TL;DR: The history of parallel computing is a history of shifting what we put at the center of the computer. The first axis, control-level parallelism (CLP), is control-centric and schedules around the program counter: it gave us the high-performance computing (HPC) era. The second axis, data-level parallelism (DLP), is data-centric and schedules around tensors: it gave us the artificial intelligence (AI) era. A third axis is now emerging: value-level parallelism (VLP), where narrow data bitwidth exposes a small number of unique values and lets the architecture deduplicate redundant computation. Two recent works, Carat (ASPLOS ’24) and Mugi (ASPLOS ’26), make the case concretely: VLP eliminates redundant computation in both linear and nonlinear operations on AI workloads. This article argues that VLP is not a point of optimization but the beginning of a value-centric computing paradigm, one that is crucial for addressing the escalating energy demands of next-generation intelligent systems.
Traditional Parallel Computing
The First Axis: Control-Level Parallelism
The HPC era saw a diverse set of workloads. The metric of success made the goal explicit: instructions per cycle (IPC) normalizes performance to how fast instructions are consumed, not to what data the instructions are operating on. Therefore, computer architecture in the HPC era was control-centric. Michael Flynn formalized the design space in 1966 with his taxonomy [1]: SISD, SIMD, MISD, MIMD, outlining the orthogonality of instruction and data. For decades, this was the right framing: transistors were scarce, control logic was expensive, and the most valuable thing an architect could do was to issue one more instruction per cycle.
The actual implementation to exploit the CLP to execute multiple instructions in parallel arose from the independence between instructions. We enjoyed the technology evolution from pipelining, branch prediction for SISD, superscalar issue, out-of-order execution, simultaneous multithreading, chip multiprocessors for MIMD and beyond.
The Second Axis: Data-Level Parallelism
Entering the AI era, powered by large language models (LLMs), transistors became plentiful but the memory bandwidth became scarce due to the large data volume in AI tensors. Consequently, we hit the memory wall and turned to data-centric architectures, expanding more along the data dimension in Flynn’s taxonomy. Success is now measured by how well we apply one operation to many data elements while feeding them efficiently from memory (e.g., throughput, goodput, and arithmetic intensity). TPUs with systolic arrays and GPUs with tensor cores are renowned examples to exploit the rich DLP opportunities from high-dimensional tensors.
Diving deeper, we see that compute arrays, i.e., dataflow architecture, are becoming the first class citizens. Dataflow architecture follows the philosophy of letting data drive control, with early works from MIT [2] [3]. With regular compute and memory patterns in AI tensors, dataflow architecture builds massively parallel compute arrays to maximize the computational density and minimize the control overhead.
Another line of research to exploit DLP for AI workloads targets the von Neumann bottleneck, envisioned by John Backus as early as 1978 [4]. These solutions move the computation closer to the memory (e.g., in/near-memory/storage processing) by attaching additional compute logic next to the memory blocks, unlocking massive DLP on the already wide enough memory blocks.
The Third Axis: Value-Level Parallelism
Though Flynn’s taxonomy, with dimensions of instructions and data, has been followed for decades, there are untouched landscapes. While CLP and DLP focus on concurrency and parallelism, neither asks the next question about the content of the data: can the patterns in data values benefit the computation efficiency? VLP is value-centric and the third axis in this regard, i.e., it targets computational redundancy inherent to the data patterns of workloads. It recognizes that when identical values flow through a pipeline, the arithmetic becomes deterministic and, therefore, avoidable. Consequently, we move from executing every instruction and data to computing only each unique data value.
Origins for GEMM
Carat (Pan, San Miguel, Wu — ASPLOS ’24) [5] is the paper that coined VLP and materialized it in hardware architecture. The insight is simple. As deep learning inference moves to larger batches and lower precisions (e.g., FP8 being the de-facto data format in DeepSeek v3), the number of unique values shrinks rapidly while the frequency of each grows. Here, we give an example. For a scalar-vector multiplication for an arbitrary scale weight w and 1k UINT4 inputs, conventional hardware would compute 1k multiplications for the weight w and each UINT4 vector element. Looking closely, there are only 16 unique products, i.e., 0 x w, 1 x w, 2 x w, …, 15 x w. Thus, conventional hardware would compute 1k/16=64 times more than needed.
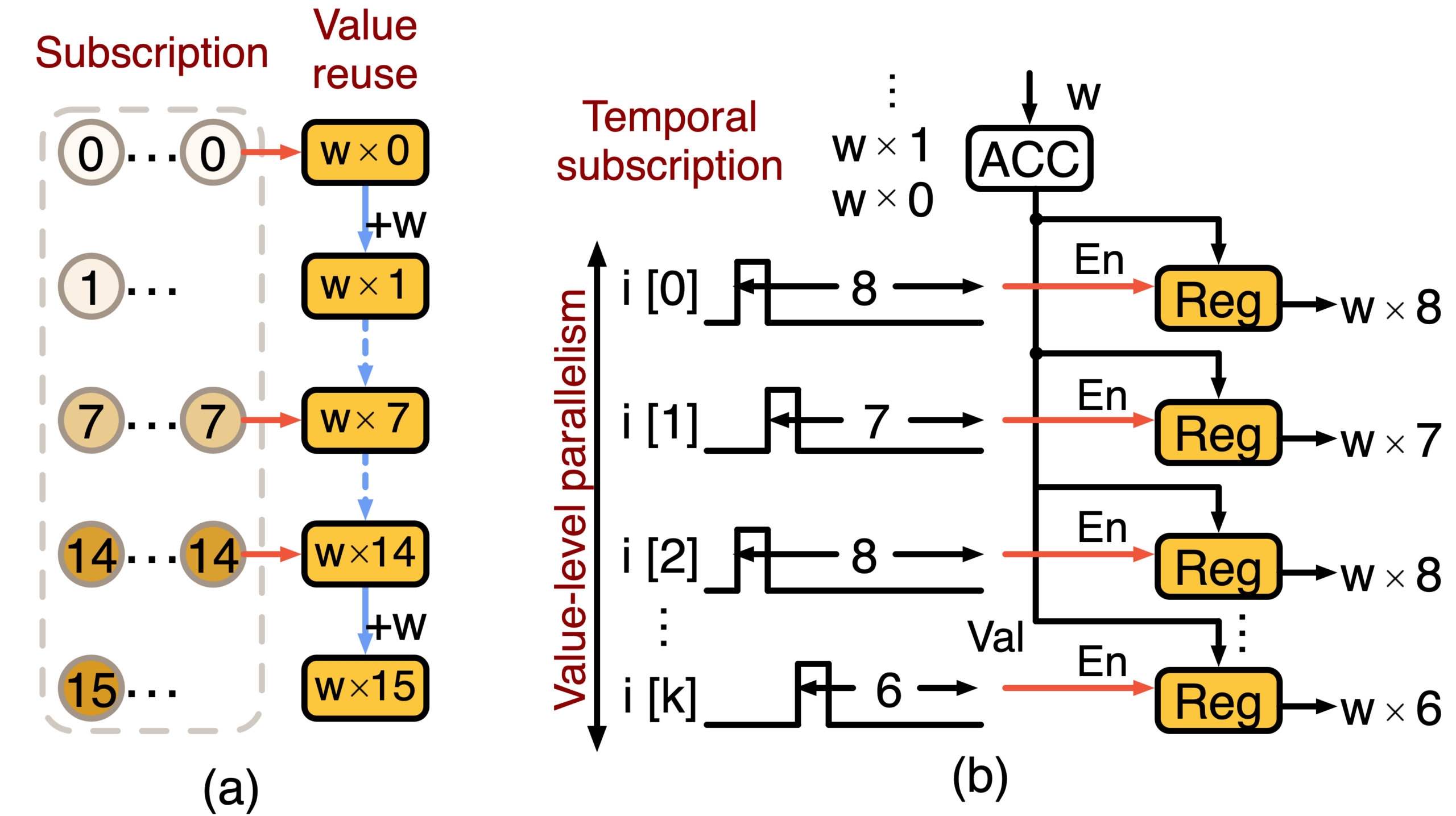
Figure 1. Overview of VLP for scalar-vector multiplication.
Figure 1 above outlines how VLP is constructed in Carat. In Figure 1 (a), VLP consists of value reuse, which accumulates the weight w over time, each accumulation result, called a partial product, is used to compute the next partial product. Then each input just subscribes to the proper partial product as the correct output. To materialize the subscription, we leverage temporal coding, often seen in the brain, which generates a spike at the cycle indexed by the data value. For example, a data valued 8 will generate a spike at cycle 8, as shown in Figure 1 (b). Therefore, there exists a temporal correspondence between the spike and the accumulated partial product. Each input subscribes to their correct output in parallel, giving the rise to value-level parallelism. The scheduling unit is no longer the instruction or the array element; it is the unique product value, made available to many input consumers via temporal coding. Given this formulation, we see that lower precision produces fewer unique values, while larger batches create more inputs to share the unique values.
Generalizing Beyond
So far, VLP in Carat targets GEMM optimization for large-batch, low-precision, symmetric-format use cases. However, these assumptions may no longer hold in more recent LLM workloads: the batch size is small (e.g., 8~16) to ensure real-time response, the data formats are asymmetric (e.g., INT4-FP16) to minimize the memory footprint of the weight and KV cache, and the nonlinear operations are heavy and complicated (e.g., softmax, GELU, SiLU) to ensure high accuracy.
Mugi (Price, Vellaisamy, Shen, Wu — ASPLOS ’26) [6] is a follow-up work that closes the gap and generalizes VLP for both linear and nonlinear operations for broader AI workloads. Figure 2 shows VLP for elementwise nonlinear operations that can be done through a four-phase pipeline on input floating-point numbers with a sign (S), mantissa (M) and exponent (E). The first phase is input approximation, which converts wider inputs to narrower bits without sacrificing the LLM accuracy too much. The inputs to nonlinear operations are always in higher precision (e.g., BF16, FP16, or FP32) in AI workloads than model weights. The approximation to narrower bits ensures a shorter temporal signal for high throughput. The second phase is value reuse with opportunities from large GEMM shapes in LLMs. Unlike value reuse in Carat accumulating the partial product, value reuse in Mugi loads the precomputed nonlinear results, where higher accuracy is allocated to more critical inputs. The third phase performs temporal subscription on the mantissa bits (M) of the inputs. For each input, the selected output corresponds to the nonlinear results with the same mantissa but different exponents (E). Finally, the fourth phase performs temporal subscription on the exponent bits of the inputs. For each input, the selected output corresponds to the correct mantissa and exponent.
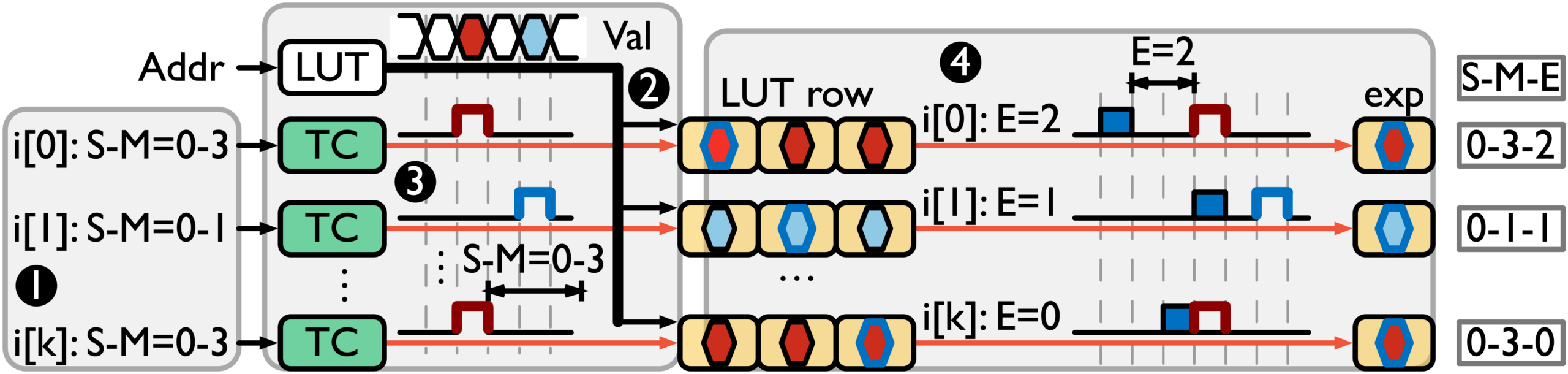
Figure 2. Overview of VLP for elementwise nonlinear operations.
Mugi essentially cascades VLP to construct high dimensionality in the value space to compute nonlinear operations. The resulting architecture unifies the datapath for both linear and nonlinear operations, leading to savings in silicon area.
What Makes VLP Different
Conventional architectures pay arithmetic costs to process every instruction and data element while advanced techniques (e.g., memoization, tabulation) leverage computation reuse and pay memory costs to store past results and refer back to them when needed. VLP pays for neither: it minimizes both arithmetic and memory access, instead spending its silicon budget on value delivery, i.e., the network and temporal converters that route unique results to many input consumers in parallel. The type of computation fundamentally changes to something new: a form of temporal subscription.
Future Opportunities and Open Questions
In its current form, VLP relies on temporal coding, which is actually inspired from how the brain works. Though the community has focused predominantly on deep learning, VLP opens up a different research direction: what are potential synergies between neuromorphic and classical computing in computer architecture? Looking beyond, VLP raises several questions to answer in the AI era.
- Where does VLP stop paying off? Though Carat and Mugi work for varying batch sizes, both of them now are designed for low precision to create more opportunities for value reuse. There is presumably a design space with high precision and low value redundancy. It is essential to understand the mechanism to exploit VLP for such scenarios and quantify the potential gain.
- Is VLP an ISA-level concept or an accelerator-level one? Both Carat and Mugi are accelerator designs. A real-world question is whether VLP can inform CPU and GPU microarchitecture. What would a VLP-based tensor instruction look like? Could it be a drop-in replacement of tensor cores with better efficiency?
- What should the software stack look like? VLP for nonlinear involves approximation, which naturally introduces inaccuracy to the task. This falls back to the question of approximate computing, but in the context of new hardware primitives. We probably shall build a co-design framework to deploy VLP under approximation errors.
- Can VLP live with sparsity? Sparse computation has been a major optimization since the start of deep learning, and more opportunities are emerging from weight, KV-cache spanning across the bit level, value level, block level and even request level. It is meaningful to study how VLP synergizes with such use cases.
- How does VLP interact with memory? Despite efforts in computation, memory stays at the core of AI. A natural question is whether we can optimize the memory system with VLP, or more broadly, value-centric computing. There have been associative memory-based AI accelerators, and whether there could be VLP-based alternatives?
Final Thoughts
Architecture research is all about how to compute faster and more efficiently. Control-level parallelism has let us argue about IPC and pipelines for thirty years. Data-level parallelism has let us argue about FLOPS and dataflow for fifteen. Value-level parallelism, the third axis, now shows promise for emerging AI workloads (thanks to Carat and Mugi) and paves the way for exciting synergies between neuromorphic and classical computing. Here’s hoping one day computer architects see the value in it.
About the authors:
Di Wu is an assistant professor at the University of Central Florida.
Zhewen Pan is a PhD candidate at the University of Wisconsin–Madison.
Joshua San Miguel is an associate professor at the University of Wisconsin–Madison.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
