
There is a never-ending quest for faster query processing, and that is good. It has kept both database and architecture folks gainfully employed in support of the data industry. There is currently a renewed push towards interactive data querying, which requires fast responses to “interactive” queries. In such scenarios, there is often a human waiting for a response to a query, so fast and predictable response time is critical. In many of these interactive scenarios, the data fits in main memory; i.e., the datasets are smaller than a few TBs. For this article, we focus on that in-memory setting. (The issues highlighted below are much harder to solve when the IO subsystem is involved.)
One way to improve the performance of interactive queries is to throw more hardware at the problem. For example, buy a server equipped with a processor that has more cores than you likely need. But, that solution increases the overall cost. A better solution is to buy/rent just the “right” amount of hardware for the problem at hand. To go down this path, you need to predict what performance you can get from a given server. Analogous to the observation made by Google in their famous Tail @ Scale paper, there is a problem here even with simple queries/workloads and in single server settings. Let me illustrate with an example.
We ran two queries, Q3.1 and Q3.2, from a data warehousing benchmark (the Star Schema Benchmark) that mimics a retail scenario. In this benchmark, a “fact” table stores information about customer transactions, and analytical queries “join” data in this transaction table with three other, far smaller, dimension tables. Queries Q3.1 and Q3.2 are similar in their query structure, but select different amounts of data, resulting in more/less work per data item/tuple in the input database. We ran these queries in Quickstep, which is a new Apache (incubating) open-source database engine that we are building to target interactive querying settings. We ran these two queries on a server that is equipped with two Intel Xeon E5-2660 2.60 GHz (Haswell EP) processors. Each processor has 10 physical cores and a 25MB L3 cache that is shared across all the cores on that processor. Each core has a 32KB L1 instruction cache, 32KB L1 data cache, and a 256KB L2 cache. The machine is running Ubuntu 14.04.1 LTS. The server has a total of 160GB ECC memory, and the database was less than 100GB in size (it is the 100 scale factor benchmark dataset). Hyper-threading was turned on, and Quickstep threads were bound to cores to prevent thread migration.
We ran each query 1000 times in succession on a warm database buffer pool. Then, we calculated the nth percentile response time for each query, and further calculated a PSM (Percentile Spread over Mean) score. The PSM score for a query is simply its nth percentile response time value divided by the mean response time across all the runs of that query. PSM is a simple measure of the normalized skew across queries. The mean response times for queries Q3.1 and Q3.2 is 1.42s and 0.33 seconds respectively, and in the eclipse-inspired chart shown below, it represents the volume of the bubble. The chart below shows the PSM values at the 90th, 95th and 99th percentile marks.
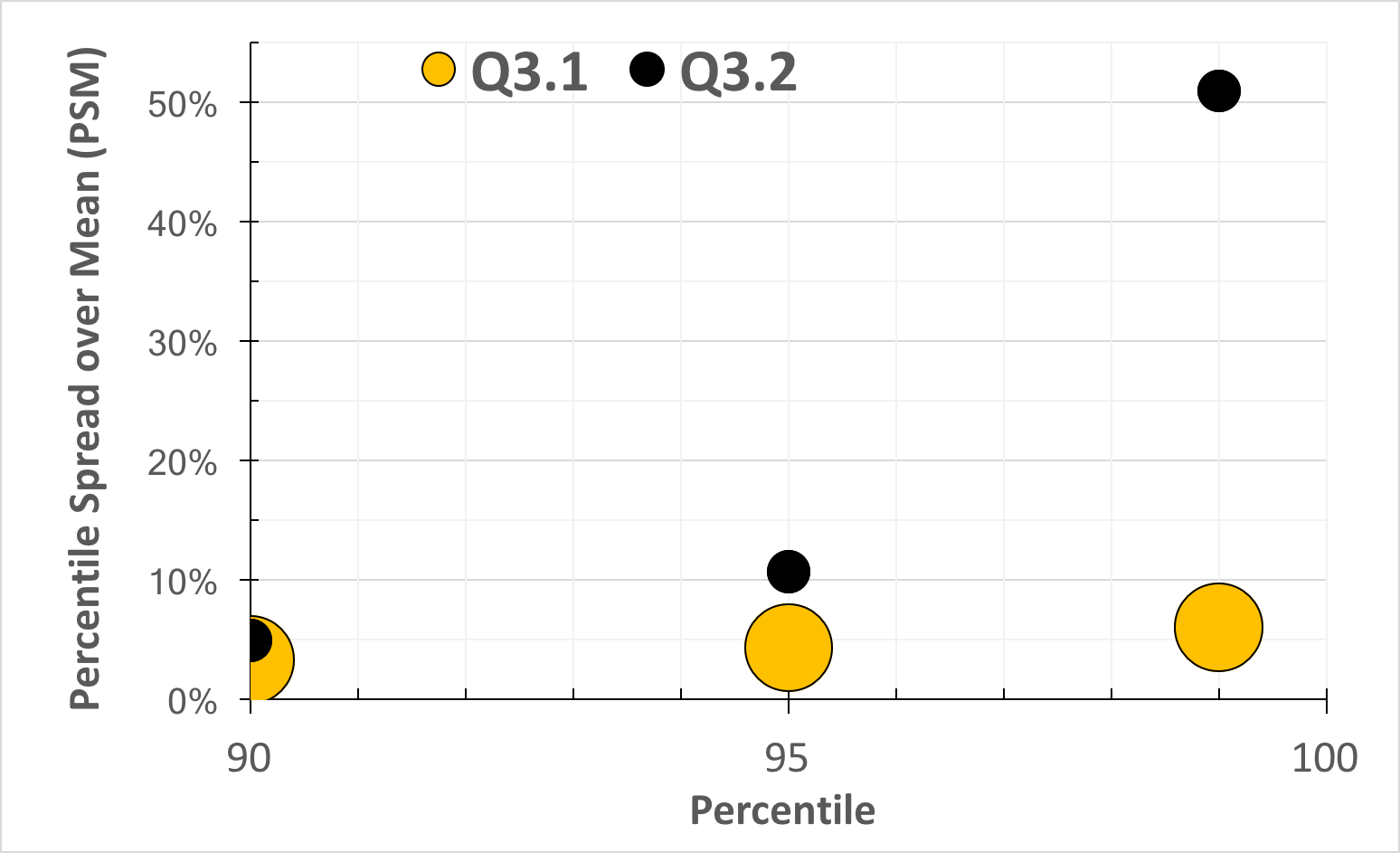
Variability in the run time of two interactive queries running in Quickstep.
Notice that for Query Q3.2, at the 99th percentile, the PSM shoots up to 50%. We see this pattern over and over again – as we work on algorithms to improve query performance and drive the response time to sub-seconds range, the variability in the response times shoots up, and it shoots up fast! This high variability leads to the issues with provisioning described above.
Now, trying to determine the root cause for such variability is a nightmare, at least for us non-hardware folks. We can use a plethora of tools, or look at various hardware counters directly. But, all this information is hard to convert into “semantically meaningful” information. There are hidden multipliers such as cache miss latencies, TLB miss latencies, and the cost of a machine clear event due to memory dependence misspeculation. Simply finding/computing such constants can be hard, and often there is a fair amount of guessing. Trying to determine which events/counters are meaningful is even harder, as often some aspect can be masked due to parallelism/speculation in the hardware. In short, today it is hard for software developers to drill down to determine the root causes of performance fluctuations.
In the data world, there is a growing realization that the output of queries can’t be more data, but that the output has to be easy-to-understand insights. It would be great if we can get the hardware to become smarter in this way too and have it produce semantically meaningful performance descriptors (SMPDs). I know that there are many tough issues here that involve trading off how much hardware resources to put into the measurement function, and the implications of that on clock speeds and other critical hardware design parameters. But, interactive queries are here to stay, and, as the database folks continue to develop methods to make queries go faster, this sub-second response time space for analytic queries will be even more relevant in the future. At the same time, the hardware of tomorrow will likely have far more parallelism and other hardware mechanisms that potentially introduce even more variability into the run time execution. Thus, we are at a crucial nexus, and it is imperative that we pay a lot more attention than we have in the past to meaningful hardware performance descriptors. There appear to be many open research questions, including: Is there a good understanding of the hardware tradeoffs involved in producing such performance descriptors? How do the different hardware subsystems (e.g. processor and memory) work together to deliver such performance descriptors in meaningful ways to the software layer? What is the right abstraction/interface between the hardware and software layers for such performance descriptors?
Perhaps it is time for the hardware and software folks to come together to work on this issue?
About the Author: Jignesh Patel is a Professor of Computer Sciences at the University of Wisconsin and works on databases.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
