
In a previous blog post, we summarized some advances in optical computing that enable the implementation of low-energy optical-convolutional layers using phase masks and angle-sensitive pixels. Such approaches also present multiple challenges, such as lack of programmability, high area overhead, and limited application. Interestingly, multiple startups (Lightmatter, LightIntelligence, LightOn to name a few) have recently started marketing nanoscale chips for AI which rely on photonics for the core kernels in AI computations. This indicates that photonic computing-based chips are not too far away from consumer use. This blog post looks at the underlying ideas and research behind current nanoscale optoelectronic computing for AI.
Why optical computing might be highly relevant in the future for architects?
Recently proposed chips for AI acceleration have promised a substantial increase in floating-point operations per second per Watt (FLOPS/W). For example, Google TPU offers as much as 23 TOPS for 40 W, made possible through aggressive specialization and optimization of data movement. Moore’s law previously promised a transistor count increase and hence compute increase per unit area of 2x every year. However, future projections look bleak (20 years for 2x improvement). Moreover, as we pack more transistors into a unit area, the power density increases. This has forced architects to resort to AI-specific computing and optimizations to keep power consumption under a limit while ensuring performance, resulting in products such as the TPU. Such approaches are not scalable for the future, especially with the growing compute in recent AI algorithms (e.g., BERT, GPT3). OpenAI reports that since 2012, the amount of computing has grown more than 300,000x. The recent trend has indicated that the amount of computing is expected to only grow as time progresses. Optical computing offers a natural alternative given that one of the most energy-hungry kernels of AI is usually matrix-multiplication, which can be ideally done within the optical domain free-of-cost because performing direct optical domain operations on lightwaves consumes no energy. Here, we look at two approaches to performing nanoscale optoelectronic AI computation.
Nanoscale optoelectronic computing for AI
Nano-printing Approach. In the previous blog post, we briefed an 8 cm2 polymer wafer with patterns based on pre-trained weights. However, 8cm2 is a high area overhead cost to pay in comparison to nanoscale electronic counterparts. Recent work has attempted nano-printing of optical elements on CMOS wafers. One such work proposes compact optical decryptors for both symmetric and asymmetric decryption that are CMOS compatible. Decryptors are perceptrons trained to classify either a single or multiple classes of input secret images. Based on the perceptron model, optical elements are printed on top of a CMOS wafer such that it allows for optoelectronic processing. Each perceptron is a 3-dimensional cylindrical optical element defined by radius and height. The height determines the phase modulation incurred by diffraction of the incoming light and translates to a weighted sum (perceptron operation). A single such structure is called a machine learning decryptor (MLD). A single diffractive layer consists of multiple such MLDs. An overview of GD-TPN for MLD printing is shown below.
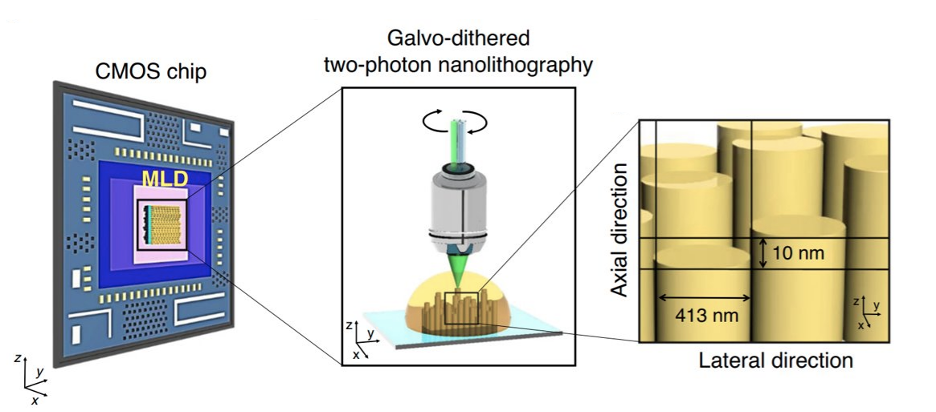
A multi-level perceptron (MLP) can be realized by building a system with multiple such diffractive layers with sufficient physical separation (in the order of a few μm) for highly accurate operation. However, such an approach reduces compactness. At the cost of decreased accuracy, multiple such layers can be stacked together to form a compact multi-level perceptron. This further helps reduce the area overhead of such an approach. The work evaluates two different configurations based on the number of output classes for the MLPs – 3 classes and 9 classes, with a single compact layer consisting of two stacked diffractive layers in each case. MLDs operate in the near-infrared region, keeping the neuron height resolution as low as 10nm with a neuron diameter of 419nm, achieving a neuron density of over 500 million per square centimeter. The match between the experimental and baseline (64-bit) accuracies is found to be 86.67% for the 3-MLD and 80% for the 9-MLD. Accuracy can be increased through digital domain post-processing of outputs from the MLDs.
Mach-Zehnder Interferometer based Approach. A Mach-Zehnder Interferometer (MZI) uses an input beamsplitter to split an input wave into two waves. Weighted phase shifting is done for each of the waves, which are then passed through an output beamsplitter. Such MZIs can be used to implement unitary matrix operations on incoming light sources. A photonic synaptic mesh consists of modulated MZIs to perform matrix multiplication through singular value decomposition (SVD). By programming the beamsplitters and optical attenuators, one can implement weight matrices for incoming light waves. This formed the basis for the programmable nanophotonic processor (PNP). An initial model for a PNP based on interconnected programmable MZIs was proposed in 2017 by Harris et al., achieving an accuracy of 76.7% in vowel recognition compared to a 64-bit baseline of 91.7% for the same neural network. Input audio is pre-processed into high dimensional vectors (feature extraction), then converted into lightwaves for optical AI processing through the photonic integrated circuit.
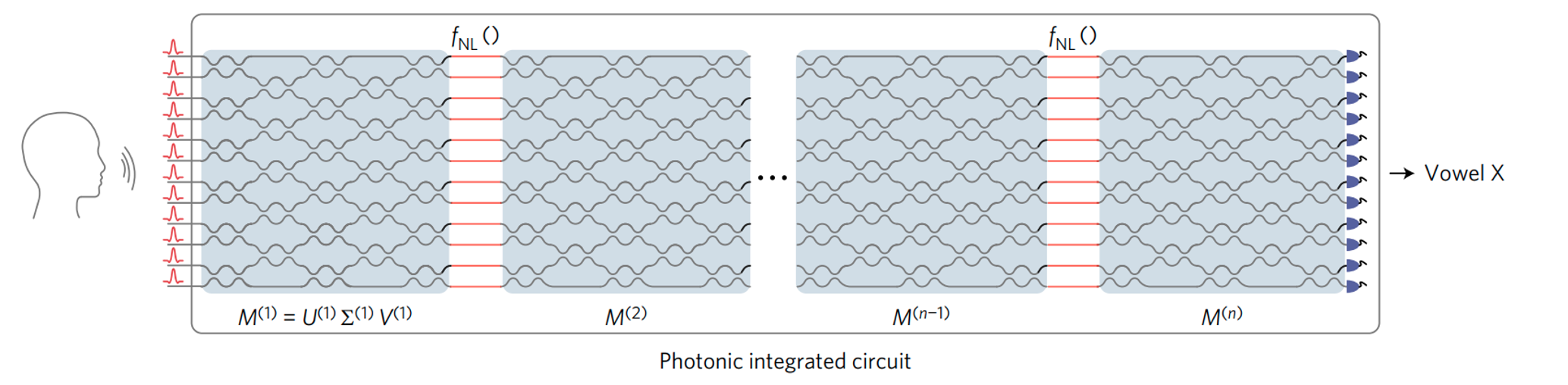
Lower accuracies in the PNP are attributed to non-idealities in optical computing unit such as photodetectors and phase encoders. However, data movement in such an approach within the neural network occurs at the speed of light, with a minimal power consumption of around 100pJ/FLOP. MZIs form an important part of nanoscale optical computing. It is also being actively explored as an option for implementing area-efficient optical random-access memories.
Industry research on nanoscale optoelectronic computing
Lightmatter is a photonic computer company that specializes in optoelectronic processing for AI. Recently, they announced Envise, a chip for AI acceleration. Envise uses a 2D systolic array of MZIs (inspired by the original PNP architecture) with an arrangement and data flow similar to a Google TPU. Computation occurs as light travels from the input to the output of the MZI array within the time of flight for the optical signals of about 100 picoseconds, which allows for much faster operation than the electronic counterparts. Moreover, the energy per FLOP is claimed to be orders of magnitude lower than electronic MACs in state-of-the-art AI chips. Envise enables ultra-high performance inference on advanced AI models (GPT-3, Megatron) as well as staple neural networks (BERT-Large, DLRM, ResNet-50). Lightmatter employs multiple such “Envise” chips to build a server blade (Envise 4-U). Each Envise 4-U server blade offers up to 6.4 TeraBytes per second of optical interconnect for multi-blade scale-out. This is made possible through Lightmatter’s optical interconnect, which enables 1 Terabit per second dynamically reconfigurable interconnect across an array of 48 chips, with a maximum communication latency of 5 nanoseconds. The result is higher bandwidth communication at lower energy and without the costly process of fiber-to-chip packaging. This approach provides chip-to-chip communications with 100 Terabits per second bandwidth. Moreover, with a software stack that allows a compilation flow of a high-level program written with standard deep learning frameworks such as Tensorflow/Pytorch, and initial performance of 3x higher inferences per second than the Nvidia DGX-A100, Lightmatter looks closer than ever to cracking the problem of consumer products based on nanoscale optoelectronic computing for AI. More established companies have also started making inroads in Opto-Electronic computing in the past few years. Intel has recently published two patents regarding its work on photonic processing for AI. One patent proposes Intel’s MZI based optical unitary matrix multiplier and an optical nonlinearity function implemented via nonlinear optical devices, and the second one proposes a heterogeneously integrated photonic IC capable of AI inference in the optical domain.
Implications for Computer Architects
There has been significant development in the past few years in the field of nanophotonics for AI, and given the low power consumption and high speed of such optic-based approaches, it offers a realistic alternative for conventional computing. Building blocks have been proposed for AI kernels such as matrix multiplication and activation, and optical implementation of more advanced AI kernels is an active area of research. Computer architects are faced with the interesting problem of designing optimized architectures using such different building blocks and hence potentially influencing future hardware. However, optical computing is not inherently suited for non-linear computing, thus requiring specialized photonics for different nonlinearities. Moreover, photonic chips require DC analog signals, control systems (such as feedback), interfaces with electronics, and stabilization (in terms of temperature, for example), thus incurring significant overheads. Moreover, the accuracy of optical computing is not yet at par with its digital counterparts. Thus, several challenges remain in the arena of optical computing.
About the Authors: Ananth Krishna Prasad is a Ph.D. student at the University of Utah, advised by Prof. Mahdi Bojnordi. His research is focused on novel memory systems and performance acceleration in Machine Learning applications. Mahdi Nazm Bojnordi is an Assistant Professor in the School of Computing at the University of Utah.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
