
ISCA 2018 was a great success thanks in large part to the dedication of a great team of program and organizational committee members. In this blog, we would like to highlight reflections from the PC review process in 2018.
Our community is growing both in size and diversity of topics. We are pushing the boundaries on service in terms of reviewer load. Meanwhile the number of submissions is on the rise and people collaborate broadly across institutions and geographical boundaries thanks to technology. There are also a number of concerns with the review processes brought up originally by our friend and colleague T. N. Vijaykumar that eventually led to recommendations by a SIGARCH/TCCA delegated task force. We tried a number of experiments the results of which we share in this blog.
Paper Assignments & Reviewer Expertise
There are three key elements that play a role in assigning papers to reviewers: reviewer expertise, topics keywords selected by the authors and conflicts. The first two help improve reviewer assignment while the latter if not handled properly could at best lead to problems later on in the process or at worst result in a bias. We let the program committee members choose their areas of expertise but collected expertise information also offline by crawling DBLP to help improve the knowledge base and for sanity checking. Looking at the abstracts for many of the submissions it also quickly became clear that there was disparity in how authors chose topic keywords for submissions with many only using a single keyword and others using over half a dozen keywords. As such relying on the keywords for submissions became difficult. The combined effect of these problems made any automatic or semi-automatic assignment using HotCRP suboptimal, a tip that Moin Qureshi had also shared with us. So, we chose to hand assign the papers.
We fortunately had scripts from Moin Qureshi and Prashant Nair to automatically create a list of all PC members cited in the reference section of a particular submission by parsing the PDF file. These scripts largely helped but had a few unavoidable shortcomings related to formatting of names in citations with first names abbreviated and aliasing for PC members with popular last names.
Our field has grown in recent years and the areas covered as topics are not only broad but also interdisciplinary. We asked PC reviewers to let us know if their review expertise for a given assignment was a value below the top two scores (i.e., either “expert” or “know the state of the art”). We also asked PC members to propose reviewers. For those papers with low expertise, we solicited external reviews. Phase one papers with fewer than two high scores for reviewer expertise were moved to phase two automatically. Overall, there were a total of 12 papers that had only two high reviewer expertise and two that had only one.
Ranking
Unlike prior years, we opted for not having an extended external program committee, leaving external reviews only for niche areas, for two reasons. First, we wanted to improve consistency in reviews, allow for multiple ranking of the papers throughout the process, and have PC members calibrate their scores and decisions based on a larger pile of papers. Second, we wanted five people in the room for the in-person meeting who had read and evaluated the paper to weigh in on the outcome and not just the usual three PC members which has been common in recent PC review processes. To keep the review load to a practical limit in the absence of an extended external program committee, we also adopted a two-phase review process, which is not common for ISCA but had been successfully tried out by our colleague Margaret Martonosi when she was chair.
With a pile of 24 or so papers, ranking the papers helps not only spread the scores apart for a given reviewer when they are clustered but also address the disparity among average overall merit scores across reviewers. PC reviewers could also judge each other’s score relative to the ranking in case of extreme disparity in average scores. Many PC members also felt after the process that ranking helped them weigh out the relative merits of their assigned paper and calibrate them against each other and the program.
We asked each PC member to rank their papers in a strict numerical order consistent with the overall merit score three times, once for phase one reviews, once for phase two reviews and once prior to the physical meeting. The software we used does not allow reviewers to see each other’s ranks for each paper. We inserted the ranking information manually for each paper as a comment for reviewers. We used the ranking information to establish a discussion order during the in-person meeting with the average overall merit as the tie breaker. For external reviews (17 papers), we used a binning algorithm to create a ranking.
While the use of ranking at least in the current incarnation of our reviewing software is quite tedious, it does have a noticeable impact on both the online and in-meeting discussions and the discussion order which sets the tone for the meeting. Of course, there are a number of other key problems including the reviewer load, reviewer expertise and building history for papers that bounce around. We tried to address the first two with the two-phase review and a targeted external reviewer list for niche areas. The latter is a problem as more and more papers bounce around and would only be properly addressed with a journal-like review model.
Online discussion
Having online discussions for the papers is pivotal in identifying which papers to focus on during the in-person meeting. We managed to arrive at a decision online for 282 papers and had enough time to discuss all remaining papers in the meeting. Having an assigned lead to start the discussion summarizing the merits of the paper as stated in the reviews can help start a productive discussion. Reviewers and discussion leads are often tempted to start a discussion on the negatives and focus on what they didn’t like in a paper so summarizing the positives from all the reviewers helps start the discussion on a positive narrative and lets the reviewers weigh out the negatives against the narrative.
Online discussions are also asynchronous by nature and require constant attention and monitoring by the PC chair(s) to make sure there is progress. We learned from PC chairs that monitoring all discussions is a colossal endeavor for the PC chair(s) and with the increase in the number of submissions is already prohibitive. Relying on discussion leads to help monitor also increases the load for them because the discussion leads themselves are reviewers. Having a larger online discussion window may help but we need better support from the software and more distributed monitoring load to make online discussion productive and practice. For ISCA’18, we ended up sending in excess of hundreds of personalized messages to reviewers reminding them about missing reviews and to engage in online discussion.
Conflicts of Interest
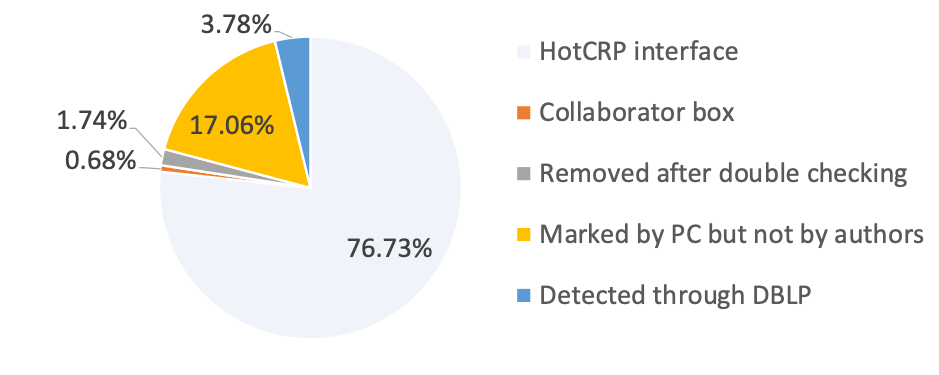
Identifying conflicts is to this day a difficult problem for our community. Not everyone interprets the guidelines the same way. Conflicts entered as text with the prescribed format do not always lend themselves well to parsing. With recent trends towards broad collaboration and authors submitting half a dozen papers, tagging conflicts conservatively adversely affects assignment due to lack of expertise in reviews. We used scripts (from David Brooks and Sam Xi) to create a conflict database. We also crawled DBLP for co-authorship information and augmented what already existed in the database. We then checked with the authors for an explanation of both tagged conflicts we could not resolve and conflicts that we detected that were not tagged. We found 37 papers with tagged conflicts that were not actual conflicts, and 78 papers with missing but detected conflicts. The pie chart depicts the breakdown of conflicts and how they were resolved.
Reviewer Generosity
There has been much discussion and concern in recent years about the disparity in review generosity and its impact on outcome. There is also concern about areas having a bias in reviewer generosity such that the impact is either positively or negatively pronounced when reviewers with similar generosity are clustered.
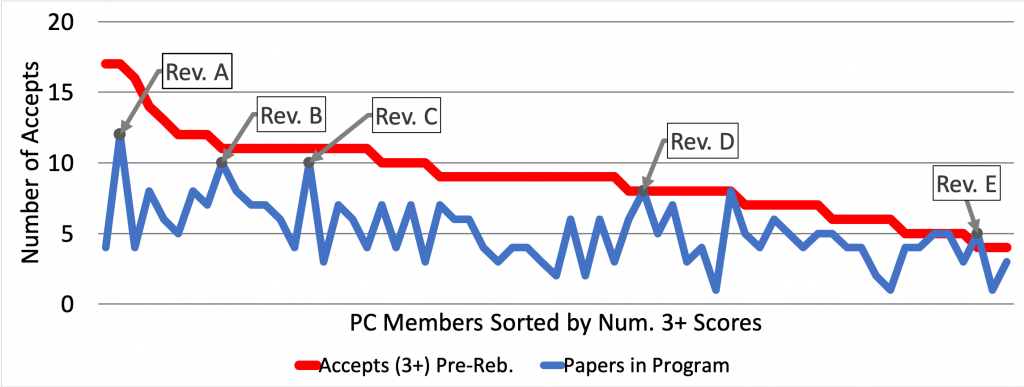
We presented the results in the following figures at the ISCA business meeting in LA. The x-axis is the PC members listed in the order of highest to lowest number of papers with a pre-rebuttal score of at least weak accept (3). The PC members each had between 22 to 24 papers assigned to them. The number of weak accept or better scores highly varies from one PC member having 17 to the lowest being 3. The figure also shows in the blue line the number of papers reviewed by the same PC member that appeared in the program. Not surprisingly that number fluctuates around 5 with a peak at 12 and a low at 1.
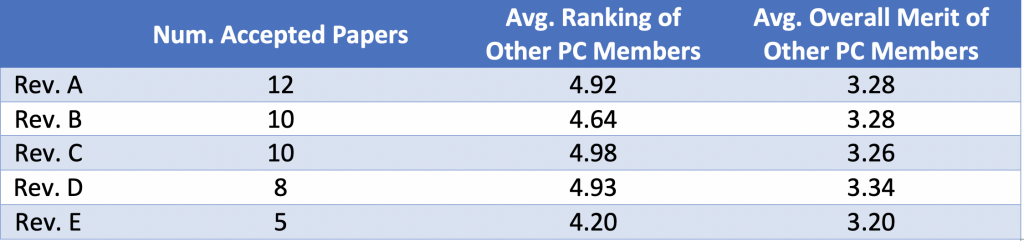
To ascertain whether or not the PC members who reviewed many papers that were accepted (the peaks of the blue series), had strongly influenced the outcome of those papers, we compared the average paper rank and post-rebuttal score for the accepted papers, against the other PC members who had reviewed those same papers. The table below displays the data. We found that other PC members reviewing these same papers had similar positive sentiments, and that the papers were ranked highly – on average, 5thin a stack of 25 or higher.
Finally, we performed an experiment to test if the reviewers with high numbers of accepted papers were often “clustered” together on papers. We first sorted the PC members by number of accept scores given, and assigned them each an ordinal number. For each accepted paper, we computed the average ordinal number of all PC members assigned to it. We found no strong clustering phenomena for the PC members with high numbers of accepted papers, with the ordinal numbers falling close to what is expected from a random assignment of reviewers.
Summary
Moving forward we believe there are a number of ways we can improve the process with technology. Keeping a database of expertise and conflicts that are updated over time can help with the assignment process. Allowing reviewers to rank the papers and exposing the ranking information to other reviewers during the discussion can also help. We also need a better way of engaging reviewers online during discussions than just sending email. We also believe that measures that enable keeping a history of review of information for papers across conferences or instances of the same conference would help improve the review process and load.
Acknowledgements
We thank the Program Committee and the Organizing Committee of ISCA’18. Special thanks go to Sarita Adve, Dave Albonesi, David Brooks, Lieven Eeckhout, Joel Emer, Antonio Gonzalez, Hsien-Hsin Lee, Prashant Nair, Moin Qureshi, Daniel Sanchez, Mike Taylor, T. N. Vijaykumar and Sam Xi.
About the Authors: Babak Falsafi is a professor in the School of Computer and Communication Sciences at EPFL. Mario Drumond is a 5th year PhD candidate in the department of Computer Science at EPFL; his work on the Coltrain project focuses on simultaneously executing machine learning inference and training on the same FPGA device. Mark Sutherland is a 3rd year PhD candidate in the department of Computer Science at EPFL; his work focuses on the hardware and software architecture of servers optimized for low-latency networking.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
