
Hyperscalers are reporting frequent silent data corruptions (SDCs)—a.k.a. silent errors or corrupt execution errors (CEEs)—in their cloud fleets caused by silicon manufacturing defects. Notably, SDCs at-scale exhibit error occurrence rates on the order of one fault within a thousand devices. Meanwhile, hardware manufacturers strive to achieve 100 and close to 0 defective parts per million for the commercial and automotive domains, respectively.
With hundreds of thousands of servers in a large-scale infrastructure, featuring millions of hardware devices—e.g., motherboard, CPUs, DIMMs, GPUs, hardware accelerators, NICs, HDDs, flash drives, interconnect modules—there is a non-negligible probability that SDCs will propagate to and impact system-level applications. This blog post introduces the challenge of SDC at-scale, identifies some opportunities for improved post-manufacture testing, and highlights ways in which hyperscalers and silicon manufacturers can support academic research in this area.
How did we end up here?
Given the degree to which state-of-the-art post-manufacture testing underestimates defective parts per million, there is a clear need for improvement. So, what is the state of the art in post-manufacture testing?
One thing that CPU vendors like Intel or AMD do is scan-based testing. This is a design for testability (DFT) approach where an IC’s flip-flops are modified in order to treat a complex sequential circuit like a combinational circuit, by directly accepting test stimuli as input and directly observing combinational logic outputs. Scan chain testing has some obvious benefits: it is systematic, backed by automated test pattern generation (ATPG), and supports (scalably) reasoning about coverage metrics—e.g., stuck-at, stuck-open, transition, path delay, N-detect, bridging, cell-aware, gate-exhaustive.
Beyond scan testing, hardware vendors also develop (often proprietary) system-level/functional tests. Unfortunately though, attaining high coverage for system-level tests is computationally difficult due to large designs and test lengths. Note that, in theory, system-level tests can be evaluated with respect to the same coverage metrics as scan chain tests, since they ultimately drive a design’s combinational logic with various input combinations. However, computing this coverage is also difficult. Example of a past attempt: Intel’s Blast fault simulator is a stuck-at fault simulator which supports reasoning about stuck-at fault coverage of system-level tests.
Improving post-manufacture testing
So, how can we improve post-manufacture testing? One thing we can do is improve scan chain testing. This includes improving test pattern generation to produce more thorough tests (e.g., using new test thoroughness metrics, as in PEPR, Li et al., IEEE Intl. Test Conf., Sept. 2022) but also enabling continuous scan chain testing post-deployment. Notably, post-manufacture testing is highly limited in duration (on the order of seconds or maybe minutes) due to manufacturing floor cost constraints. Moreover, extremely thorough test patterns will likely require much longer manufacturing test time. Concurrent Autonomous chip self-test using Stored test Patterns (CASP) addresses this shortcoming by enabling a system to test itself concurrently during normal operation without any visible downtime to the end-user.
Another thing we can do is improve system-level tests, which are likely more convenient to schedule in a datacenter setting. As one option, if we derive system-level tests from datacenter applications, the tests themselves can do useful work, making them less intrusive. And as another option, if we derive functional tests from RTL-level or other hardware models, we can more thoroughly and scalably address coverage. Google’s SiliFuzz approach, which uses fuzzing coverage on hardware emulators and disassemblers as proxy for coverage on real hardware, exemplifies the latter idea. The intuition behind this approach is that if a particular input sequence triggers interesting behavior (new coverage) in the proxy system, then the same input may also trigger interesting behavior in a real CPU. Moreover, advances in formal verification of processors and accelerators appear to make system-level test generation based on RTL-level fault models feasible.
Ultimately, tackling SDC at scale requires a layered approach based on improved scan chain and system–level testing working together. Moreover, the complexity of the SDC challenge is likely so great that creating tests to detect all possible manufacturing defects will be impossible. Thus, there is also a need for novel research on resilience and fault tolerance techniques that accounts for observed SDC errors in production hardware.
This blogpost focuses on challenges to designing system-level tests and some plausible solutions. In general, industry is not yet sure what state-of-the-art system-level tests are missing.
Challenge 1: Long Error Detection Latencies
One challenge to effective system-level tests is long error detection latencies—the time elapsed between the occurrence of an error caused by a bug and its manifestation as a system-level failure. One side-effect of long error detection latencies is error masking. Intuitively, for every cycle that goes by in which an error that has occurred is not detected, there is a non-zero chance of the error getting masked (see Figure 1). This means that errors have a high probability of escaping detection.
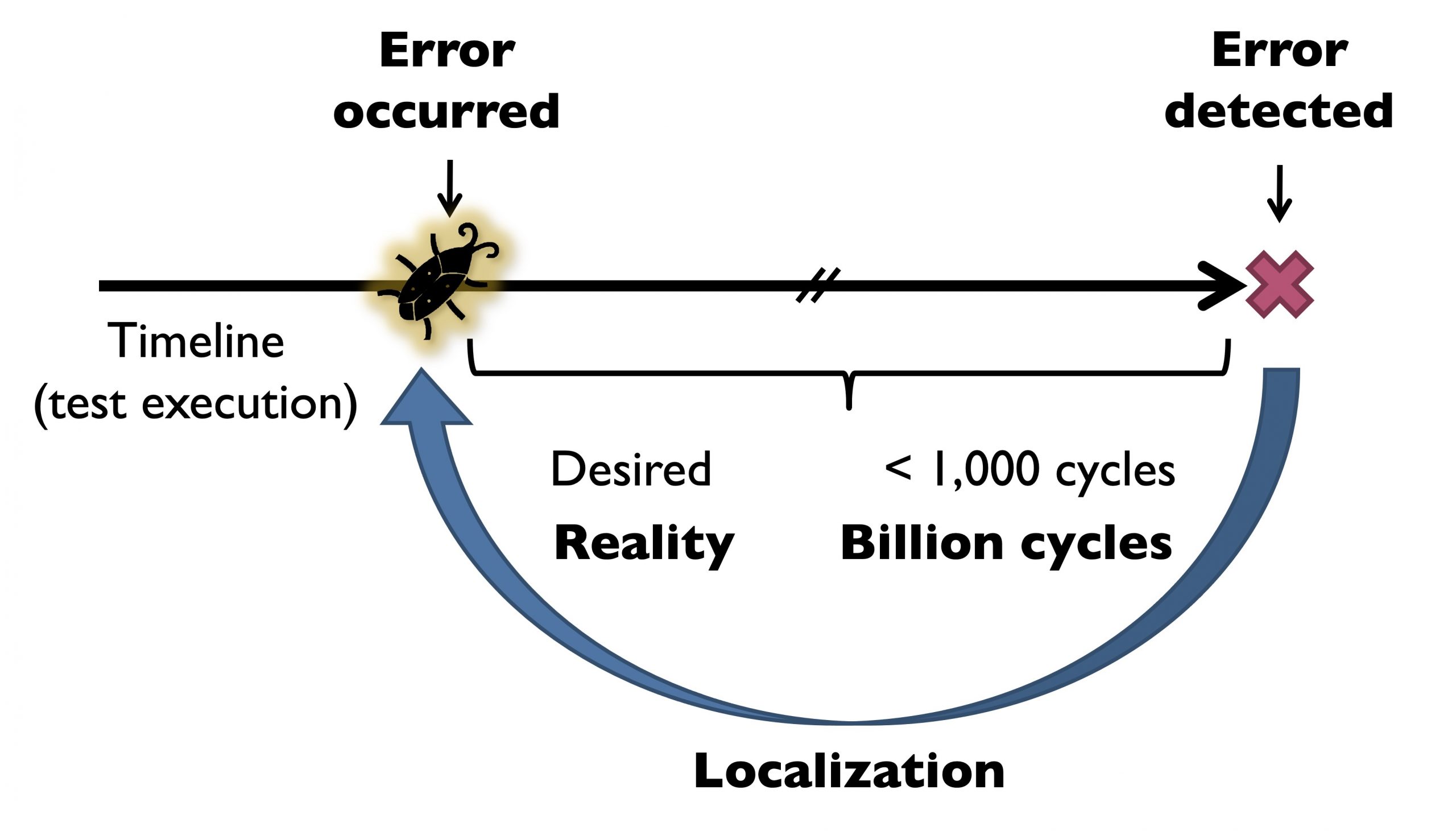
Figure 1. Error detection latencies result in error masking and hard-to-root-cause bugs. Courtesy of S. Mitra.
Another side-effect of long error detection latencies is difficulty in localizing and root-causing bugs when the resulting bug trace is on the order of billions of cycles. Figure 2 presents some data from Cisco which shows that up to 60% of the time when an error was observed, the incorrect chip was identified to be faulty. Moreover, even when a defective chip is correctly identified, subsequent testing may not reproduce an error, a scenario referred to as no trouble found (NTF). Shorter error detection latencies enable hardware designers to pinpoint more concise bug traces, capable of exposing errors. To address these challenges, we can look to prior work on reducing error detection latencies, like the Quick Error Detection (QED) approach, which transforms post-silicon validation tests into new tests which more frequently check for the presence of errors.
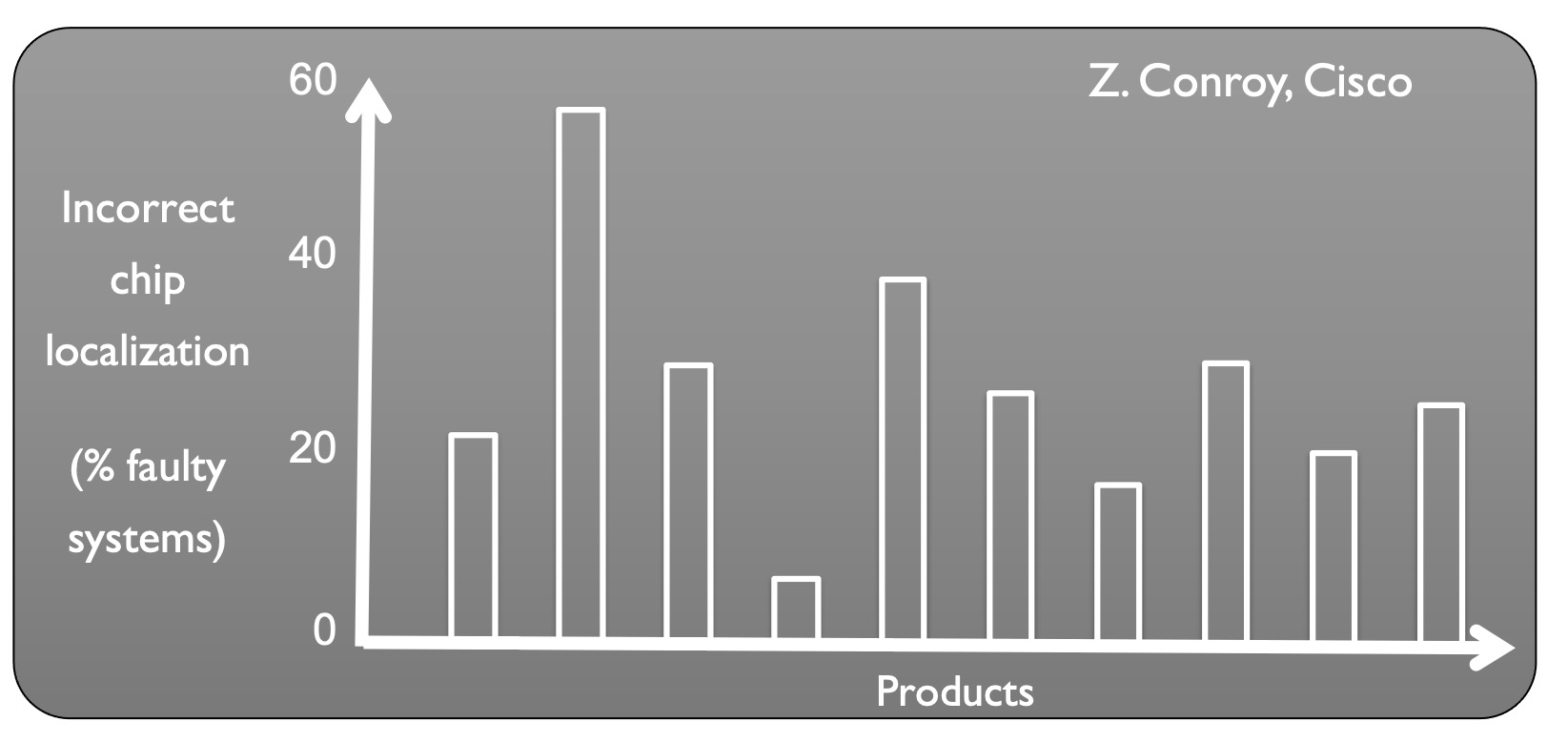
Figure 2. Incorrect faulty chip localization up to 60% of the time. Courtesy of Z. Conroy and S. Mitra.
Challenge 2: Suitability of System-Level Test Patterns
A second challenge is that it is unclear to what degree system-level tests used by hardware vendors are representative of typical datacenter system loads. For example, Intel has open-sourced a testing framework, called Intel Open Datacenter Diagnostics (OpenDCDiag), for running system-level tests on CPUs. As part of the open-source release, they have also provided sample tests which largely feature compression/decompression and linear algebra computations in a tight loop. Ideally, if we are able to draw post-manufacture tests from instruction distributions and sequences which correspond to realistic system load, then we can focus testing efforts on the execution scenarios that are most important to hyperscalers. Furthermore, if we can adapt datacenter applications themselves to perform testing, we can overlap tests with useful work. And a related question becomes, how can we enable datacenter schedulers to tune the degree of system-level testing which is performed based on reliability, Quality of Service (QoS), and application requirements?
Challenge 3: Scalable Fault Model Coverage
A third key challenge is the lack of thorough and scalable coverage metrics for system-level tests. Ideally, we could use RTL-level fault models, like the single stuck-at fault model, to synthesize suites of system-level tests that can expose particular hardware faults. However, translating RTL-level faults into system-level tests has historically faced scalability challenges. Notably, new research in formal verification of microprocessors and accelerators suggest this direction has renewed hope. In particular, recent work proposes a technique called accelerator quick error detection with decomposition (A-QED2), which scales to conduct functional verification of industry-scale designs like NVDLA. The key to this verification approach is that it leverages a highly generic property for verification, called functional consistency, which is highly amenable to decomposition. Researchers pursued this approach for processors as well. Moreover, it is worth noting that we need new post-manufacture testing approaches that are applicable to general-purpose processors as well as specialized accelerators.
How can industry help academia investigate this problem?
Hyperscalers, like Google and Meta, have issued a “call to action” for academics to investigate solutions to the challenge of SDC at scale. To support this sort of research it would be helpful for hyperscalers and hardware vendors to provide academics with resources along four dimensions: platforms/hardware, baselines, metrics, benchmarks/software.
Platforms/hardware. In order to evaluate SDC detection and mitigation strategies, and more generally characterize SDC burden, academics would benefit from access to buggy hardware—e.g., access to pools of servers, some of which exhibit known SDC bugs and some of which do not. Ideally, researchers will be able to select some fraction of SDC-impacted versus non-SDC-impacted machines on which to conduct testing experiments. In this way academics can better recreate the distributed environment that hyperscalers deal with.
Moreover, for implementation-driven test generation and test thoroughness estimation, access to hardware designs and even hardware models (e.g., simulators) is equally important. The Arm Flexible Access for Research program and NVDLA are two notable examples of hardware vendors making designs available to researchers.
Baselines. Academic research would also benefit from access to competitive baselines—e.g., scan chain and system-level tests and testing infrastructure, resilience and fault-tolerance solutions, etc. Intel’s OpenDCDiag framework, which contains system-level tests along with testing infrastructure to run the tests on Intel servers, is a key step in this direction. To the extent possible, providing academics with access to hyperscale testing infrastructure, like (variants of) the Fleetscanner or Ripple testing frameworks from Meta, SiliFuzz from Google, or even CASP derivatives that are implemented in some processors (e.g., those from Intel), would also be beneficial. Related to the above request for buggy hardware, ideally such hardware could be accompanied by test(s) that expose SDCs. In general, academics would benefit from access to baselines against which they can motivate and evaluate their proposed SDC solutions.
Metrics. Academics also require metrics to drive the development of effective and usable testing strategies. Ideally these metrics will be based on what hyperscalers view as the main pain points in their current approaches for tracking down SDC bugs. Some example metrics include: false positives (i.e., misclassifying cores as mercurial), test coverage (i.e., fraction of bugs that can be detected per line of test code or per test), localization effort (i.e., difficulty with which detected bugs are “root-caused”), and intrusiveness (i.e., degree to which a test interferes with data-center operation).
Applications/software. Systems, software, and even testing solutions to SDCs would also benefit from giving academics access to applications representative of typical datacenter system load. For example, microservice, machine learning, or database style benchmarks can be used to evaluate overhead of proposed SDC mitigations or resilience/fault-tolerance efforts and to drive application-based testing efforts.
Acknowledgements: Thank you to Subhasish Mitra for valuable discussions and feedback on the topics presented in this blogpost.
About the Author: Caroline Trippel is an Assistant Professor of Computer Science and Electrical Engineering at Stanford University. Her research on architectural concurrency and security verification has been recognized with IEEE Top Picks distinctions, the 2020 ACM SIGARCH/IEEE CS TCCA Outstanding Dissertation Award, and the 2020 CGS/ProQuest® Distinguished Dissertation Award in Mathematics, Physical Sciences, & Engineering.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
