
Sharing computing resources in a microprocessor among multiple tenants (users, tasks) through virtualization, as currently done in datacenters, edge, and embedded environments, conflicts with the need to provide security, isolation, and performance stability. This issue has become highly relevant with the increase in on-chip compute resources arising from advances in silicon and packaging technologies, resulting in chips with more compute resources than the typical needs of individual tenants in many contexts. The need to share hardware resources relying on a hypervisor has been overcome by the abundance of such resources in microprocessor chips. However, mechanisms are still needed to deploy secure server instances with computing capabilities driven by the needs of workloads. Research and innovations are required to develop non-virtualized composable microprocessors that preserve isolation, security, and performance stability, while minimizing inefficiency in the use of compute resources.
Motivation
In the early days, computing systems operated only in single-job batch mode so that a user had access to the entire system. As systems’ capabilities grew, compute resources became time-shared among multiple users, eventually leading to the deployment of virtual machines (VMs). This evolution was well justified by the high cost and compute capacity of the systems. The emergence of microprocessors brought back the option of allocating an entire system (e.g., a personal computer) to a single user. With time, more capable chips again made it possible to share resources through the deployment of virtual machines in microprocessor-based servers.
General-purpose microprocessors used in servers are already reaching 64 to 128 processor cores per chip or socket; servers may have multiple sockets, accelerator devices (e.g., GPUs, Machine Learning (ML) engines, etc.), and so on. While there is a meaningful fraction of workloads that can use all compute resources available in a server, another significant fraction are workloads that require fewer resources. These resources are shared among multiple simultaneous tenants, controlled by a virtualizing hypervisor that also runs on the same resources, with support from capabilities built into the microprocessors.
Although virtualization has been successfully deployed throughout the years, virtualization-based techniques do not provide sufficient isolation among tenants and hypervisor. Partial isolation introduces security exposures, which have led to multiple breaches that have exploited hardware and/or software vulnerabilities with dire consequences. A task can also exploit vulnerabilities to extract information from another concurrent task, as it happened with Spectre and Meltdown. Moreover, lack of complete isolation introduces performance instability because activity by one tenant or the hypervisor on the shared resources may negatively impact the performance of other tenants (i.e., the “noisy-neighbor” issue), an aspect especially relevant for systems that run real-time or safety-critical computations where predictable performance is a top priority and virtualization overhead becomes intolerable.
Systems have been adding capabilities such as Trusted Execution Environment (TEE) to address security issues, memory partitioning to address shared memory capacity and bandwidth, multiple instance GPU to share accelerator resources. Although these additions are helpful, they do not entirely solve the concerns; moreover, they introduce complexity. For embedded/ edge systems that require real-time performance (e.g., safety-related actions on automobiles), lightweight partitioning hypervisors reduce the size of the trusted computing base (TCB) and overhead but do not eliminate security concerns. Similarly, in cloud datacenters cores and cache hierarchy resources are soft partitioned and assigned to each virtual machine, thus addressing some of the performance isolation concerns, while still being susceptible to security attacks.
The alternative to virtualization is allocation of isolated physical resources to tenants, commonly referred to as bare-metal instantiation. In this approach, a physical server with all its compute resources is allocated to a single tenant, so that there are fewer concerns regarding security and performance stability thanks to non-shared resources. The limitation with bare-metal instances is that the granularity of compute resources is determined by physically available servers, forcing tenants to adjust to available resources or instantiate servers larger than needed. This problem is exacerbated by the increasing presence of specialized resources such as GPUs and ML engines in a server even when not needed by the tenant.
An alternative to address efficiency is the concept of composable systems, that is, systems configured by selecting from pools of hardware resources only those needed by a tenant. Currently, composability is primarily focused on rack-level systems and is implemented under the virtualized model, so that concerns regarding isolation arising from virtualization and hypervisor remain present.
An ideal alternative is microprocessor modules able to compose physically isolated servers that operate without a hypervisor, thus combining the benefits of bare-metal systems with composable systems. This approach requires components inside a microprocessor purposely developed, either by augmenting the capabilities of existing components or conceiving completely new ones. Therefore, this blog is a call for research and development of necessary elements to enable the return of efficient non-virtualized servers to mainstream computing in datacenters, edge and related compute environments.
Non-virtualized composable microprocessors
The primary objective of non-virtualized composable microprocessors is their ability to instantiate isolated servers from a high-density flexible collection of on-module resources, homogeneous or heterogenous. Such servers may be instantiated with multiple CPU cores, memory, potentially multiple accelerators, resources that are guaranteed to be physically isolated from each other, thus offering security and performance stability. There is no sharing of resources assigned to each instantiated server. Memory is physically shared, but it is partitioned through hardware-enforced means to guarantee complete isolation in terms of memory capacity, access and bandwidth. External IO consists of physically shared validated devices, also partitioned to ensure isolation in terms of network traffic and bandwidth. An isolated server can even disable its external devices if desired, to provide complete isolation from outside. All external interactions (e.g., debug capabilities, performance monitoring, etc.) are disabled by default; external interactions can only be enabled from inside the isolated server. Hardware enforced isolation is configured by a trusted, external, isolated entity. The hardware resources can be used as small servers or can be combined to compose larger yet still isolated servers.
A composable non-virtualized microprocessor chip is conceptually depicted in Figure 1, although the principles can also be applied to multichip modules. The processor is structured as multiple isolated Slices, each having the necessary resources to implement a general-purpose server: CPU cores, multi-level private cache memory (L1, L2, L3), PCIe root complex, plus optional special functions such as compression, encryption, data mover, security key management, among others. In addition, the processor chip has a Partitioning Memory Controller overseeing a physically shared main memory securely partitioned among isolated servers, a Partitioning PCIe Controller overseeing physically shared I/O devices, support for secure trusted boot of each isolated server, management and monitoring functions.
The hardware resources shown in Figure 1 can be used to instantiate as many isolated servers as the number of Slices in the chip, or all Slices can be aggregated into a large server, or a combination thereof. The smallest server granularity is one Slice. Instantiation of larger servers combines the L3 cache from each aggregated Slice into a larger L3 cache, preserving hardware enforced isolation from other instantiated servers. The Partitioning Memory Controller supports the number of instantiated servers, providing assigned memory capacity and memory bandwidth with full isolation to each one.
Enabling secure systems with the capabilities advocated here requires the development of mechanisms to provide flexible composability while guaranteeing the isolation and performance stability that characterize bare-metal deployments, leading to overall improvement in efficient use of resources and avoiding dependence on a hypervisor. Thorough research efforts are required to evaluate existing and new options that will likely be conceived. Therefore, this is a call for action towards the development of non-virtualized composable microprocessors so that the benefits of bare-metal systems can become available to the generation of compute engines (CPUs, accelerators) with large core counts that no longer need to be burdened with virtualization.
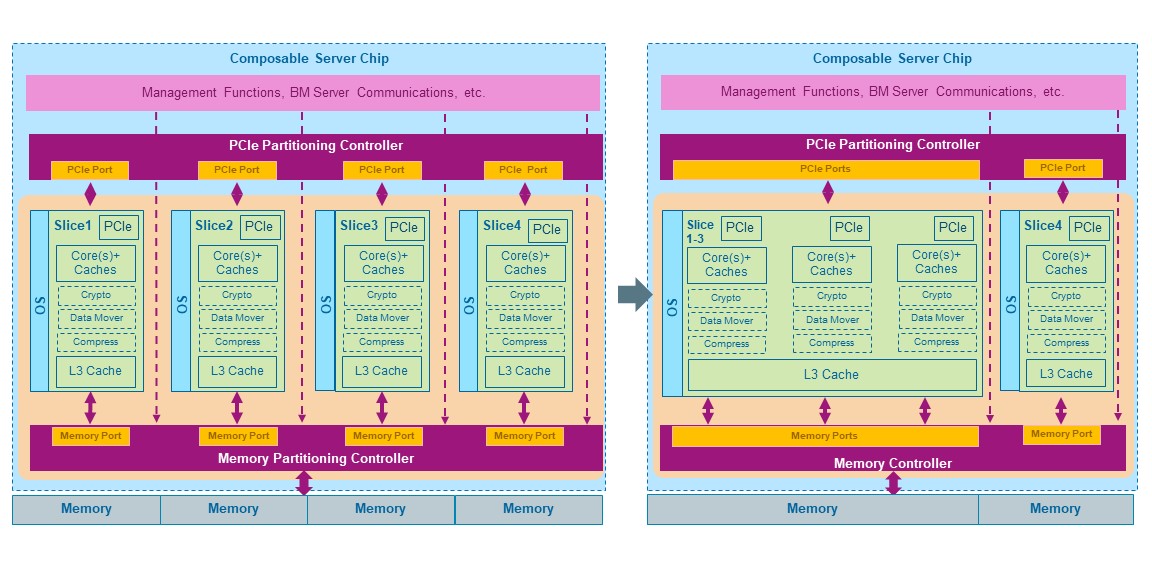
Figure 1: Architecture of composable non-virtualized microprocessor
About the authors: Authors are members of the IBM TJ Watson Research Center, combining many years of expertise in computer systems architecture, systems software, and hardware-software interfaces. Jaime Moreno and Hubertus Franke are Distinguished Research Staff Members, Paul Crumley is Senior Technical Staff Member, and Mengmei Ye is Research Staff Member. Their current research interests are secure performant computing platforms for hybrid cloud infrastructure.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
