
Architecture & Systems are Changing: The Architect’s Role in the Era of Agentic Co-Design
The AI datacenter stack is built on hardware-software contracts and abstractions that were never designed for the workloads datacenters now serve. Memory systems strain under terabyte-scale capacity. Heterogeneous accelerators have been pressed into deployment. With datacenters projected to consume over 1,000 TWh annually, surpassing Japan (the world’s fourth-largest economy), renegotiating the hardware-software contract is no longer optional.
AI was enabled by decades of hardware and software efficiency gains. The next leap requires two orders of magnitude more, on a stack whose workloads, infrastructure, and economics bear little resemblance to the one the contract was written for.
That is not a problem any single layer of the stack can solve. It is a co-design problem, and it is unfolding while the design process itself is changing across systems and architecture.
The contract so far
Computer architecture has long been guided by a quiet contract with three commitments: abstractions, interfaces, and transparency. Layers that hide hardware complexity from programmers; interfaces like the x86 ISA that let decades-old binaries still run on Linux today; and microarchitectural state largely hidden behind a model programmers can keep in their heads. Together, these commitments deliver the property programmers care about most: programmability.
This contract is not arbitrary: it is what lets billions of lines of legacy software keep running while architects rebuild underneath. But the contract was negotiated for a world where humans wrote all of the code and humans designed all of the hardware. Both halves of that world are changing at the same time, and the architect’s job is evolving with them.
Plenty of room at the Top
In 2020, Leiserson, Thompson, Emer, Kuszmaul, Lampson, Sanchez, and Schardl argued in Science that post-Moore performance gains would have to come from the “Top” of the computing stack: software, algorithms, and hardware architecture, rather than from the “Bottom” of semiconductor physics. They were right, and the half-decade since has only sharpened the point.
The harder claim in that paper is the one we want to dwell on. The Top has plenty of room, but the gains are “opportunistic, uneven, and sporadic,” subject to diminishing returns. The Top has historically been mined by hand, one paper and one design cycle at a time. What is changing now is the rate at which it is mineable. The two directions we describe next change that rate. Same Top, mined faster, mined more systematically, and mined by tools the field did not have until recently.
Two directions are reshaping the design loop
Two complementary directions are converging on how we build system software and hardware: embedding learning inside low-level mechanisms, and using AI agents to explore the architectural design space itself.
The first direction has a deep history. Perceptron-based branch predictors put a lightweight learning model on the critical path more than two decades ago, and the catalog has steadily grown since. On the cache-hierarchy side, Mockingjay uses a trained reuse-distance predictor to imitate Belady’s optimal replacement policy. On the prefetching side, Hashemi et al. framed memory access patterns as an LSTM prediction task, Pythia recast the entire prefetcher as an online reinforcement-learning agent, and Micro-Armed Bandit showed that lightweight bandit-based RL can match more complex agents at a fraction of the storage cost. Outside the cache hierarchy, reinforcement learning has been applied to chip floorplanning, learning-based memory allocation replaced hand-tuned allocator heuristics with predictors trained on real telemetry, and Seer applied deep learning to predict QoS violations in cloud microservices before they materialize. Most recently, our work on learned virtual memory (LVM) eliminated address-translation overhead with a learned index that fits in two cycles of integer arithmetic. The principle generalizes: fixed designs are being replaced with principled, hardware-realizable models that adapt to workload shifts in ways hand-tuned heuristics cannot.
The second direction is newer, and arguably more disruptive. AlphaEvolve demonstrated that LLMs paired with evolutionary search can discover algorithms across domains, from mathematical constructions to data-center scheduling. ADRS extended the idea to broader systems research, and recent work from Google has applied the same approach to cache replacement. The same paradigm has reached the software side of the machine: agentic systems that generate and tune CUDA and Triton kernels, including NVIDIA’s AVO and Meta’s KernelEvolve, are now in use across heterogeneous accelerators. Sankaralingam captured the bigger picture in Computer Architecture’s AlphaZero Moment, arguing that the field is approaching a regime where architectural discovery itself becomes a search problem, beyond per-mechanism tuning. In our own recent work, Agentic Architect, we coupled LLM-driven code evolution with cycle-accurate simulation to explore microarchitectural design spaces, and found that the loop matches or exceeds state-of-the-art designs on cache replacement, prefetching, and branch prediction.
These two directions are not alternatives. They differ in what they decide and when. The first decides how a fixed mechanism behaves at runtime: a branch predictor that learns its own weights, a cache policy that adapts to the workload. The second decides what the mechanism looks like in the first place: the predictor, the policy, the prefetcher itself, evolved before deployment. Both move judgment that used to live in tight loops written by experts into search problems that can be scored and re-evaluated.
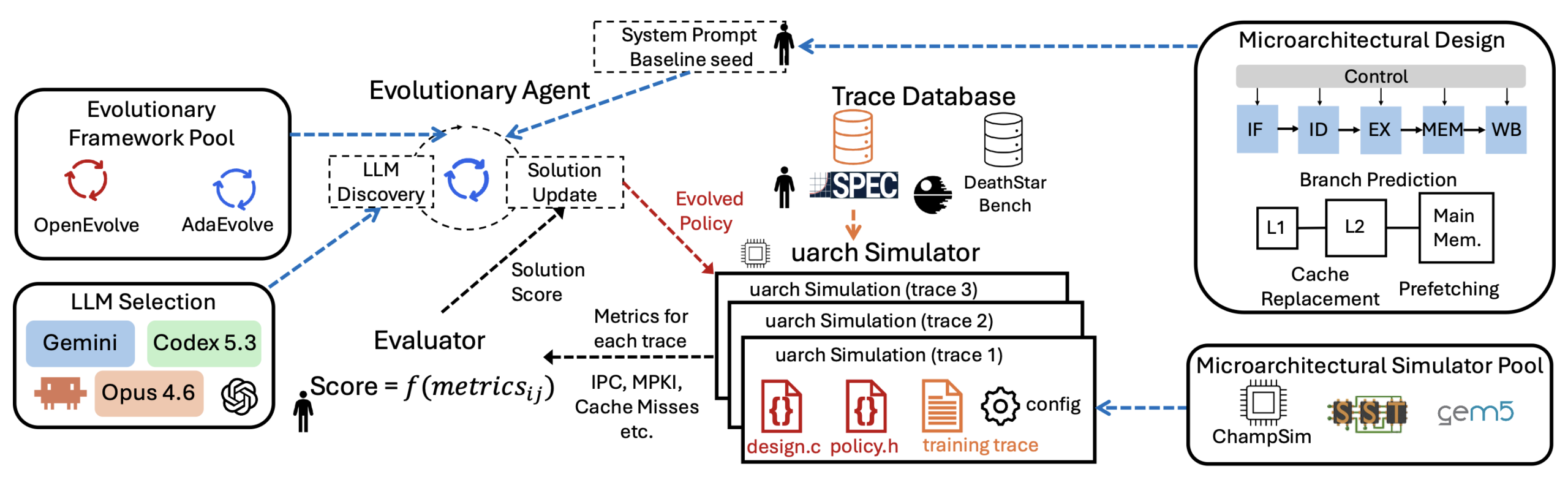
Figure 1. Agentic Architect, a framework for Computer Architecture Design Space Exploration and Optimization.
Why the loop closes here
Computer architecture has a structural advantage that is easy to take for granted: from the beginning, the field has organized itself around shared, quantitative empirical evaluation. SPEC, PARSEC, CloudSuite, DeathStarBench, and a long list of others encode a community-wide agreement about what a “fair comparison” looks like. The metrics are equally well established: IPC, MPKI, miss rates, area, power, energy-delay product. Every paper in the field is, in effect, a measurement against an agreed instrument.
An agentic loop needs exactly this kind of discipline to close. The loop’s productivity is bounded by the cost and clarity of its fitness signal: how cheaply can a candidate be evaluated, and how reliably does the resulting score reflect the property we actually care about? In domains where evaluation is subjective, expensive, or contested, agentic exploration struggles. In computer architecture, the cycle-accurate simulator gives the loop reproducibility: controlled-environment evaluation against well-defined metrics. Production profiling, hardware performance counters, tracing, and system telemetry give it realism: behavior under load and access patterns that synthetic benchmarks cannot reproduce. The two together are what close the loop.
That has a practical consequence. It means the field does not have to invent its evaluation infrastructure to take advantage of agentic co-design; it has to connect it. The benchmarks, the simulators, and the metric vocabulary are already in place. What is missing is the throughput and the integration: simulators that can serve hundreds of evaluations per study, fitness functions that compose IPC with area and power as primary terms, and training/evaluation splits that let us measure generalization instead of overfitting. We will return to this agenda below.
When code is co-authored, what does “programmable” mean?
Some of the architectural conservatism we aimed to maintain was justified, decades ago, by a single phrase: but no one will program it. The Cell processor’s programmer-managed SPEs and local stores are an example: an elegant design that proved very hard to program in practice.
The cost of programmability used to be borne almost entirely by humans. That is no longer true, and it changes the calculation.
In April 2025, Satya Nadella reported that 20% to 30% of Microsoft’s code was AI-generated, with internal acceptance rates rising monotonically. Google sits in a similar regime: a quarter in Q3 2024, half by fall 2025, and 75% of Google’s code by April 2026, with Sundar Pichai describing the shift as “truly agentic workflows” in which engineers orchestrate fleets of AI agents rather than writing each line themselves.
These numbers describe authorship of characters, not accountability. But they should change how we evaluate the programmability constraint. When agents can routinely program across ISAs, generate platform-specific code paths, write test harnesses, and bridge unfamiliar interfaces given a clear specification, the cost on the programmer is no longer a sufficient veto on a hardware design choice. Designs that were dismissed because they imposed too high a cost on human programmers warrant a fresh look when most of that cost falls on agents instead.
Programmability still matters. Clarity, debuggability, verifiability, and predictable performance remain real properties humans need, and increasingly properties agents need too. Abstractions still matter, perhaps more than ever. Deciding which to expose, which to hide, and which to make machine-checkable is now a question for the programming-languages and systems community alongside architects. But the most consequential lever may not be what we add; it may be what we remove. Many of the layers in today’s stack exist to hide hardware from human programmers and cost cycles and area to maintain. When agents absorb that complexity, the layers come off, and the performance and efficiency we have been paying to abstract away come back.
A widening design space
Reshaping the loop only matters if the space it has to cover is tractable. Increasingly, it isn’t.
A modern AI datacenter spans CPUs, GPUs, AI accelerators, a widening memory landscape (DRAM, CXL, HBM, HBF, SSD), and rack-scale integration with NVLink and optical interconnects. The software and hardware layers have not caught up: a single agentic query may dispatch dozens of model invocations across heterogeneous devices and tool calls on CPUs, all with different abstractions. The operating system (OS), the layer that has historically reconciled such mismatches, must evolve at an unprecedented pace to keep up with growing hardware capabilities and software demands. For example, it only has partial visibility into the GPU, despite its prominent role in AI workloads. Our recent work LithOS has established a beachhead for OS-level control over GPUs, but extending that contract to coordinate the full heterogeneous stack is open. At every level of that stack, energy and power are hardening from secondary considerations into primary constraints.
Each of these pressures is, individually, a multi-year research program. Together, they describe a design space defined by heterogeneous compute, evolving memory hierarchies, rack-scale integration, software-level coordination, and workload regimes that did not exist five years ago. Covering this space by hand is increasingly difficult, even for a large team of architects.
That is the practical case for agentic co-design. The space is outgrowing human-only exploration, and the tools to cover it are finally here.
A proof point
In our recent work, we introduce the Agentic Architect, an agentic framework for architecture design space exploration and optimization. We evaluate it across three of the most studied microarchitectural domains: cache replacement, data prefetching, and branch prediction. We chose them precisely because they are mature. They have decades of literature, well-understood baselines, and limited remaining headroom; if the loop produces gains in these domains, the result is meaningful. The evolved cache replacement policy matched and slightly exceeded Mockingjay; the evolved prefetcher beat SOTA by 17%; the evolved branch predictor improved over Hashed Perceptron on workloads where branch behavior is the bottleneck.
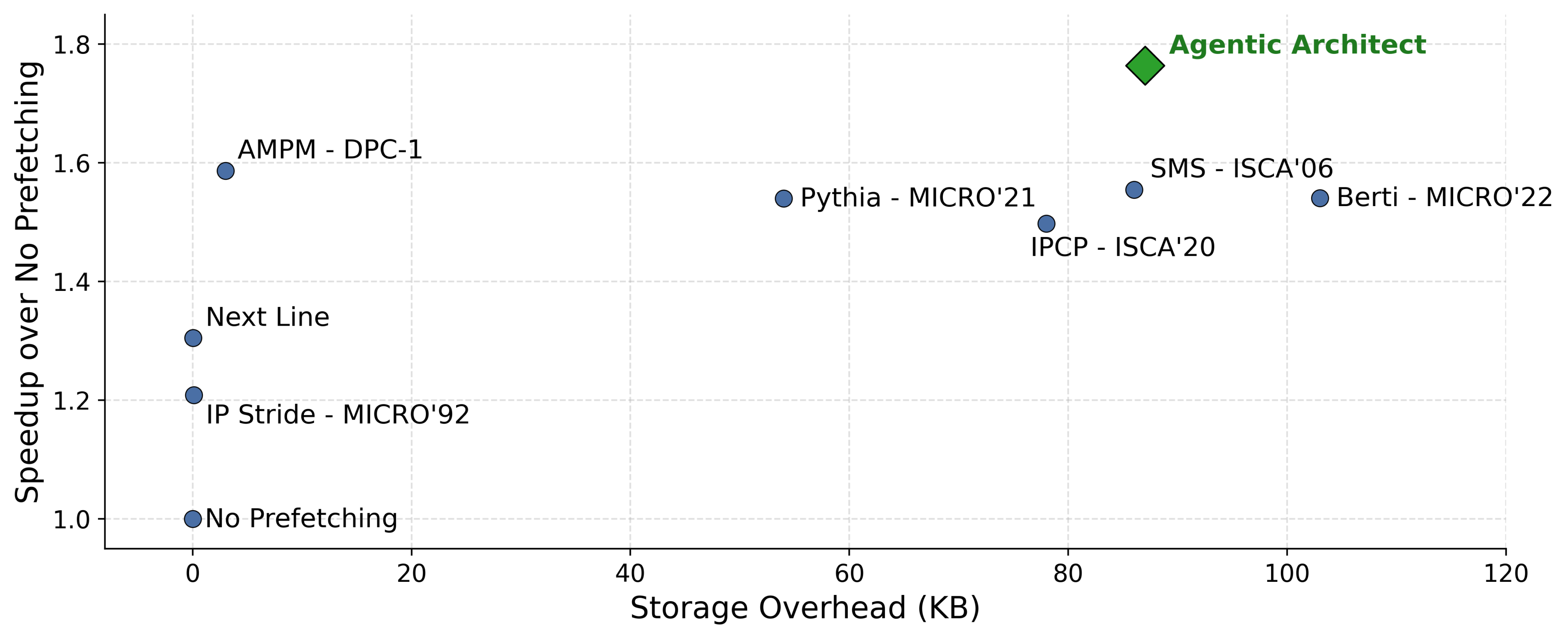
Figure 2. Storage versus performance for data prefetchers. The evolved prefetcher (87 KB) is Pareto-optimal: it delivers the highest geomean speedup over no prefetching at a smaller storage budget than the next-best design.
The more interesting result is what the loop discovered, and what it didn’t. The components in the evolved designs are almost entirely known techniques: stride engines and delta correlators for prefetching, reuse-distance predictors and signature tables for replacement, perceptron variants for branch prediction. None of these primitives is new.
What is new is the coordination. The evolved prefetcher continuously re-evaluates each predictive engine and throttles speculative ones under memory pressure. The evolved replacement policy arbitrates between three independent predictors based on their recent accuracy. The recurring structure across all three domains is the same: preserve the seed’s core, add orthogonal known features, integrate them through new coordination, and adapt at runtime. The novelty lies in the coordination. The loop refines the foundation; the architect still chooses it.
The infrastructure needs to evolve
If agentic co-design is going to do useful work across this design space, the bottleneck moves to infrastructure. The benchmarks and metrics are already there. What we need to build is throughput, multi-objective scoring, and cross-layer reach. The agenda is concrete:
- New tools for agentic architecture design space exploration. Cycle-accurate simulators were built for human-paced experimentation; an agentic loop wants hundreds of evaluations per study, with storage, area, power, and timing as terms in the score rather than afterthoughts that disqualify the result later. We need simulators, search strategies, and metrics purpose-built for this regime: search loops that respect hardware constraints and balance exploration against exploitation, and composite metrics that combine performance, area cost, and generalization into signals the search can rank against.
- Cross-component and cross-layer co-evolution. Co-design across the OS/hardware boundary is now the norm rather than the exception. Taking virtual memory as an example, TLB design, page-table walkers, translation footprint in the caches, and huge-page promotion in the kernel are tightly coupled, and optimizing any one in isolation may capture only a fraction of the available improvement. RTL backends, full-system simulators, and formal verification each let the loop close around a different surface.
- Open source has to evolve. Releasing code is no longer enough. We need structured artifacts that span the full stack, from prompt, seed, and scoring function down to traces, simulator and system configurations, and where applicable RTL, packaged so an agent can clone a repo, re-run the search that produced a published result, and compare new candidates against the same baseline.
The architecture and systems communities are uniquely positioned to drive that work.
Renegotiating computer architecture and systems
A stack co-authored by humans and agents needs renegotiation along the three axes of the old contract. Each is now reweighed against a new deliverable: programmability for agents and humans alike, rather than humans alone.
Abstractions. Many layers exist precisely to hide hardware from human programmers, and they cost cycles and area to maintain. With agents absorbing that complexity, some of those layers can come off; performance and efficiency we have been paying to abstract away come back.
Interfaces. The boundary between hardware and software was drawn for human programmers. As agents become the primary author of low-level code, the interface that carries the contract forward needs redrawing: machine-checkable, composable, and accessible to tools rather than only to humans.
Transparency. The property that lets a programmer model the CPU in their head gives way to a stricter need: explainability. The architect must verify the result against intent, explain why it works, and check that it generalizes beyond the workloads it was trained on. None of these come for free; the field needs methods, metrics, and tooling that make them routine.
Leiserson and colleagues told us in 2020 that there was plenty of room at the Top of the computing stack. The half-decade since has been about confirming they were right; the next half-decade will be about whether we build the tools to actually live there. Agentic co-design, paired with learning embedded inside the system itself, is a strong candidate for addressing the “opportunistic, uneven, sporadic” character that delivered those gains so far.
Architecture is changing. The contract still holds, but the terms are up for negotiation. The next generation of the stack will be defined as much by what we remove as by what we add. The people best positioned to make those calls are the ones who understand both the hardware and the software. That is, by definition, our community.
Acknowledgments
Thanks to the Computer Architecture & Operating System (CAOS) group at Carnegie Mellon and to Prof. Alex Daglis and Prof. Todd Mowry for feedback on this post.
About the Author
Dimitrios Skarlatos is an assistant professor in the Computer Science Department at Carnegie Mellon University. His research bridges computer architecture and operating systems with a focus on AI datacenter efficiency, privacy, and scalability. His work has been deployed in production datacenters and upstreamed into the Linux kernel. He has received the IEEE CS TCCA Young Computer Architect Award, the NSF CAREER Award, the Intel Rising Star Award, a Linux Foundation Faculty Award, an ISCA Best Paper Award, two ASPLOS Best Paper Awards, a CACM Research Highlight, four IEEE MICRO Top Picks, the joint ACM SIGARCH & IEEE CS TCCA Outstanding Dissertation Award, the David J. Kuck Outstanding PhD Thesis Award, and over a dozen industry faculty awards from Amazon, AMD, Intel, Meta, Oracle, and VMware. His recent work led to the founding of LithosAI.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
