Although the computer science community successfully harnessed exponential increases in computer performance to drive societal and economic change, the exponential growth in publications is proving harder to accommodate. To gain a deeper understanding of publication growth and inform how the computer science community should handle this growth, we analyzed publication practices from several perspectives: ACM sponsored publications in the ACM Digital Library as a whole; subdisciplines captured by each of ACM’s Special Interest Groups (SIGs); ten top conferences; institutions; four top U.S. departments; authors; faculty; and PhDs between 1990 and 2012. ACM publishes a large fraction of all computer science research.
In this blog post, we summarize our main findings and how we believe they inform (1) expectations on publication growth, (2) distinguishing research quality from output quantity; and (3) the evaluation of individual researchers. We report more detailed analysis and findings in a paper entitled “Author Growth Outstrips Publication Growth in Computer Science and Publication Quality Correlates with Collaboration”. We include a spreadsheet containing summary data and analysis in the auxiliary materials.
Publication and Author Growth.
The number of computer science publications and researchers are growing exponentially. Figure 1 shows that computer science publications experienced exponential growth (9.3% per annum), doubling every eight years. Figure 2 shows that the number of computer science authors increased even more than publications. We distinguish established researchers, whose publications span five or more years (N=5), with authors of all papers, and authors with N=2 and 10. Authors grew 10.6% per annum, correlating with post-PhD participation in research publications.
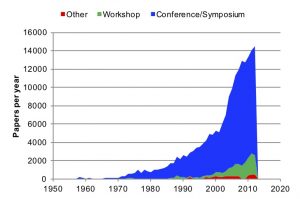
Figure 1. Publications per year in the ACM DL experienced exponential growth of 9.3% per annum between 1990 and 2012.
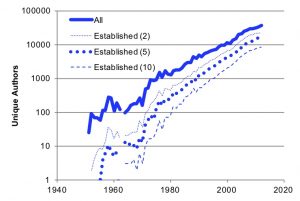
Figure 2. Unique authors per year grew faster than publications, at 10.6% per annum. Established authors with publications spanning (N) years grew at this same rate.
Growth stems from increasing enrollments in research programs and yet there is still unmet demand for computer science graduates and computer science innovations. Growth in computer science researchers is critical for continued progress in computing. Publication practices will need to innovate to keep publication growth from overwhelming the research publication process while maintaining rigorous peer reviewing standards, giving high quality feedback to authors, and moderating reviewer workloads. For example, communities are experimenting with practices such as tiered reviewing, increasing participation in the reviewing process, using machine learning to assist in review assignments, and limiting repeated reviewing of rejected submissions to multiple venues. We need these innovations and more to support individual researcher’s careers and scientific progress.
Distinguishing research quality from output quantity As is well recognized, research output is not and should not be used as a proxy for research quality, but nor is high output an indicator of low quality or vice versa. Research output per author has actually declined between 1990 and 2012 as measured by fractional authorship. Figure 3 shows the weighted publications per author. Each author on a paper accrues a fractional publication as a function of the total number of authors. We plot the 50th (median), 90th, and 99th percentile authors. The most prolific 1% of authors produced just two papers per year when weighted for authorship contribution. Unweighted, this translates to five or more publications, whereas the 90th percentile of authors produce one or two publications per year. Furthermore, graduate student growth continues to outpace faculty growth. Because producing successful graduate students requires publishing with them, each faculty member should be publishing more, but they are not. If research quality has dropped over time, as some perceive, the reason in not an increase in per-author output.
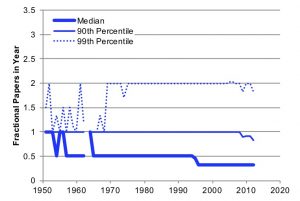
Figure 3. Weighted publications per year per author declined since 1970 for the 50th (median), 90th, and 99th percentile authors.
The top conferences and institutions set research standards explicitly and implicitly, in part because the U.S. computer science professoriate is disproportionately populated by PhDs trained by four U.S. departments, i.e., Berkeley, CMU, MIT, and Stanford [see Clauset et al., “Systematic inequality and hierarchy in faculty hiring networks,” Science Advances, 2015]. We find that authors in these four departments are equally prolific as compared to all authors, measured both in raw publications and weighted by fractional authorship. We then restrict the comparison to established researchers, where an established researcher at N = 5, means their publications spanned five or more years. Established researchers at these four departments are slightly more prolific than all established researchers — once again, suggesting that high output (alone) is not an indicator of poor quality research.
Evaluation of individual researchers We find collaboration is highly correlated with quality. In particular, researchers at the top four institutions collaborate more and papers in top conferences have more authors than other venues in the same subdiscipline. Figure 4 shows the average number of authors per paper has systematically grown and researchers in the top departments collaborate significantly more than all authors on average (p-value<< 0.0001). Furthermore, we find that higher rates of collaboration are strongly correlated with quality. We analyze in more detail the ten largest ACM Special Interest Groups (SIGs): SIGCHI, SIGGRAPH, SIGWEB, SIGDA, SIGIR, SIGSOFT, SIGARCH, SIGMOD, SIGPLAN, and SIGMOBILE. We compare the top venue in each subdiscipline (SIG) to collaboration practices for all venues in the SIG. We find more average authors on top venue papers with p-value < 0.07 for 8 of 10 SIGs. Only two (SIGIR and SIGARCH) were not significantly higher. Furthermore, we add to the evidence that it is unsound to compare publication practices (e.g., number of publications, citations, and collaborations) of computer scientists in different subdisciplines. For instance in 2012, SIGPLAN published 739 papers with 3.13 average authors per paper, whereas SIGCHI published the most papers at 2562 in 2012 and SIGARCH had the highest average authors at 4.00.
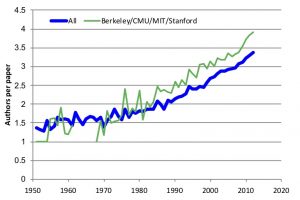
Figure 4. Average authors per paper increased from 1.5 in 1970 to 3.4 for the field in 2012. Authors per paper increased more, to 3.9, at four top U.S. departments.
Collaboration complicates the job of hiring and promotion committees, which must evaluate individuals. Since collaboration correlates with quality and collaboration is increasing over time, these committees should expect successful researchers to exhibit a combination of leadership, shared team leadership, and supporting roles in impactful collaborative research. Instead of giving no credit to collaborative research or forcing researchers to divy up credit, committees should consider magnifying the credit to individuals in highly impactful collaborations. The whole is sometimes more than the sum of the parts.
Closing We were surprised by several of these findings and it would be interesting to see what has happened since 2012. (We were delayed in disseminating this analysis since several fine venues chose not to publish the main paper.) We sincerely thank ACM for providing a complete snapshot of their digital library. We hope these findings spark some new conversations around growth and the value of collaboration.
About the authors:
Stephen M Blackburn is a professor in the Research School of Computer Science at the Australian National University and an ACM Fellow. His research interests include programming language implementation, architecture, and performance analysis.
Kathryn S McKinley is a senior staff researcher at Google, an IEEE Fellow, and an ACM Fellow. Her research interests include programming languages, parallelism, systems, architecture, and cloud computing.
Lexing Xie is a professor in the Research School of Computer Science at the Australian National University. She is a recipient of the Chris Wallace Award for Outstanding Research, 2018. Her research focuses on innovative design and use of machine learning, especially for structured and multi-relational graph data.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
