
Editors Note: This is the second of two independent posts on the performance of Intel’s new memory technology.
For the last ten years, researchers have been anticipating the arrival of commercially available, scalable non-volatile main memory (NVMM) technologies that provide byte-granularity storage and survive power outages. Last week, Intel released a product based on their 3DXPoint memory in from a DIMM-like memory module that attaches directly to the processor’s memory bus. At long last, scalable, persistent memory has arrived!
Now that it’s here, researchers can begin to grapple with their complexities and idiosyncrasies. Below, I share some initial measurements and observations about these DIMMs and what they might mean from memory, storage, and system architectures. A more detailed report is available here.
The Device
Like traditional DRAM DIMMs, the 3DXPoint DIMMs sit on the memory bus and connects to the processor’s onboard memory controller. Our test systems use Intel’s new second generation Xeon Scalable processors (codenamed Cascade Lake). A single CPU can host six 3DXPoint DIMMs with a total capacity of 3 TB. The memory controller communicates with the DIMM via a custom protocol that is mechanically and electrically compatible with DDR4 but allows for variable-latency memory transactions. The DIMMs we used in our experiments were 256 GB.
The DIMMs can operate in two modes: Memory and App Direct modes.
Memory mode expands main memory capacity without persistence. It combines a 3DXPoint DIMM with a conventional DRAM DIMM that serves as a direct-mapped cache for the 3DXPoint. The cache block size is 4 KB, and the CPU’s memory controller manages the cache transparently. The CPU and operating system simply see a larger pool of main memory.
In App Direct mode the 3DXPoint DIMMs appears as a separate, persistent memory device. There is no DRAM cache. Instead, the system can install a file system to manage the device. 3DXPoint-aware applications and the file system can access the DIMMs with load and store instructions and use the facilities that the processor provides to enforce ordering constraints and ensure crash consistency. In our graphs, we refer to App Direct mode as uncached.
Basic 3DXPoint Performance
The most critical difference between 3DXPoint and DRAM is that 3DXPoint has longer latency and lower bandwidth. Load and store performance is also asymmetric.
Latency
To measure 3DXPoint load latency, we disable the DRAM cache and issue single load instructions with a cold cache. On average, random loads take 305 ns compared to 81 ns for DRAM. For sequential loads, latencies are 169 ns, suggesting some buffering or caching inside the 3DXPoint DIMM.
Measuring write latency is difficult because we cannot detect when a store physically reaches the 3DXPoint DIMM. We can, however, detect when the store reaches the processor’s asynchronous DRAM refresh (ADR) domain, which guarantees that the store’s effects are persistent. To measure that latency, we issue a store followed by a cache flush instruction and a fence. That latency is 94 ns for 3DXPoint compared to 86 ns for DRAM.
Bandwidth
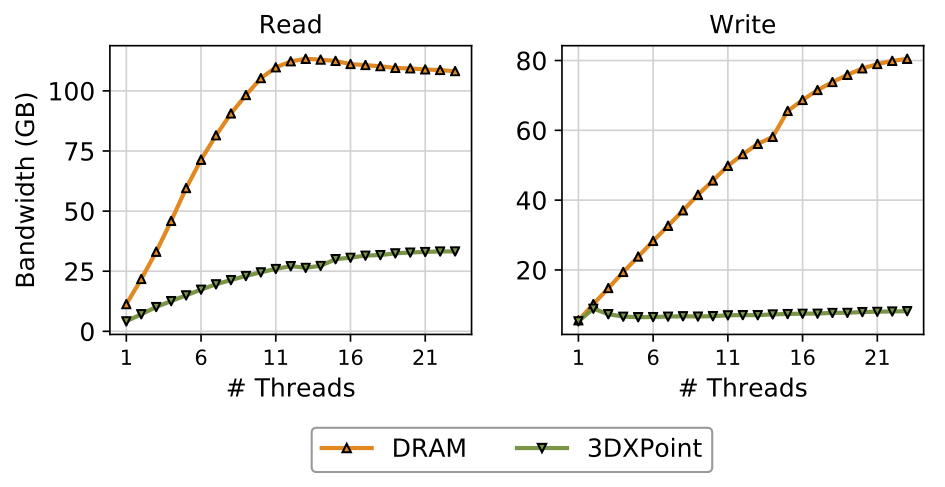
Our measurements show that 3DXPoint bandwidth is lower than DRAM bandwidth, especially for stores. The figure below plots sequential access bandwidth to six 3DXPoint DIMMs for between 1 and 23 threads and compares its bandwidth to six DRAM DIMMs. For reads (at left), bandwidth peaks at 39.4 GB/s. For writes (at right), it takes just four threads to reach saturation at 13.9 GB/s.
Random access performance is interesting as well. This figure plots bandwidth for random accesses of different sizes to a single DIMM issued by one thread. The left edge of the graph corresponds to small (64 B) random updates, while the right edge measure accesses large enough (128 kB) to be effectively sequential.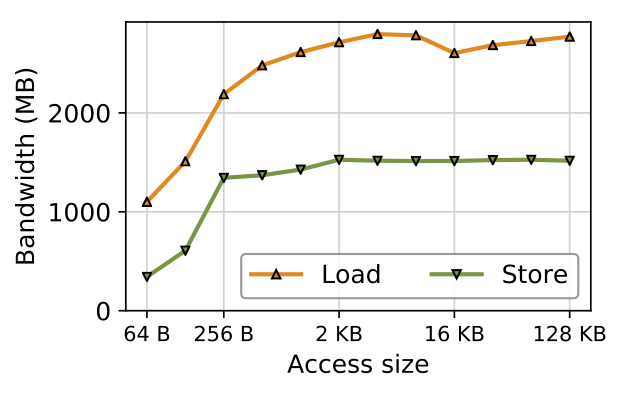
Performance for read and write rises quickly until access size reaches 256 B and slowly climbs to a peak of 1.5 GB/s for stores and 2.8 GB/s for loads. 256 B is 3DXPoint’s internal block size. It represents the smallest efficient access granularity for 3DXPoint. Loads and stores that are smaller than this granularity waste bandwidth as they have the same latency as a 256 B access. Stores that are smaller also result in write amplification since 3DXPoint writes at least 256 B for every update, incurring wear and consuming energy.
3DXPoint as Persistent Storage
3DXPoint will profoundly affect the performance of storage systems. Using 3DXPoint DIMMs as storage media disables the DRAM cache and exposes the 3DXPoint as a persistent memory block device in Linux. Several persistent-memory file systems are available to run on such a device: Ext4 and XFS were built for disks but have direct access (or “DAX”) modes, while others (e.g., NOVA) are purpose-built for persistent memory.
The graph below summarizes performance for several file systems performing random reads and random writes with between one and sixteen threads. It also compares performance to a SATA SSDs (“Ext4-SATA”) and Optane-based SSDs (“Ext4-Optane”) that exposes 3DXPoint as a block device via the PCIe bus. The data show that 3DXPoint improves basic storage performance over both of those storage devices by a wide margin.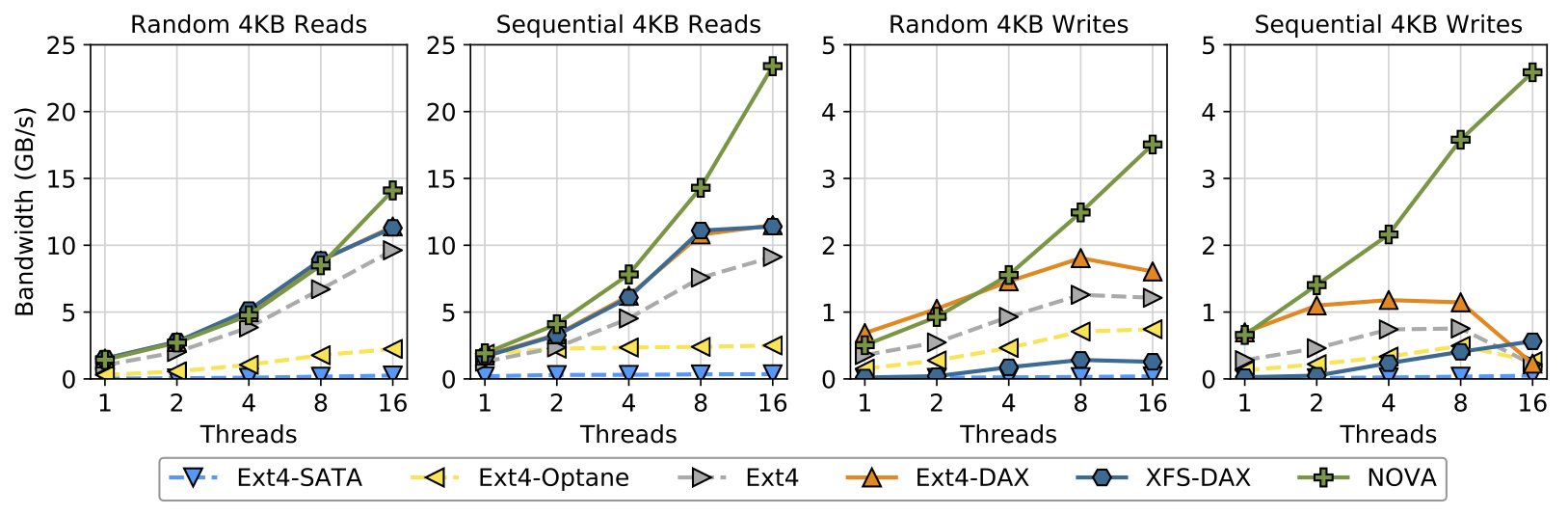
3DXPoint as Persistent Memory
3DXPoint’s most intriguing application is as a byte-addressable persistent memory that user space applications map into their address space (with the mmap() system call) and then access directly with loads and stores. Using 3DXPoint in this way is more complex than accessing through a conventional file-based interface because the application has to ensure crash consistency rather than relying on the file system. However, the potential performance gains are much larger.
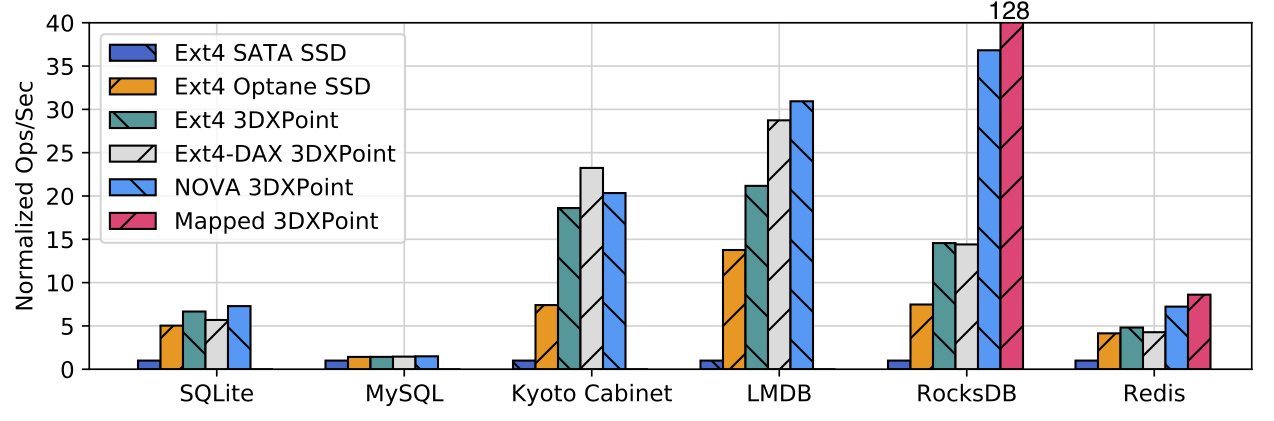
Our final figure, illustrates the benefits of aggressively exploiting 3DXPoint for application-level performance on RocksDB, Redis, MySQL, SQLite, and LMDB. MySQL is running TPC-C; the others are running workloads that insert key-value pairs.
The impact at the application level varies widely, but the data show the impact of more aggressively integrating 3DXPoint into the storage system. Replacing flash memory with 3DXPoint in the SSD (and moving to the PCIe bus) gives a significant boost, but for most applications deeper integration with hardware (i.e., putting the 3DXPoint on a DIMM rather than an SSD) and software (i.e., using an PMEM-optimized file system — “NOVA” — or rewriting the application to use memory-mapped persistent data structures — “Mapped 3DXPoint”) yields the highest performance.
The figure also shows the benefits of building native, memory-mapped, persistent data structures for Redis and RocksDB. The impact varies widely: performance for RocksDB increases by 3.5×, while Redis 3.2 gains just 20%. Understanding the root cause of the difference in performance and how to achieve RocksDB-like results will be fertile ground for developers and researchers.
Conclusion
Intel’s 3DXPoint is the first new memory technology to arrive in the processor’s memory hierarchy since DRAM appeared 50 years ago. It will take many years to fully understand how this new memory behaves, how to make the best use of it, and how applications should exploit it.
The data we present are a drop in the bucket compared to our understanding of other memory technologies. The data are exciting, though, because they show both 3DXPoint’s strengths and its weaknesses, both where it can have an immediate positive impact on systems and where more work is required.
We are most excited to see what emerges as persistent main memory moves from a subject of research and development by a small number engineers and academics to a mainstream technology used by, eventually, millions of developers. Their experiences and the challenges they encounter will give rise to the most innovative tools, the most exciting applications, and the most challenging research questions for 3DXPoint and other emerging NVMM technologies.
About the Author: Steven Swanson is a professor of Computer Science and Engineering at the University of California, San Diego and director of the Non-Volatile Systems Laboratory.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
