Machine learning driven computer architecture tools and methods have the potential to drastically shape the future of computer architecture. The question is: how can we lay the foundation to effectively usher in this era? In this post, we delve into the transformative impact of machine learning (ML) on the research landscape, emphasizing the importance of understanding both its potential and pitfalls to fully support ML-assisted computer architecture research. By exploring these advancements, our aim is to highlight the opportunities that lie ahead and outline the collective steps that we, as a community, can take towards realizing the era of “Architecture 2.0.”
To contribute to Architecture 2.0, fill out this Google Form.
The Dawn of Architecture 2.0
In recent years, computer architecture research has been enriched by the advent of ML techniques. With the increasing complexity and design space of modern computing systems, ML-assisted architecture research has become a popular approach to improve the design and optimization of edge and cloud computing, heterogeneous, and complex computer systems.
ML techniques, such as deep learning and reinforcement learning, have shown promise in optimizing and designing various hardware and software components of computer systems, such as memory controllers, resource allocation, compiler optimization, cache allocation, scheduling, accelerator coherence, cloud resource sharing, power consumption, security and privacy. This has led to a proliferation of ML-assisted architecture research, with many researchers exploring new methods and algorithms to improve computer systems’ efficiency and learned embeddings for system design.
With the emergence of Large Language Models (LLM) like ChatGPT and BARD, as well as Generative AI models like DallE-2, Midjourney, and Stable Diffusion, future ML technologies are bound to offer a plethora of exciting possibilities for a new generation of computer architects. For instance, prompts such as “Act as a computer architect and generate me an ALU such that it meets the following requirements: …” might be common place. Such capabilities coupled with advances like AutoGPT may enable an AI-assistant in the future to become “proactive” beyond the current “reactive” AI methods and this will likely unlock new capabilities. Users will only need to provide goals to the model and it will do everything by itself in an autonomous, iterative loop–planning, critiquing, acting and reviewing. Elevating methods like prompt engineering for chip design to the next level.
This paradigm—Architecture 2.0—uses machine learning to minimize human intervention and build more complex, efficient systems in a shorter timeframe. Undoubtedly, Architecture 2.0 will bring about a revolutionary shift in research and development within computer architecture. Exciting new avenues will be explored. Generative AI will likely play a creative role in Architecture 2.0 by empowering architects and designers to rapidly generate and explore a wide array of design options. These areas exemplify the vast potential for growth and innovation within the field, similar to the transformative impact that Software 2.0 is having on the programming world.
Challenges with ML-Assisted Architecture Design
While ML-driven architecture research holds great promise, it also poses several challenges that we must understand and tackle collectively. Figure 1 illustrates some of the major challenges, including but not limited to the following:
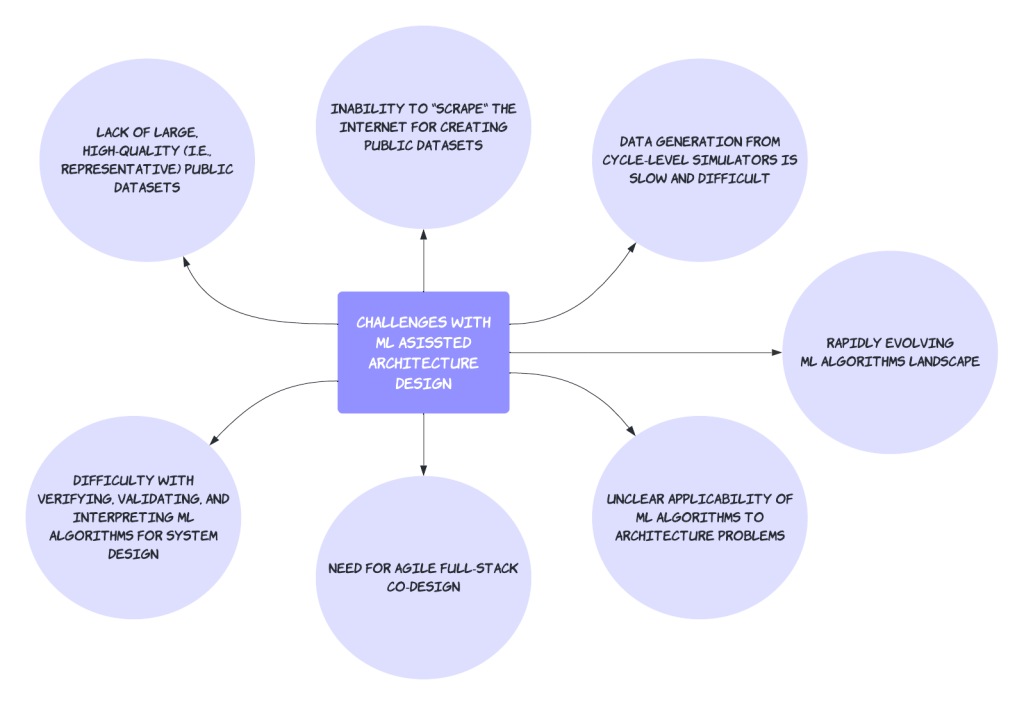
Figure 1: Key challenges with ML-assisted architecture design.
- Lack of large, high-quality (i.e., representative) public datasets: Machine learning-driven systems research often relies on large, high-quality datasets to train and validate models. The efficacy of machine learning can be attributed, in part, to the development and utilization of high quality datasets. However, in the context of computer architecture, such datasets are scarce and often not reusable, making it challenging for researchers to conduct their studies, compare their results, and develop effective solutions. Adding to the already challenging situation, representative datasets that accurately mirror the intricacies of real-world fleets and encompass the complete operational behavior of the entire system are even more difficult to come by.
- Inability to “scrape” the internet for creating public datasets: In many other machine learning domains, researchers can collect data by simply scraping the internet or using publicly available datasets (e.g. large language models mainly use readily available web crawl data for training). However, this approach is neither feasible nor scalable in the context of computer architecture research, as the data required is often specific to certain hardware and software configurations and may be proprietary data.
- Data generation from cycle-level simulators is slow and difficult: Simulators are often used to generate data for machine learning-driven systems research (such as building proxy models, searching for architecture parameters, etc.). Simulators like these are often slow, computationally expensive, and may not consistently reflect real-world systems accurately. Additionally, simulations are often intractable for multi-node or datacenter systems, limiting scalability and reducing data quality.
- Rapidly evolving ML algorithms landscape: The machine learning algorithms landscape is constantly changing, with new models and techniques being developed regularly. This can make it difficult for researchers to keep up with the latest developments and integrate them into their projects (i.e., the hardware lottery).
- Unclear applicability of ML algorithms to architecture problems: While machine learning has demonstrated success in a variety of domains, it is not always evident which problems in computer architecture are amenable to be solved effectively by ML algorithms. In addition, it is not clear how ML algorithms can be effectively applied to address computer architecture problems. This may result in wasted resources and suboptimal solutions.
- Need for agile full-stack co-design: It is necessary for all the system components to evolve together. Unfortunately, certain advancements in algorithms often get overlooked due to the lack of corresponding hardware support. For instance, although it is evident that machine learning can benefit from leveraging sparsity, it is rarely implemented because without hardware support, performance improvements are not achievable. Compilers must adapt and advance alongside both the hardware advancements and the evolving algorithms.
- Difficulty with verifying, validating, and interpreting ML algorithms for system design: Architects need to verify and validate the designs and regularly reason about the consequences of their decisions and interpret the implications of each design point on the overall performance of the target system. However, interpretability and understanding why a particular ML-assisted approach works or provenance about how the decision/tradeoff was made is still a missing piece for which reproducibility and systematically defining metrics, such as accuracy vs. uncertainty, are of critical importance.
In addition, we believe that the progress of ML-assisted architecture research is being hindered by several other factors: the absence of standardized benchmarks and baselines, challenges with reproducibility, and difficulties in evaluation. These issues collectively impede the advancement of this field. These issues have garnered attention and generated interest within the machine learning community, resulting in the organization of recent workshops and challenges.
Comparing different methods and algorithms is challenging. For instance, different researchers may use different datasets or metrics, making it challenging to compare results across studies (e.g., cycle-accurate EdgeTPU vs. analytical DNN accelerators). One study may use a dataset that is much easier or harder to learn from than another or using a less exhaustive hyperparameter search, which could lead to different results even if the same algorithm is used. Similarly, one study may use a metric that emphasizes a different aspect of performance or evaluation than another study, which could lead to different conclusions about the relative effectiveness of different algorithms.
Reproducing published ML results can also be difficult, especially if the code or data used is not publicly available. Without access to the code or data, it can be challenging, if not impossible, to determine whether differences in results are due to differences in methodology, implementation, or dataset. This can lead to a lack of confidence in published results and make it difficult for researchers to build upon each other’s work and make progress.
Furthermore, evaluating the effectiveness of ML algorithms in architecture research can be complex, as the performance of the algorithms may depend on various factors such as hardware configuration, workload, and optimization objectives (i.e., hyperparameter lottery). An algorithm that performs well on one type of workload may not perform well on another type of workload, or an algorithm that is optimized for one type of hardware configuration may not be effective on a different configuration. This makes it challenging to generalize results across different scenarios and to identify the conditions under which an algorithm is most effective.
Data-centric AI Gymnasium for Architecture 2.0
To overcome these challenges, we need to embrace a data-centric AI mindset where data rather than code is treated as a first class citizen in computer architecture. Traditionally, tools such as gem5 and Pin were used to explore, design and evaluate architectures based on application level code characteristics. But when data is the rocket fuel for ML algorithms, we must build the next generation of data-centric tools and infrastructure that will enable researchers and practitioners to collaborate, develop standard benchmarks, metrics and datasets. We also need to invest more in efficient data generation techniques that will be useful for ML assisted design. Last but not least, we need a playbook or a taxonomy that outlines how to effectively apply ML to systems problems.
To this end, we believe that we can learn from and leverage approaches like the OpenAI gymnasium-type environment for computer architecture research. The OpenAI Gym is a widely accepted toolkit in the ML community for developing and comparing reinforcement learning algorithms. It accelerated research by providing a standard interface (API) to communicate between learning algorithms and environments, as well as a standard set of environments that were compliant with that API. Since its release, its API has become the field standard for doing this. The gym has also provided a common platform for researchers to develop and compare reinforcement learning algorithms. This has led to a number of important advances in the field, including the development of new algorithms (e.g., DQN and Proximal Policy Optimization (PPO)) that are more efficient and effective than previous methods. The Gym has also been used to develop new benchmarks for algorithms. These benchmarks provide a way to compare the performance of different algorithms on a common set of tasks. This has been helpful for researchers to identify which algorithms are most effective for different tasks.
In a similar vein, we need a gymnasium for Architecture 2.0 to foster and nurture ML-assisted architecture research to pursue data-driven solutions. It would enable researchers to pose intriguing questions, share their code and data with the community, promoting collaboration and accelerating research progress.
The Architecture 2.0 gymnasium would enable researchers to easily add simulators as new environments, compare results objectively, share datasets, and develop new algorithms, etc. Architecture research encompasses a wide range of methods to explore the design space and develop novel solutions, including reinforcement learning, bayesian optimization, ant colony optimization, genetic algorithms, and more. Thus, it will be crucial for the gym to possess the necessary flexibility to accommodate all these diverse approaches for exploration. Furthermore, the gym would naturally encourage researchers to publish their breakthrough papers alongside datasets and code that will provide readers with valuable insights not only into the model strategy but also the data pre-processing techniques and hyperparameter tuning processes employed. By promoting such transparency, the gymnasium can foster reproducibility and enable objective comparisons, as emphasized in the post.
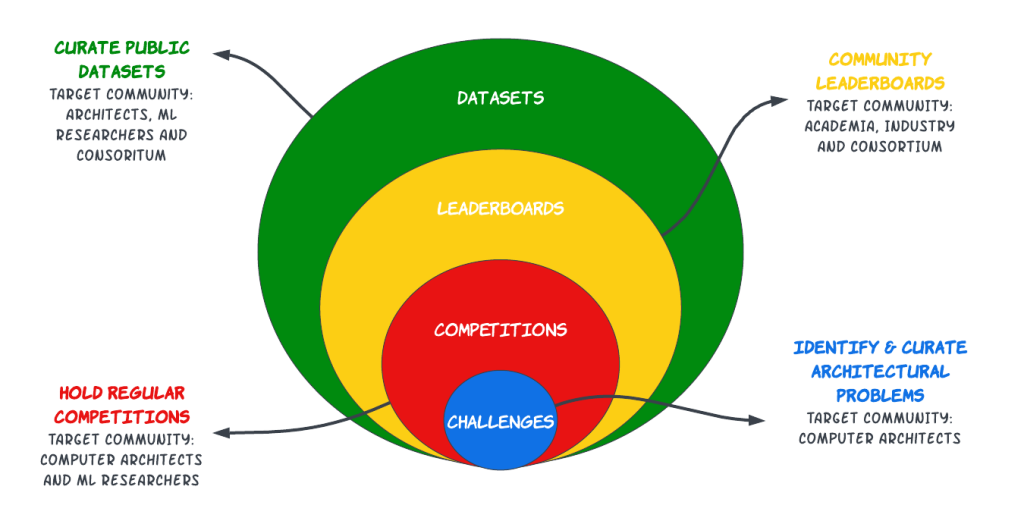
Figure 2: Creating an active community for Architecture 2.0.
In general, we recommend the gymnasium to encompass the following tenets as illustrated in Figure 2:
- Curated datasets: A collection of representative datasets and benchmarks designed to systematically evaluate different ML algorithms in computer architecture research. For instance, we need more resources like the open-source Google workload traces that were put out to aid systems research.
- Leaderboards: Leaderboards are instrumental in fostering healthy competition among researchers. By showcasing the latest results, we can inspire researchers to push boundaries, compare solutions, develop new solutions, and refine existing methodologies. Additionally, leaderboards can also serve as effective benchmarks. There is much we can learn from existing leaderboards like Dynabench and adopt them for our own purposes.
- Competitions: We should revive the “Workshop on Computer Architecture Competitions” and other similar computer architecture competitions (e.g. Branch Prediction, ML Prefetching) and adapt them for Architecture 2.0 to bootstrap the discovery of state of the art methods and algorithms.
- Challenges: Challenges hosted on a broadly accessible platform, such as hackathons or workshops, to promote collaboration and facilitate knowledge exchange among researchers and practitioners. To supercharge the architecture community, we need a Kaggle style mentality for Architecture 2.0 that would serve as a hub to attract, nurture, train, and challenge a new generation of architects from all around the world.
To nurture such a healthy and active community, we need accessible open-source tools and libraries that readily facilitate the implementation and testing of different ML algorithms in computer architecture research. For instance, tools like Pin provide high-level APIs that abstract away low-level implementation details to make developing and deploying program instrumentation tools easy. By making sure we develop Architecture 2.0 ML tools, such as CompilerGym and ArchGym, that are transparent and easy to run for the designer, we can empower researchers to focus on their core expertise instead of getting overwhelmed with details irrelevant to them.
In addition to tools, we also need consistent and standardized evaluation metrics that can be reliably used to compare the performance, efficiency and robustness of different ML algorithms in computer architecture research. Metrics often appear straightforward when viewed in hindsight. However, there is a considerable amount of nuance associated with them. An incorrect metric can result in misguided optimization strategies. For instance, it took a long time for ML processor architects to realize that relying solely on TOPS/W (alone) can be harmful.
Call for Participation
Building the Architecture 2.0 ecosystem extends beyond the capabilities of any individual group. It requires a collective effort. Therefore, we invite the community to join us in the effort to identify, design, and develop the next generation of ML-assisted tools and infrastructure. If you are interested in contributing to Architecture 2.0, please fill out this Google Form to meet with us at ISCA 2023 as part of the Federated Computing Research Conference. Students and researchers from all ages and groups are welcome. Even if you are unable to attend the conference, please take a moment to fill out the form. This will enable us to contact you when we schedule a community kickoff meeting. We look forward to hearing from you and hopefully seeing you soon. Let’s build the future together!
Conclusion
An Architecture 2.0 data-centric AI gymnasium would provide a number of benefits for academia and the industry. It would make it easier for academic researchers to experiment with different algorithms, understand the pros and cons of different algorithms, reproduce each other’s results, compare the performance of their own algorithms to strong baselines, and explore more design space. The creation of such an ecosystem would also benefit the industry as it would accelerate the pace of innovation, lead to the development of new and more efficient designs, and help to bridge the gap between machine learning and the architecture and systems communities. What we propose is not unfounded. In fact, almost two decades ago, MicroLib tried to enable researchers to do comparison of architectural designs with others through a standard interface. Considering the advancements in technology and the evolution of the field towards ML-assisted design, it is now even more critical for a shared ecosystem.
Acknowledgements
We proactively solicited feedback from numerous people to craft this vision. We appreciate the feedback from Saman Amarasinghe (MIT), David Brooks (Harvard), Brian Hirano (Micron), Qijing Jenny Huang (Nvidia), Ravi Iyer (Intel), David Kanter (MLCommons), Christos Kozyrakis (Stanford), Hsien-Hsin Sean Lee (Intel), Benjamin C. Lee (UPenn), Jae W. Lee (SNU), Martin Maas (Google DeepMind), Divya Mahajan (GaTech), Phitchaya Mangpo Phothilimthana (Google DeepMind), Parthasarathy Ranganathan (Google), Carole-Jean Wu (Meta), Hongil Yoon (Google), Cliff Young (Google DeepMind). We would like to acknowledge and highlight the contributions of Srivatsan Krishnan (Harvard), who led the research project that generated many of the ideas discussed in this work. We also extend our gratitude to Jason Jabbour (Harvard), Shvetank Prakash (Harvard), Thierry Thambe (Harvard), and Ikechukwu Uchendu (Harvard) for their valuable feedback and contributions.
About the Authors
Vijay Janapa Reddi is the John L. Loeb Associate Professor of Engineering and Applied Sciences at Harvard University. He helped co-found MLCommons, a non-profit organization committed to accelerating machine learning for the benefit of all. Within MLCommons, he serves as Vice President and holds a position on the board of directors. Vijay oversees MLCommons Research, which brings together a diverse team of over 125 researchers from various organizations to provide exploratory value to MLCommons members. He co-led the development of the MLPerf benchmark, which encompasses ML in datacenters, edge computing, mobile devices, and Internet of Things (IoT). Vijay is the recipient of best paper and IEEE Micro TopPicks awards and other accolades, including the Gilbreth Lecturer Honor from the National Academy of Engineering (NAE) and IEEE TCCA Young Computer Architect Award.
Amir Yazdanbakhsh is a research scientist at Google DeepMind. Most of his research revolves around Computer Systems and Machine Learning. Amir is the co-founder and co-lead of the Machine Learning for Computer Architecture team where they leverage the recent machine learning methods and advancements to innovate and design better hardware accelerators.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
