
We need to make it easier to design custom, application-specific hardware accelerators. The potential efficiency gains are enormous, and the cost of deploying accelerators is falling rapidly with the widespread availability of FPGA cards and the increasing accessibility of custom silicon. As the cost of domain-specific hardware itself falls, the difficulty of designing custom accelerators remains a bottleneck.
The mainstream way to design custom hardware is with a general-purpose hardware description language (HDL) like Verilog or Chisel. The thesis of this post is that HDLs, while indispensable for implementing arbitrary hardware, are not the key to making computational specialization go mainstream. We need a new name for an emerging and distinct class of languages that directly address the problem of accelerating applications: let’s call them accelerator design languages (ADLs).
As with software languages, there will never be a one-size-fits-all ADL. We need a diversity of approaches that strike different balances between generality, optimality, and productivity. Industry’s current focus is on high-level synthesis (HLS) tools, which repurpose C-based programming languages with restrictions and extensions to form ADLs that prioritize familiarity for C programmers. This post is a call for more research to explore the broader, C-free design space of ADLs, their compilers, and their accompanying tools. A healthy ecosystem of ADLs can distribute the power of specialized computing to all domain experts, not just hardware designers.
Essential vs. Accidental Complexity in Accelerator Design
Two kinds of factors make accelerator design hard today: there is essential complexity that is truly fundamental to the problem, and there is accidental complexity because the tools are bad. Accelerator design shares fundamental challenges with high-performance software programming, such as understanding cost models and grappling with parallelism, and adds a few more, such as contending with clock cycles and the freedom to customize memory hierarchies.
In an ideal world, the languages and tools for accelerator design would reflect those fundamental challenges—they would embrace the best techniques we have for high-performance and parallel software programming, and they would incrementally ratchet up the complexity to address the unique problems of hardware.
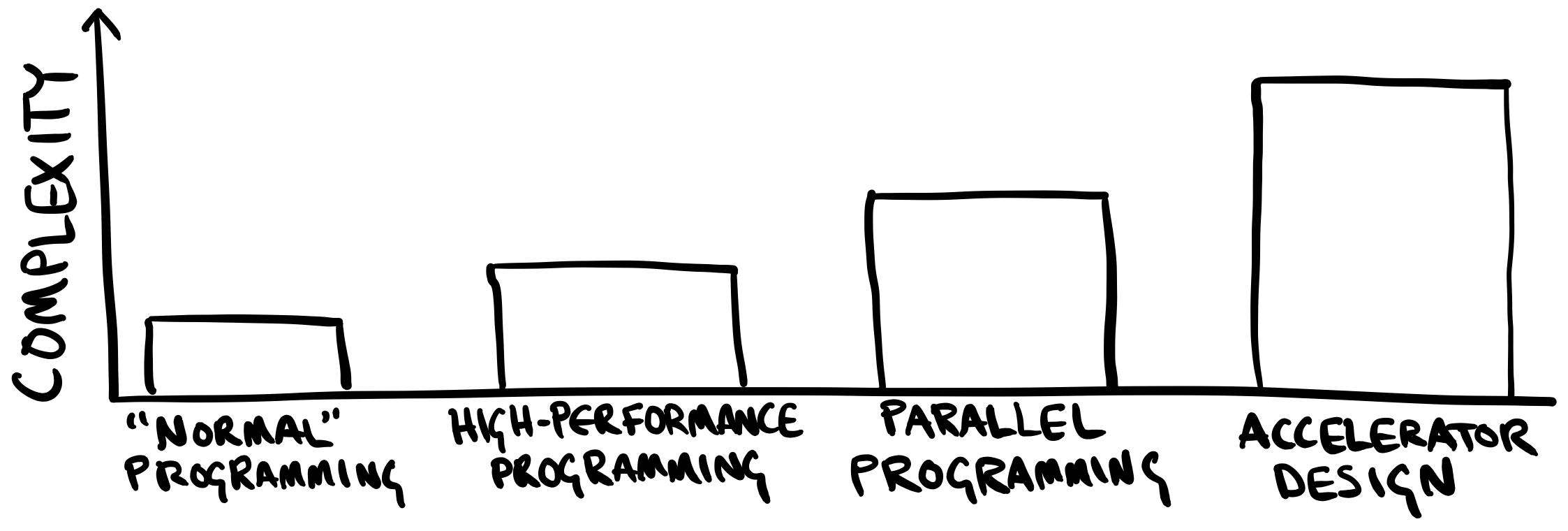
Personally speaking, I’ve found the reality to be far more bleak. When I use a traditional hardware description language (HDL), such as Verilog or Chisel, designing a fast, correct accelerator is not incrementally harder than parallel programming; for me, at least, it is ridiculously challenging by comparison.

In an HDL, the essential complexities of hardware design—fine-grained parallelism, orchestrating many distributed memories, and so on—collide with a host of accidental complexities. Writing in an HDL reminds me of writing entire programs in assembly: I have granular control over performance, but this control comes at the cost of extreme verbosity and brittleness.
The problem is the abstraction level. Too much detail and control over performance can paradoxically make it harder to productively iterate toward a fast implementation. Just as not all high-performance software needs to drop down to the level of assembly, not all accelerator design needs the granular control that HDLs offer.
HDLs have their place: they remain the right tool for the job when designing general-purpose processors, for example. But my thesis here is that their ability to express arbitrary circuits is unnecessary when the goal is to design fixed-function hardware for a specific computation. HDLs are indispensable for standard circuit construction, in the same way that assembly programming today remains indispensable for extreme performance tuning, embedded systems, and other niches. And in the same way that a vanishing minority of software in the 21st century is written directly in assembly, even in performance-sensitive scenarios, HDLs impose more complexity than mainstream accelerator designers of the future should need to deal with.
If hardware acceleration is going to go mainstream, we need alternatives that embrace different levels of abstraction. The key challenge is to identify the key factors in the essential complexity of hardware design—the fundamental factors that make it harder than other parallel programming—and to embody that complexity in a programming model. What would a programming language look like that was designed from the ground up for implementing efficient algorithmic accelerators?
Under the C
Today, the commercially successful answer to this question lies in high-level synthesis (HLS) tools. HLS compilers from Xilinx, Mentor, and Intel can already generate high-quality HDL implementations from programs written in C, C++, or OpenCL. To work around C’s sequential-first, pointer-based semantics, HLS tools extend the language with vendor-specific #pragma annotations or SystemC constructs. HLS research and products have made huge strides in recent years—Harvard’s EdgeBERT and Google’s VCU are two high-profile examples of hardware accelerators that have relied on HLS for significant parts of their design. Anecdotally, hardware designers appreciate HLS tools’ ability to automate tedious tasks in hardware design like scheduling the operators on a data path, constructing basic pipelines to match sequential semantics, and inserting registers.
However, traditional C-based HLS tools have succeeded despite their grounding in C—not because of it. By reusing a legacy software language, they create a semantic gap that in turn yields correctness and performance pitfalls. Recently, researchers at Imperial College London used fuzz testing to find a torrent of bugs in mature HLS tools when compiling even simple C code, and our lab at Cornell identified performance predictability problems where small, seemingly benign changes in the input program can yield wild changes in the generated hardware’s size and speed. While reusing C promises compatibility and familiarity, it also comes at a cost in reliability and transparency.
Defining Accelerator Design Languages
The point of this post is to identify an emerging class of languages that go beyond traditional, C-based HLS. New hardware-oriented languages can explore how to convey the benefits of HLS while shedding C’s baggage: its sequential-first semantics, pointers, and “flat” memory model.
I’ll call these languages accelerator design languages (ADLs) to distinguish them from fully general HDLs. As a research area, ADLs are heating up: Stanford’s Spatial is a Scala embedded DSL for accelerator design, Cornell’s HeteroCL uses an algorithm/schedule decoupling strategy, and our own lab’s Dahlia features a novel type system for controlling hardware resources. Similar efforts are underway in industry: Microsoft has previewed an in-house ADL called Sandpiper, and Google’s open-source XLS builds a custom ADL on a new intermediate representation. Traditional HLS tools themselves even define their own sort of ad hoc ADLs by extending C++ with vendor-specific suites of custom annotations or special libraries.
While these languages have different goals and design trade-offs, they all share a sharp contrast with HDLs. I see two main qualities that define ADLs in contrast to all HDLs, from Verilog and Bluespec to Chisel and PyMTL:
- ADLs do not attempt to enable the design of arbitrary hardware. If you want to design the next great out-of-order RISC-V CPU, you’ll want a proper HDL. Different ADLs have different limitations, but they all rule out some of the power that an HDL offers. Any language that can express a ring oscillator, for example, is probably an HDL, not an ADL.
- In exchange for full generality, ADLs offer computational semantics: to understand what an ADL program does, you can read it like an algorithm mapping inputs to outputs. HDLs, in contrast, have simulation semantics: HDL designs do not denote input-to-output functions, and interpreting them requires global tracking of how events fire and signals vary over time. Again, the precise meaning of “computational semantics” differs for different ADLs. Spatial, for example, relies on parallel functional primitives like
foldandreducewhile Dahlia is a procedural language with sequential semantics. But in every case, the semantics is far closer to a “normal” software language than to a discrete event simulation.
ADLs are also different from domain-specific languages (DSLs). While DSLs are also promising approaches to making accelerator design more accessible in domains like image processing or networking, ADLs are different because they span application domains. As important as DSLs will surely be in the era of specialized hardware designs, we will always need more general-purpose alternatives to fill in the gaps between popular computational domains.
Future Challenges in ADL Design
As with software languages, there will never be one ADL to rule them all—we need a diversity of options that embrace different language paradigms, strike different trade-offs between performance and productivity, or offer special features for specific application domains.
In any ADL design, the central challenge is expressing the fundamental hardware concepts that humans need to be aware of—to convey hardware’s essential complexity without adding too much accidental complexity. In the same way that parallel programming models need to contend with essential concepts like synchronization that do not exist in sequential programming, ADLs will need to design abstractions for the new concepts in hardware implementation that go beyond ordinary parallel programming.
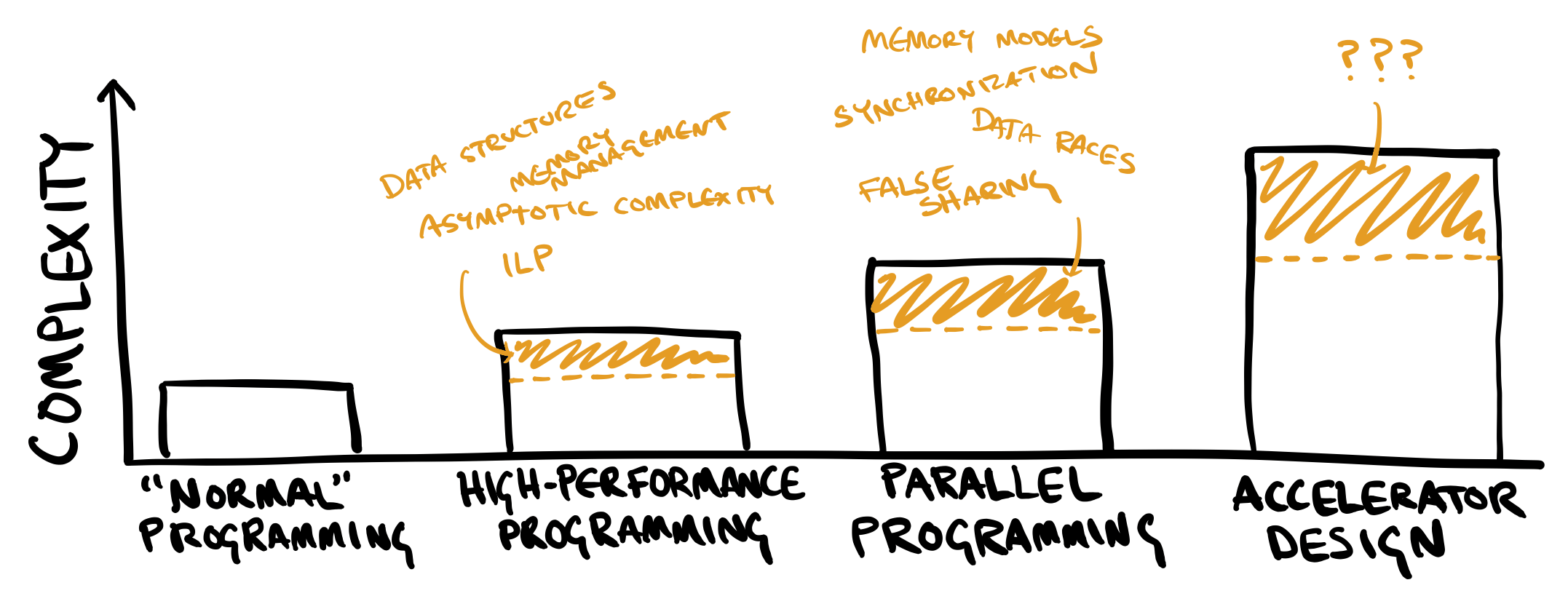
What are those concepts that form the marginal complexity of accelerator design, relative to writing parallel software? Identifying and abstracting these concepts will be the hard work that ADL designers need to do. In my experience, this extra complexity boils down to two main categories:
- Physicality. Perhaps the most fundamental thing about hardware is that computation uses finite, physical resources to do its work. When an accelerator performs a floating-point multiplication, for example, that has to happen somewhere—it needs to dedicate an FPU to that computation. And meanwhile, it needs to take care not to simultaneously try to use the same FPU to do something else at the same time. While CPUs of course also need to allocate computational resources to computations, they do it implicitly—whereas accelerator designs have to manage it as a first-class design concern.
- Time. While parallel software has to deal with a notion of logical time, such as a happens-before relation for ordering events between threads, hardware accelerators need to contend with physical time in the form of clock cycles. Cycle-level timing adds a dimension to ADLs’ complexity, but it also gives accelerators the unique ability to ensure determinism: that a given computation takes 100 cycles, for example, with no exceptions. This level of control is an important advantage over even high-performance CPUs. For many use cases such as datacenter networking, 100 deterministic cycles might be preferable to a CPU that takes 80 cycles most of the time but 500 cycles in rare exceptions.
The next generation of ADLs should focus on establishing abstractions for physicality and time. The design of these abstractions will inevitably need to balance transparency with simplicity. On one hand, ADLs need to be sufficiently simple and algorithmic that their semantics is clear to programmers. At the same time, they need to honestly reflect the cost model of underlying hardware-level concerns so programmers have a shot at optimizing their code. Without enough transparency, ADLs run the risk of impeding programmers from applying their own expertise and insights to iterate toward an efficient accelerator design.
These goals are clearly in tension. Different languages will balance them differently: they can hide more details to make the semantics more algorithmic and software-like, or they can expose more details to make performance optimization more tractable without relying on a mythical “sufficiently smart compiler” to someday arrive. Just as we already have in the wide world of software languages, ADLs should proliferate the design space with different balances for different audiences and different use cases. A single paradigm will not suffice to bring accelerator design into the mainstream—we need a broad and sustained research effort to explore the full range of ADLs that will.
About the Author: Adrian Sampson is an assistant professor in the computer science department at Cornell.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
