
Despite being hidden from the end user, datacenters are ubiquitous in today’s life. Massive datacenter installations are the driving force behind social networking, search, streaming services, e-commerce, cloud, and the gig economy. Today’s datacenters are as expensive as ever, with the biggest commercial ones costing from USD 250 million to USD 500 million. These facilities also consume an ever-increasing amount of power, with some of the world’s largest data centers requiring more than 100 MW—enough to power around 80,000 U.S. households.
Disaggregation has recently emerged as a potent solution to tackle the challenge of growing resource consumption of the datacenter infrastructure. According to the disaggregated datacenter vision, compute units (CPUs, GPUs, accelerators) are decoupled from the memory hierarchy, with all components connected by the datacenter fabric. To stem the rise of the infrastructure costs, disaggregation emphasizes just-in-time resource allocation and re-purposing. When a workload demands resources, easily accessible, hot-swappable compute or memory components are removed where they are underutilized and are added where they are needed the most on-the-fly, without deploying additional servers and adding excessive capacity. This is unlike in traditional (i.e., aggregated) datacenters, where adding compute capacity requires the addition of entire new servers with expensive memory and network, which leads to underutilization of resources and increases costs for additional space, power, and management overhead.
The disaggregated datacenters entice industry with many potential benefits over traditional server design:
- Independent scale-out in processing and memory: “pay for what you need, use only what you need”. Results in lower refresh costs, reduced capital expenditures due to independent upgrade cycles (e.g., “extend the life cycle of your most expensive device”) and operating expenditures (better resource utilization and reduced overprovisioning).
- Higher memory capacity through disaggregation. With Fabric-Attached Memory (FAM), hosts are not constrained by the memory capacity limitations of traditional servers. Instead, they gain access to vast pools of memory not attached to any host. Compute components coordinate to partition the memory among themselves or to share FAM. Key cloud use cases such as live migration across compute hosts are streamlined (FAM resident snapshots do not have to be moved at all).
- Because this design enables compute components to directly access FAM, the software does not get in the way of remote memory accesses anymore: a Hypervisor or OS maps local and remote addresses into an application’s address space and then abstains from interfering in the workloads’ memory accesses. This improves performance.
- Disaggregation enables easily assembled custom hardware configurations, e.g., with domain-specific accelerators or emerging persistent media such as phase-change memory (PCM), 3D XPoint, memristor RAM (MRAM), Spin-Transfer Torque RAM (STTRAM), or fast FLASH (e.g., Z-NAND).
- Improved availability due to separate fault domains for compute and memory, and better shareability among processors.
In disaggregated systems, split controllers are used where a fabric interface handles packetization within a requester (compute) component, and the fabric responder handles memory-specific operations on the responder (FAM) side, as illustrated in Figure 1. This schema allows the use of different types of memory.
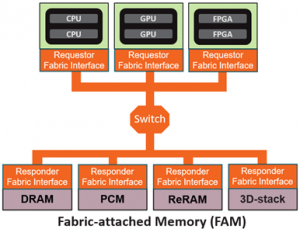
Figure 1. Split controller in the fabric attached memory architecture.
There are some challenges:
- Typically, accesses through fabric result in higher memory latency (target is sub-us for most interfaces).
- Providing hardware coherency and consistency on a datacenter scale is challenging. This may impact programmability.
Our goal in this blog post is to draw attention to the emerging field of disaggregated systems, introduce the standardization efforts that industry is pursuing, and outline topics for future research in this key area.
Past research and prototyping efforts
There have been notable research and prototyping efforts for disaggregation in the past:
HPE’s “the Machine” project focused on an architecture for memory-centric computing. It introduced a prototype that contains 160 TB of fabric-attached memory spread across 40 physical modules interconnected using a high-performance fabric protocol and photonics/optical communication links.
At Hot Chips 2019, HPE presented a chipset it developed for the U.S. DOE’s PathForward project that enables memory semantics when accessing the fabric. The company also developed a bridge chip that connects an AMD EPYCTM processor to its optical fabric via a PCIe Gen4 PHY link. HPE also developed a switch chip with in-package optics. Bridges can connect directly using a mesh topology (i.e., without switch chips) or using multiple switch planes with bandwidth distributed across the planes. HPE also developed an early-adopter platform called Cadet, which includes the bridge chip on a standard PCIe card with twelve optical links per card. Cadet allows for a full-mesh cluster of up to 13 DL-385 servers.
The authors of “Disaggregated Memory for Expansion and Sharing in Blade Servers” suggest a hardware design that allows CPUs on the compute blade to access remote memory directly at cache-block granularity. It uses custom hardware, called a “Coherence filter”, on the compute blade to redirect cache fill requests to the remote memory blade. The coherence filter selectively forwards necessary coherence protocol requests to the remote memory blade. For example, because the remote memory blade does not contain any caches, the coherence filter can respond immediately to invalidation requests. Only memory read and write requests require processing at the remote memory blade. In other words, the filter ensures that the memory blade is a home agent, but not a cache agent.
UC Berkeley’s FireBox project aims to develop a system architecture that scales up to 10,000 compute nodes and up to an exabyte of non-volatile memory connected via a low-latency, high-bandwidth optical switch. The FireBox project aims to produce custom datacenter SoCs, distributed simulation tools for warehouse-scale machines, and systems software for FireBox-style disaggregated datacenters.
dReDBox, an EU funded project led by IBM Research Ireland, together with ten industrial and academic partners across the European Union, aspires to innovate the way the datacenters are built by shifting to employing pooled, disaggregated – instead of monolithic, tightly integrated – components.
Industry adoption
To ensure broad interoperability free from vendor lock-in, the industry has come up with a number of fabric protocol specifications that enable disaggregated datacenter architectures. These include Gen-Z, CCIX, OpenCAPI, and Intel’s Rack Scale Design Architecture. These define hardware and software capabilities at both component and rack levels to enable composability.
Compute Express Link (CXL) has recently emerged as a high performance, low latency, memory-centric fabric protocol that can be used to communicate among devices in the system. It does this by enabling coherency and memory semantics on top of the PCI Express® 5.0 based I/O semantics for optimized performance in evolving disaggregated usage models.
CXL enjoys broad industry support. The protocol is on the second iteration of its specification. The original CXL 1.1 enabled standardized cache coherent connection of custom-made accelerators into the local host fabric. The use cases included byte-addressable memory expansion modules and compute accelerators with private memory that can delegate the coherency management to the host.
Building on the industry success and acceptance of CXL as evidenced by the 130+ member companies with active participation, the CXL Consortium recently announced the availability of CXL 2.0. The new protocol iteration offers full backward compatibility with CXL 1.1, while enabling additional usage models:
- Pooling enables resources such as accelerators and/or memory to be assigned to different hosts depending on the workload. Hosts can ask for those resources from the resource manager placed in the rack, obtain those if available, and release them when they are no longer needed. That way, memory can be allocated and deallocated to different hosts on-the-fly. This minimizes overprovisioning in the rack while improving performance. With CXL 2.0, it is also possible for a memory device to partition its memory among multiple hosts. CXL 2.0 accomplishes these goals by defining protocol enhancements capable of pooling while maintaining quality of service and reliability isolation requirements. It also defines managed hot-plug flows to add/remove resources.
- Persistency in emerging non-volatile memory enables a lot of high-performance applications where the entire data set can be retained in memory upon power cycle. To guarantee persistence, CXL 2.0 offers an architected flow and standard memory management interface for software.
To ensure that users have consistent experience while pooling resources, CXL 2.0 defines a standardized fabric manager. Distributed Management Task Force (DMTF)’s Redfish is a standard designed to deliver management for composable or Software Defined Data Center (SDDC) installations. The fabric manager uses RESTful interface semantics to access a Redfish Device Enablement (RDE) schema that describes the CXL resources and topology and performs component discovery, configuration, partitioning, and isolation. In particular, the responder FAM components may be partitioned by the Redfish manager across multiple requestor components (CPUs, GPUs, or accelerators).
Although the disaggregated model allows for a direct memory access from compute to the FAM, runtime support is still required for dynamic allocation of disaggregated memory. OpenFAM is a programming model for disaggregated persistent FAM. It supports key features such as:
- Defining FAM sections with different characteristics to accommodate different data needs (persistency enabled/disabled, no redundancy for communication or scratch space, redundancy for computation results).
- Named FAM regions for sharing between processes of a given job and between jobs.
- fam_map(), fam_unmap() API calls enable direct load and store access to FAM from the workloads after mapping is completed.
Future research directions
Cache coherency ensures that writes to a particular location from multiple compute components will be seen in order, as if there were no caches in the system. HW-implemented cache coherency is a technique that greatly simplifies memory programmability in traditional servers. However, HW coherency is difficult to achieve on the datacenter scale, owing to the scaling challenges of making it work across many thousands of nodes. To provide arbitration of accesses to the same location, today’s RDMA operations rely on atomics (e.g., compare-and-swap) to enable updating a memory location in an all-or-nothing fashion. These operations provide atomicity at the fabric level but require changes to the existing software. A promising research direction is to explore HW cache coherence schemes on the datacenter level that retain the programmability advantages of local server coherency, while ensuring scalability.
Memory consistency defines how all the memory instructions (to different memory locations) in a multi-processor system are ordered. Consistency models define ordering constraints on independent memory operations in a component’s instruction stream with high-level dependence (such as flags guarding data) that should be respected to obtain consistent results. Today’s x86 host processors implement Total Store Order (TSO) consistency allowing for store buffering to hide write latency, which can make execution significantly faster. Loads can bypass stores to the addresses not in the store buffers for significant performance gains.
In contrast, relaxed or weak consistency models rely on some notion of a fence (or barrier) operation that demarcates regions within which reordering is permissible. Release consistency is one example of a weak consistency model, where synchronization accesses are divided into Acquires (operations like lock, which must complete before all following memory accesses) and Releases (operations like unlock with all memory operations before release are complete). Acquire does not wait for accesses preceding it and accesses after release in program order do not have to wait for release-operations that follow release (and which need to wait must be protected by an acquire). Research work that explores acquire-release type memory semantics on large datacenter scales is needed to efficiently enforce ordering constraints on far memory operations.
Due to the diverse latency and bandwidth characteristics of emerging FAM technology, successful disaggregated memory architectures will have to perform dynamic memory management and likely will rely on the system to minimize the latency associated with memory accesses and address translation. Optimizing memory-access latency depends on the system’s ability to capture frequently used, or hot, data and dynamically allocate that data to the most suitable memory technologies available. The hot data needs to be swapped with infrequently accessed cold local data. Dynamic memory placement is a task that could be performed by systems software and is a promising area of future research.
Recent advancements in electrical-to-optical interfaces have enabled early prototype monolithic in-package optical I/O chiplets to communicate with each other from millimeter to kilometer scale, making it feasible to employ optically-attached disaggregated memory for direct host access. However, many challenges remain on the path to productization of this promising technology. Further research is needed to optimize the signal integrity and reduce jitter, noise, and crosstalk of the optical channel to maximize concurrent transactions on the electrical-to-optical interface.
To reduce the energy consumption of the datacenters, a promising direction is moving compute to data rather than the traditional approach of moving data to compute. The thread context is relatively compact. Moving it to the place where the data is stored on FAM could dramatically reduce the traffic as seen on the fabric. Besides, the limited fabric-side computational support allows unlocking massive local bandwidth and minimal latency of the FAM components, conserve host memory and fabric bandwidth, and reduce cache pollution. The challenge, however, is designing an efficient architecture for computational FAM modules and then seamlessly programming and submitting work to the Computational FAM modules with minimal changes to the existing codebases.
The next generation high performance, low latency, memory-centric fabric protocols like CXL garner broad industry support because they enable memory to be decoupled from compute and connected to the processing units over fabric. Such Fabric Attached Memory offers Hyperscalers independent scaling of resources. It also unlocks huge memory capacities unachievable within a node. Disaggregated system is a novel design with great potential and many exciting research areas left to explore.
About the authors:
Sergey Blagodurov is a Research Scientist at AMD since 2013. He works on redesigning datacenters for the Exascale era. Prior to AMD, he has been a Research Associate with HP Labs for three years, where he studied and contributed to the design and operation of net-zero energy data centers.
Michael Ignatowski is a Senior Fellow at AMD in Austin Texas where he leads AMD’s research efforts on advanced memory systems. His current research work focuses on processing-in-memory, exploiting emerging NVRAM technologies, and reconfigurable computing. Prior to joining AMD in 2010, Michael worked for 27 years at IBM leading work on performance analysis and memory hierarchy designs for S390 mainframes, Power systems, and SP supercomputers.
Valentina Salapura is a Senior Fellow at AMD. Previously, she was a System Architect at the IBM T.J. Watson Research Center, and a faculty member at the Technische Universität Wien. Valentina is a computer architect for large computer systems, from supercomputers to cloud computing data centers.
Acknowledgement: The authors thank Gabe Loh for helpful comments on this blog.
© 2021 Advanced Micro Devices, Inc. All rights reserved. AMD, the AMD Arrow logo, and combinations thereof are trademarks of Advanced Micro Devices, Inc. Other product names used in this publication are for identification purposes only and may be trademarks of their respective companies.
AMD Disclaimer
The information presented in this document is for informational purposes only and may contain technical inaccuracies, omissions, and typographical errors. The information contained herein is subject to change and may be rendered inaccurate for many reasons, including but not limited to product and roadmap changes, component and motherboard version changes, new model and/or product releases, product differences between differing manufacturers, software changes, BIOS flashes, firmware upgrades, or the like. Any computer system has risks of security vulnerabilities that cannot be completely prevented or mitigated. AMD assumes no obligation to update or otherwise correct or revise this information. However, AMD reserves the right to revise this information and to make changes from time to time to the content hereof without obligation of AMD to notify any person of such revisions or changes.
THIS INFORMATION IS PROVIDED ‘AS IS.” AMD MAKES NO REPRESENTATIONS OR WARRANTIES WITH RESPECT TO THE CONTENTS HEREOF AND ASSUMES NO RESPONSIBILITY FOR ANY INACCURACIES, ERRORS, OR OMISSIONS THAT MAY APPEAR IN THIS INFORMATION. AMD SPECIFICALLY DISCLAIMS ANY IMPLIED WARRANTIES OF NON-INFRINGEMENT, MERCHANTABILITY, OR FITNESS FOR ANY PARTICULAR PURPOSE. IN NO EVENT WILL AMD BE LIABLE TO ANY PERSON FOR ANY RELIANCE, DIRECT, INDIRECT, SPECIAL, OR OTHER CONSEQUENTIAL DAMAGES ARISING FROM THE USE OF ANY INFORMATION CONTAINED HEREIN, EVEN IF AMD IS EXPRESSLY ADVISED OF THE POSSIBILITY OF SUCH DAMAGES.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
