
Practical quantum computation may be achievable in the next few years, but applications will need to be error tolerant and make the best use of a relatively small number of quantum bits and operations. Compilation tools will play a critical role in achieving these goals, but they will have to break traditional abstractions and be customized for machine and device characteristics in a manner never before seen in classical computing. Here are three examples along these lines:
First, compilers can target not only a specific program input and machine size, but the condition of each qubit and link between qubits on a particular day! Several recent quantum circuit mapping and scheduling techniques use heuristics to optimize for specific program input, physical machine size and physical topology. Two studies from Princeton (Figure 1) and GATech go even further, observing from IBM daily calibration data that qubits and links between qubits vary substantially in their error rate. These compilers take these daily variations into account and optimize to increase the probability of correct program output. An upcoming follow-on study demonstrates that this approach substantially reduces error rate as compared to native compilers for the IBM, Rigetti, and UMD quantum machines.
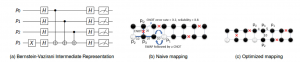
Figure 1: Mapping circuit (a) to avoid bad links an qubits (c) as opposed to the naive mapping (b).
Second, instead of compiling to an instruction set, compilers can directly target a set of analog control pulses. The idea of optimizing control pulses has been long used in practice to determine pulse sequences for one- and two-qubit operations. In fact, a “traditional” quantum compilation flow would compile a high-level language down to a quantum assembly composed of 1- and 2-qubit operations, and then use a table of precomputed pulse sequences to translate each assembly instruction individually. It turns out that we can obtain much greater efficiency if we give an optimizer larger blocks (eg 10-qubit functions) of computation and directly translate the larger block into custom control pulses. This can be done by performing a gradient ascent search from the start state of an n-bit quantum vector to the end state. The gradient ascent solver only scales to about 10-qubits, so the compiler must partition the code into good blocks to give to the solver. There is much work to be done in this direction, but initial results (Figure 2) show that execution time can be reduced by 6-10X.
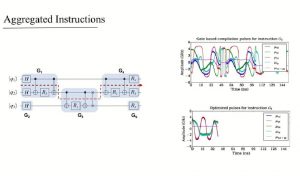
Figure 2: Conventional compilation of a circuit block (G5) to control pulses (upper right). Compiling the entire G5 block to pulses directly using gradient ascent (lower right) shows much simpler pulses and about 3X less time.
Third, instead of using binary logic to target two-level qubits, compilers can target n-ary logic composed of qudits. Recent work with qutrits has been particularly promising. In particular, quantum computations use a lot of temporary qubits (called ancilla). Ancilla bits are particularly necessary when performing arithmetic, since all quantum computations must be reversible (in order to conserve energy and avoid collapsing the quantum system to a classical state). Classical arithmetic can be computed with a universal NAND gate, but a NAND has two input bits and one output bit. It is impossible to reverse a NAND, since one output bit is not enough information to fully specify the two input bit values. The smallest universal reversible logic gate is three input and three output, which can simulate a NAND, but one input and two outputs end up being ancilla. Consequently, arithmetic in quantum computations (which is very common), generates many ancilla.
Qutrits (Figure 3) allow us to essentially generate ancilla by borrowing a third energy state in a quantum device to hold extra information. This approach is so powerful that it can asymptotically change the critical path on quantum circuits when a machine has a constrained number of physical devices. The tradeoff, however, is that the third energy state generally is more susceptible to errors than the first two states used for binary qubits. Fortunately, noise models show that overall error can be decrease with qutrits. This is because computations require less time, and the third state is not always in use.
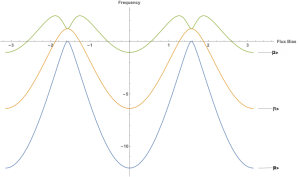
Figure 3: Three energy levels in a transmon superconducting device which can be used to represent qutrits.
Although there already exists an ecosystem of layered quantum software tools and abstractions that serve as an interface between those layers, it is perhaps premature and fallacious to follow a model too similar to classical software. Quantum computing is at a similar stage of development as classical computing in the 1950’s. This is actually exciting, because there are so many interesting problems to be solved. Specifically, resources are very scarce and we are motivated to break abstractions and pay for efficiency with greater software complexity. How much of what we learn in the next five years will carry forward to a future of much larger quantum machines? Perhaps more than we might think, as it would be hard to imagine a future in which qubits and quantum operations are not costly. Some physical details may always be exposed. Even classical computing is regressing slightly towards less abstraction as device variability increases and the end of Dennard scaling puts pressure on architectures to become more energy efficient.
If quantum computing interests you, join us for a snapshot of the state-of-the-art in quantum computing at FCRC at “Quantum Computing: An Industry Perspective,” where industry leaders IonQ, IBM, Google, Rigetti, Microsoft and Intel will each present their unique approaches to quantum hardware and software. You can also find a basic introduction to quantum concepts here.
About the Author:
Fred Chong is the Seymour Goodman Professor of Computer Architecture at the University of Chicago. He is the Lead Principal Investigator of the EPiQC Project (Enabling Practical-scale Quantum Computation), an NSF Expedition in Computing and a member of the STAQ Project.
Many ideas from this blog stem from conversations with the rest of the EPiQC team: Ken Brown, Ike Chuang, Diana Franklin, Danielle Harlow, Aram Harrow, Margaret Martonosi, John Reppy, David Schuster, and Peter Shor.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
