As artificial intelligence continues its meteoric rise, the field of computer architecture is evolving to keep pace. Machine learning (ML) promises to transform architectural design and optimization in ways we are only beginning to grasp. To align perspectives on this shift, we recently hosted a virtual workshop on Architecture 2.0 that was open to the community, which had participants from over 60 universities and 20 tech companies, as well as national labs.
| Architecture 2.0 is a community-driven effort to enable machine learning to minimize human intervention and build more complex, efficient computer systems in a shorter time frame. |
Keynote (Partha Ranganathan – VP/Technical Fellow, Google)
Partha Ranganathan (VP/Technical Fellow, Google) set the stage for the workshop by delving into the key challenges and opportunities for Architecture 2.0 and how machine learning and generative AI can be the key enabler in advancing Moore’s law. During his presentation, Partha highlighted the interplay of hardware design and its usage and how machine learning can be applied effectively in myriad ways across system stack.
Notably, he outlined several key scenarios where ML proves instrumental: (1) complex co-design and rapid innovation, (2) ML-automated generative design and optimization, (3) ML-driven software-defined infrastructure, and (4) automatic power management and scheduling. Partha concluded his address by underscoring the significance of an open ecosystem for interoperable, composable, and modular infrastructure with well-defined interfaces, ecosystem, and standards. He particularly highlighted how fostering collaboration and community building around Architecture 2.0 presents a unique opportunity to pioneer innovation and drive the next generation of computer architecture and system design.
Workshop Insights
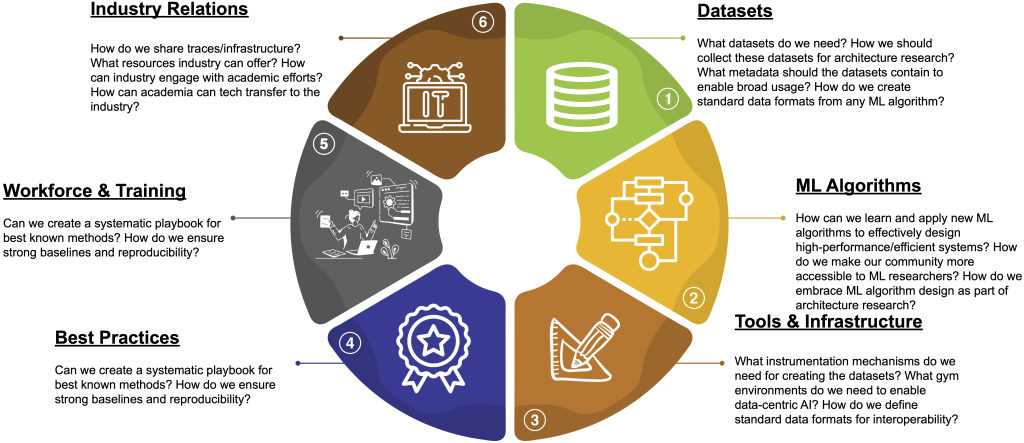
The enthusiastic participation from the large number of participants highlighted the timeliness of this emerging topic. In the workshop, we focused on six primary workstreams for the discussions: (1) dataset collection, (2) machine learning algorithms, (3) tools and infrastructure, (4) best practices, (5) workforce and training, and (6) industry relations. Each of these was led by a peer group of organizers, who have extensive domain expertise in the topic.
This blog post encapsulates the takeaways from each of the workstreams, while also outlining the subsequent steps from our event. This post is both a call for involvement and a call for our community to collectively take action for the enablement of ML-driven architecture design.
Architecture 2.0 → ML for ML (Machine Learning to Drive Moore’s Law)
 |
Datasets Leads: Yingyan (Celine) Lin (GaTech) and Amir Yazdanbakhsh (Google DeepMind) |
The datasets discussion recognized complications in sharing proprietary architectural information and data from companies and production-grade systems. Potential solutions ranged from data obfuscation to relying more on architecture simulations and synthetic data generation for various hardware architectures. However, it was well noted that over-dependence on simulated datasets risks misalignment with real-world complexities.
To this end, participants in this working group discussed developing standard data collection protocols and defining precise dataset features were highlighted as ways to ease sharing and reuse of datasets across groups. In terms of specific data needs, the appetite for application-specific datasets and standardized benchmarks for generating diverse training data was clearly articulated.
 |
Machine Learning (ML) Algorithms Leads: Siddharth Garg (NYU) and Jenny Huang (Nvidia) |
This session sought to understand how state-of-art ML models and algorithms can be adapted or enhanced for architecture design, resulting in future foundation models for computer architecture. The potential of utilizing LLMs for solving architecture problems, for instance by fine-tuning these models on outputs from architecture simulators, was discussed. Ensuring trustworthiness and reliability of outcomes was considered critical, especially for safety-critical systems. Co-design of specialized ML solutions with architecture mechanisms was proposed as a promising approach.
The need for common languages, benchmarks, and proxy problems was emphasized to facilitate engagement of the ML research community. Adopting simpler learning techniques where possible, before jumping to complex deep neural networks, was advised. Techniques that provide guarantees around convergence, bounds, and so on were considered valuable.
 |
Tools and Infrastructure Leads: Tushar Krishna (GaTech), Jason Lowe-Power (UC Davis), Matt Sinclair (UW-Madison), Srinivas Sridharan (Nvidia) |
The tools and infrastructure sessions identified numerous pain points in modeling, simulation, emulation and design automation. Supporting rapid co-design of learning algorithms, software and hardware was deemed critical for productivity. Modular simulators and standardized APIs to enable interoperability and reproducibility were also suggested. Standards to share intermediate data and tool outputs, e.g. Chakra execution traces, in a secure manner would also foster collaboration.
Multi-fidelity simulators that tradeoff accuracy for speed were discussed to accelerate exploration. Incorporating ML to enhance simulators and other tools was considered promising. The appetite for real-world datasets, API access, and tool integrations from industry partners was evident. Defining metrics to quantify concepts like system “goodness” across devices and a wide range of workloads was recognized as an open research challenge.
 |
Best Practices Leads: Benjamin Lee (UPenn) and Martin Maas (Google DeepMind) |
The best practices session had vigorous discussions on formulating evaluation metrics beyond accuracy, taking the end-to-end problem into account and comparing to non-ML state of the art. The group discussed the importance of developing taxonomies to characterize different ways of using ML in architecture domains, recognizing that each may result in different best practices for different use cases. For example, offline optimization of architectures fundamentally differs from models deployed within a running system. The need for community-driven benchmarks to enable comparative studies in these different domains was also highlighted.
Safety considerations around potential failure modes from AI systems were discussed, as well as the need for considering practical factors such as explainability. Developing rigorous validation methodologies and guardrails emerged as an important area. Evolved review processes, encouragement to publish datasets and code, and venues to publish negative results may incentivize rigorous evaluations and facilitate comparisons to state-of-the-art models for varied systems and architecture problems.
 |
Workforce and Training Leads: Jason Lowe-Power (UC Davis), Matt Sinclair (UW-Madison) |
In the workforce and training session, the need to evolve university curriculum to integrate architecture and ML disciplines was discussed. Foundational architecture understanding was still considered essential even as ML automation increases. Industry partnerships could help align on required skill sets. Open-source course material, tools and realistic assignments can motivate students. Flexibility will be key to accommodate rapidly evolving algorithms and techniques.
Multidisciplinary exposure spanning computer science, electrical engineering, physics and mathematics was advised even for early undergraduates. Architectural concepts being accessible via interactive simulators and visualization tools for novices was recommended. Student participation in open-source projects, data generation efforts and industry internships would accelerate hands-on learning.
 |
Industry Collaboration Leads: Brian Hirano (Micron), Cliff Young (Google DeepMind) |
The industry partnership sessions yielded thought-provoking discussions. Academia taking on more high-risk, exploratory research was advised, while industry focuses resources on incremental refinement and deployment. Industry could contribute by releasing older designs, datasets, and tools that carry less competitive sensitivity. Shared incentives like grants, publications, and intellectual commons were proposed.
Developing standard interfaces and abstractions to facilitate interoperability across the stack was considered critical. Extending open-source tool flows like Chipyard, Chisel and FireSim via ML integrated into the workflows was suggested as a collaborative initiative with tangible value. Architecture Gym and Compiler Gym environments powered by real-system traces would enable scalable simulated training. IP protection remains a key consideration.
To further promote industry collaboration, we recently presented the idea of Architecture 2.0 at the 2023 Open Compute Project Global Summit to industry stakeholders and encouraged them to further participate in this community-driven effort. We will continue to seek out new industry partners and gather their priorities in the use of AI/ML in the development of new hardware products and their interest in areas such as workforce development, to align academic and industry interests in Architecture 2.0.
Cross-Cutting Themes
Certain cross-cutting themes resonated across the diverse sessions:
- The dire need for shareable datasets, benchmarks, and open-source tools
- Creating common languages and abstractions to facilitate collaboration across architecture, systems, and ML
- Quantifying tradeoffs between simpler ML models that allow analysis versus highly complex but opaque models
- Methodologies to ensure trustworthiness, reproducibility, and constraints for reliable outcomes
- Designing flexible simulators, numerical systems, and hardware to support emerging workloads
- Incentivizing openness across academia and industry, while respecting IP considerations
The workshop concluded with a panel discussion that reiterated these key points and set the stage for collaborative actions in this exciting domain. By bringing together stakeholders from across academia, industry, and national labs, this workshop triggered vital conversations on architectural design being increasingly driven by large neural networks.
Outcomes and Next Steps
Based on this workshop, we plan on releasing a community driven whitepaper. The preliminary summary of the workshop discussion is available here. If you like to contribute to the whitepaper and get involved in shaping it, please reach out to us at: contact.architecture2.0@gmail.com
In addition, to build on the momentum, we will start an Architecture 2.0 seminar series where we’ll be bringing together this vibrant community of researchers and professionals. The seminar will include presentations showcasing the latest work, discussions on cutting-edge tools, and the infrastructure applying ML to diverse architecture problems.
Our primary goal is to curate a repository detailing the myriad applications of ML. This initiative not only facilitates the community in building upon established work but also paves the way for recognizing pivotal challenges and setting benchmarks. This allows us to shape the future by identifying and promoting state-of-the-art ML methodologies.
If you are interested in taking part in these activities, please join the following Google groups.
In summary, the passionate participation and perspectives shared at this workshop highlight the tremendous potential in this domain. By working together to lower barriers, facilitated by community-led initiatives, technology roadmaps set by industry and research funding agencies can be aligned for maximum impact. The key takeaway is that progress will rely on partnerships across disciplines to shape the next generation of computing platforms and architectures.
Acknowledgements
We proactively solicited feedback and comments from numerous people to craft this vision and as part of the inaugural of Architecture 2.0 virtual workshop. We appreciate the feedback from Saman Amarasinghe (MIT), David Brooks (Harvard), Ravi Iyer (Intel), David Kanter (MLCommons), Christos Kozyrakis (Stanford), Hsien-Hsin Sean Lee (Intel), Jae W. Lee (SNU), Divya Mahajan (GaTech), Phitchaya Mangpo Phothilimthana (Google DeepMind), Parthasarathy Ranganathan (Google), Carole-Jean Wu (Meta), Hongil Yoon (Google), and all the participants in our discussions and the Architecture 2.0 workshop. We would like to acknowledge and highlight the contributions of students including Akanksha Chaudhari (UW-Madison), Jason Jabbour (Harvard), Rutwik Jain (UW-Madison), Thierry Thambe (Harvard), and Ikechukwu Uchendu (Harvard) for their valuable feedback and contributions.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
