stage in an application’s pipeline, we have decisions to make. These decisions should not be made locally to optimize for a specific stage. Much of the exciting research in visual computing focuses on jointly designing and optimizing all stages of an end-to-end system. Research in this area can be best understood under an encoding-decoding framework.
Take VR as an example. When developing a VR application, we usually have a scene in mind, e.g., a red lacewing butterfly flying in the woods. We hope that users will perceive the object (butterfly), color (the astonishing bright red and pale brown interlaced by black and white), and motion (flapping and flying), but we cannot simply impose these percepts on humans. Instead, we generate visual stimuli on the display to encode the desired percepts. This encoding is done through a combination of rendering (generating electrical signals) and display (converting electrical signals to optical signals). The entire HVS then acts as the decoder, which ideally would provide the intended percepts to users.
Encoding Capabilities Set the Limits on Decoding
Once we take this encoding-decoding abstraction, we can start reasoning about limits of a visual computing system. The decoder consumes information generated by the encoder, so its utility is fundamentally limited by the encoding capabilities. Ideally, the encoder should faithfully capture all the information in the world. But in practice, encoding is almost always lossy — for a number of reasons.
First, the actual encoding device used in a system, be it biological or engineered, usually uses fundamentally lossy mechanisms such as sampling and low-pass filtering (e.g., integration). Take HVS as an example, where the optical information of the scene is encoded as photoreceptor responses. The photoreceptors sample the continuous optical image impinging on the retina. The sampling rate dictates, according to the Nyquist–Shannon sampling theorem, how well the original optical image can be reconstructed, which in turn limits our ability to see fine details. Even before the photoreceptor sampling, the eye lens blurs signals in the scene not currently in focus, and the pupil, when very small, further blurs even in-focus objects through diffraction, setting the first limit of vision. Blurring is a form of low-pass filtering and is one of the many optical aberrations introduced during the optical signal processing in the HVS.
Second, an encoding device might completely disregard certain information in the incident signal. For instance, the polarization information in the incident light is simply ignored by the photoreceptors, whose responses are, thus, invariant to the polarization states. As a result, humans cannot “see” polarization. Some animals, such as butterflies, have polarization-sensitive photoreceptors. So it is not surprising that monarch butterflies make use of the light polarization for navigation.
Jointly Design Encoding and Decoding
The encoder-decoder abstraction also allows us to design strategies to enhance a visual computing system, both augmenting its capabilities and improving its execution efficiency. For instance, when certain information is not needed for an accurate decoding, it need not be encoded in the first place and, of course, will not participate in decoding, reducing both encoding and decoding costs. Alternatively, if we know what information is crucial for decoding, we can design the encoding system to specifically capture such information. We can also “over-design” the encoder to encode signals in a higher dimensional space than the space to which the information is to be decoded; this essentially introduces redundant samples to improve the robustness to noise.
Ultimately, exploiting these ideas amounts to modeling and, often times, jointly designing the encoder and decoder, considering the end-to-end requirements of task performance, efficiency, and quality — of both the humans and the machine. We will discuss two concrete examples.
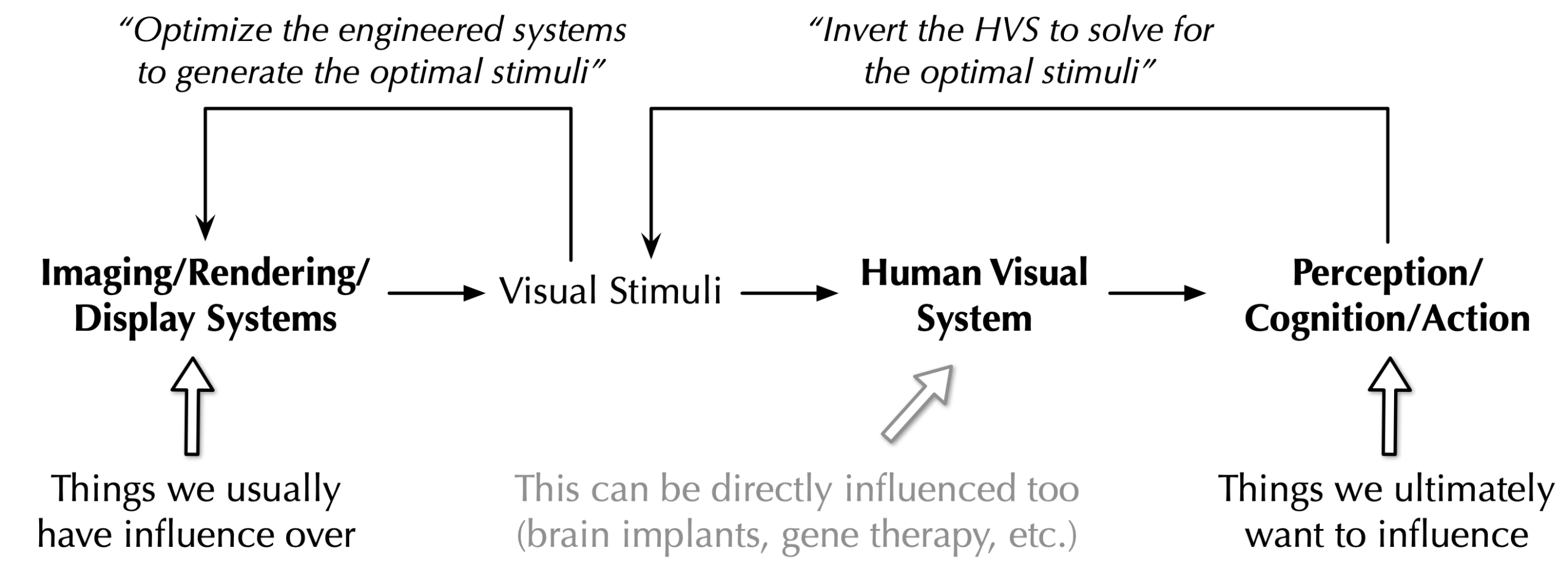
Fig. 2. In visual displaying devices such as AR/VR and smartphones, the engineered systems (imaging/rendering/computer systems) act as an encoder and the HVS acts as a decoder. By understanding the decoding process, we can then better engineer the imaging, rendering, and computer systems to maximize end-to-end performance both for humans and for machines. Brain implants and gene therapy can directly influence the decoding process and must be designed with the encoder in mind, too.
A classic example is to leverage the characteristics of HVS (decoder) to inform the design of visual display systems (encoder) such as AR/VR or even just smartphones. We illustrate the basic idea in Fig. 2, where computer systems (for imaging, rendering, computer vision, etc.) encode information, i.e., a set of visual stimuli emitted by the display, that is then decoded by the HVS. The output of the decoder, i.e., the perception, cognition, and action of a human user, is what we care to influence, but what we actually have influence over is the encoder, i.e., the computer systems.
If we have a good understanding of the HVS, we can then invert it to solve for the optimal stimuli, and from there we can then figure out how to optimally engineer the encoding system to deliver the desired stimuli while maximizing the system efficiency. A previous CAT post summarizes classic work on along this line. As more recent examples, we build a model for human chromatic adaptation and use the model to reduce VR display power; we can also jointly optimize rendering with display leveraging models for the ventral stream in the HVS.
Modern science and engineering have also empowered us to directly influence the decoder itself through techniques like brain implants and gene therapy — just imagine how powerful it would be to directly control a function whose outputs we care about. An example is the artificial retina, an electronic retinal implants that converts optical signals to electrical signals that mimic actual retinal responses or codes; this holds the potential to restore vision to blind individuals. Similarly, these mechanisms must be designed with the encoder in mind in order to deliver the desired output.
About the author: Yuhao Zhu is an Associate Professor of Computer Science and Brain and Cognitive Sciences at University of Rochester, where he and his students are mostly drawn to research at the intersection of human vision, imaging, and computer architecture. More about their work is at: https://horizon-lab.org/.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
