
Previous posts in the Computer Architecture Today series have explored how the broader adoption of smart NICs is providing applications a mechanism to push computation closer to the data and inside the network stack to hide the latency of accessing remote memory in a data center. This post discusses recent ideas that are being considered in the data management community that aim to define software abstractions for in-network computing and smart NICs.
Why is a new interface needed?
The question that naturally arises is why is a new interface necessary. After all, many common interfaces are already widely deployed that software developers are already familiar with. A natural candidate to consider is MPI, a de facto standard for developing portable and highly parallel applications in the high-performance computing community. MPI is an interface that presents low-level communication functions and couples these functions with higher-level primitives, such as aggregation (reduce) and scatter/gather over user-defined data types. These higher-level MPI primitives are often implemented in hardware and can be evaluated in the switching fabric of a network. The database community has used MPI in high-performance database systems and has implemented algorithms on MPI that scale to thousands of cores.
However, MPI has a number of weaknesses when used for data-intensive computing. First, communication in MPI requires the creation of a process group before any data transfer takes place. However, the communication pattern in data-intensive applications is data-dependent and cannot be not known in advance. Second, MPI adopts a process-centric addressing model, where a process identifier (rank) is used as a destination address for communication. This is not a good fit for services that are designed to outlive the scope of a process and make heavy use of data structure sharing and multi-threaded parallelism. Third, MPI does not allow applications to prioritize among different communications, which is necessary to meet service level objectives (SLOs). Finally, MPI does not have a fault tolerance mechanism, in part due to inherent technical challenges in providing fault tolerance to general applications. Without a clearly defined failure model, data-intensive applications cannot gracefully react to failures.
Another popular choice is the Verbs interface that is widely deployed in InfiniBand and RoCE (RDMA over Converged Ethernet). The challenge is that the Verbs interface exposes a limited programming surface to applications which consists of read, write and single-word atomic operations to remote memory.
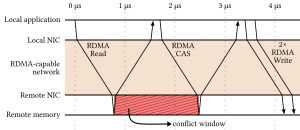
Atomic append using RDMA.
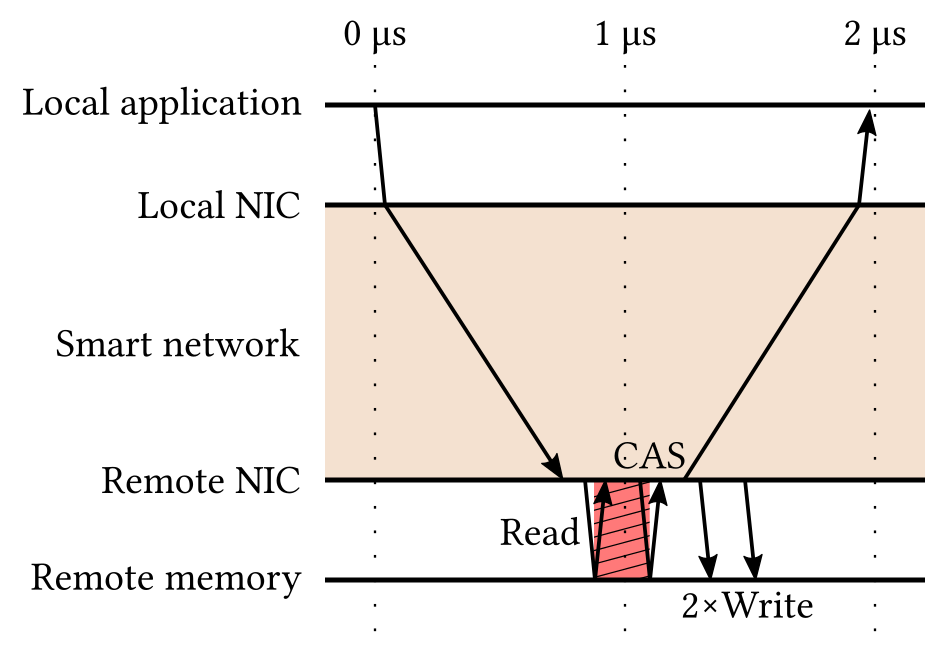
Atomic append in a single round-trip.
Consider the common database operation of inserting a tuple in a buffer. An implementation of this operation would first check if there is enough free space in the buffer, then atomically modify a pointer to allocate memory inside the buffer, then write the tuple and finally mark the entire entry as valid (to detect a torn write). Using RDMA, shown on the left above, one can only perform this operation on a remote page through a sequence of RDMA requests. A read will first check the free space, then a compare-and-swap will atomically allocate memory and then the writes will take place. Overall, completing this operation will require at least 3 round-trips in the network, or at least 5 microseconds even for the fastest networks today. Furthermore, the conflict window for this operation is at least one network round-trip, which practically limits this design to uncontended data accesses.
What is the benefit for data-intensive applications?
Developers of data-intensive applications would like to convey more complex operations, such as append, and issue them in a single round-trip. The remote smart NIC can then evaluate simple processing logic locally and return the answer. In this setting, the entire communication can complete in a single round-trip, which reduces the number of transmitted messages by a factor of 4X. In addition, the conflict window is shortened substantially, as the read and compare-and-swap operations are initiated locally, which will make this design scale better under contention.
Other operations that would be widely useful include:
- ConditionalGather. Traversing common data structures often requires following pointers which requires several lookups over RDMA. Prior research has shown that one can identify the load instructions that traverse linked data structures and execute them within the memory system ahead of the actual computation to reduce overall execution time. ConditionalGather performs the same operation over remote memory: it traverses a pointer-based data structure to evaluate a user-defined predicate and gathers the matching elements in a gather list that will be transmitted back in a single request. In OLTP workloads, ConditionalGather can return visible versions in a single operation. In an OLAP workload that involves a join, ConditionalGather can retrieve all tuples in a hash bucket that match a given key in a one round-trip. Short-circuiting the condition performs projection in the network.
- SignaledRead. Many data structures use locks to serialize concurrent operations. Exposing lock-based data structures over RDMA, however, requires at least three RDMA requests: two operations target the lock and one performs the intended operation. SignaledRead can “elide” these lock operations, akin to speculative lock elision in hardware, and saves at least two messages.
- WriteAndSeal. This operation first writes data to a buffer, then writes to another location to mark the completion of the write. This operation will be used in lock-based synchronization to update data and release the lock in one operation.
- ScatterAndAccumulate. This performs a scatter that involves indirect addressing to the destination through a lookup table. Instead of overwriting the data at the destination, the operation accumulates the transmitted values to what is already present in the destination address. This operation offloads hash-based aggregation in the network without using complex aggregation scheduling protocols.
New abstractions for in-network acceleration
Remote Direct Memory Operations, or RDMOs
In collaboration with Oracle researchers, we are investigating a new interface for data-intensive applications, the Remote Direct Memory Operation (RDMO) interface. An RDMO is a short sequence of reads, writes and atomic memory operations that will be transmitted and executed at the remote node without interrupting its CPU, similar to an RDMA operation. Unlike a fast RPC implementation, an RDMO cannot invoke program functions, initiate system calls or issue additional RDMA requests. Unlike a smart NIC with a complete network ISA, an RDMO cannot execute arbitrary user-defined programs. The RDMO interface extends the functionality of RDMA by providing a mechanism to simultaneously transmit data and execute simple operations on a remote node. The idea is that one can augment the standard InfiniBand verbs in RDMA to support the dispatch of simple data processing logic in a single unit to the remote side which will be executed in one round-trip. One such mechanism can be the Atom abstraction that allows applications to express richer memory access semantics to the hardware.
Abstraction layering and the DPI interface
DPI is an interface description for modern networks that is tailored for data processing. DPI is motivated by the fragility and lack of portability of writing low-level code to leverage hardware acceleration in modern networks. DPI aims to provide higher-level abstractions that applications can more easily use to leverage RDMA and push these abstractions down into networking hardware. In DPI every data movement is represented as a flow. The flow interface is cognizant of the schema of the data and it allows applications to control routing, data transformation, synchronization, coordination and resource management. A lower-level, memory-based interface in DPI permits applications to transfer raw data over the network and allows for more expressive operations to remote memory.
Open challenges
The broadening adoption of smart NICs and in-network processing opens Pandora’s box, as now the network itself becomes an active participant in communication. One practical concern is security, as RDMA bypasses many security safeguards by allowing any node in the network to read or edit memory. In addition, the virtualization of the compute capability of a network is an open challenge which brings questions of fairness and strong isolation when applications concurrently access the network. It is conceivable that defining new abstractions for in-network processing can simplify these problems as vendors can now expose a more limited surface than allowing arbitrary read, write and atomic operations to entire blocks of memory.
About the Author: Spyros Blanas is an Assistant Professor in the Department of Computer Science and Engineering at The Ohio State University. His research interest is high performance database systems.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
