
The focus of most published research in architecture is on applications implemented in high-performance, “close-to-the-metal” languages essentially developed before computers got fast. These, let’s call them metal languages, include FORTRAN (introduced in 1957), C (1972), and C++ (1985). Despite their age, these languages are far from dead! Programmers continue to write applications in them, and they continue to evolve: the just approved C++20 standard is the latest example.
But a lot of programming these days is done in what I’ll call the irrational exuberance languages of the late 1980s and early 90s, a time when it seemed like performance was going to get better forever, before Dennard scaling collapsed. Some of these so-called “scripting languages” are essentially moribund, like Perl (1987) and Tcl/Tk (1988), but many have become incredibly popular, like Python (1990), R (1993), JavaScript (1995), and PHP (also 1995). In fact, according to Stack Overflow’s annual developer survey, JavaScript and Python are now the #1 and #2 most used programming languages, respectively (excluding HTML/CSS and SQL as “programming languages”).
While these irrational exuberance languages have many differences, they also share many common characteristics, motivated by ease of implementation and a lack of focus on optimization. They are all dynamically typed, garbage collected (typically with extremely inefficient algorithms like primitive reference counting), generally interpreted, and effectively single-threaded. With the exception of JavaScript (more on that below), they are all notoriously slow and bloated.
Consider Python.
An integer in Python consumes 24 bytes instead of 4 bytes (because every object carries around type information, reference counts, and more), while the overhead for data structures like lists or dictionaries can be 4x that of their C++ counterparts.
The execution time story is even worse. As Leiserson et al. have pointed out in their recent Science article (“There’s plenty of room at the Top”) — and cited by Hennessy in his Turing lecture — a naive implementation of matrix-matrix multiply in Python runs between 100x and 60,000x slower than their counterparts written in a “metal” language (highly optimized C).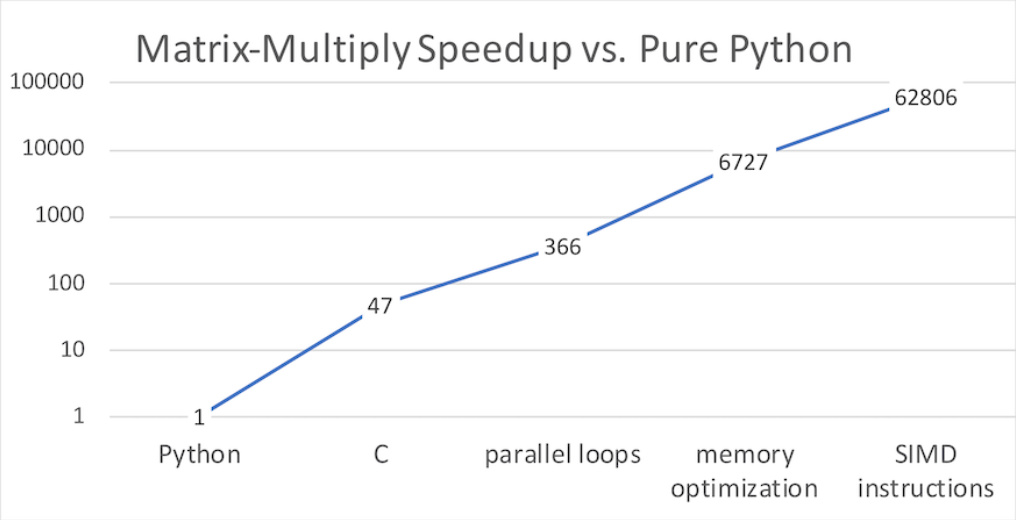
To be clear, these languages were not designed to be fast or space-efficient, but for ease of use. Unfortunately, their inefficiencies have now become a real problem.
There have been several efforts to make these languages faster. For JavaScript, those efforts have really paid off, but JavaScript is an outlier. First, its origin was in a monoculture (the browser) where there was no need for compatibility with legacy code. Second, optimization efforts for JavaScript were the subject of probably millions of developer hours by a number of companies, notably Google, Microsoft, and Mozilla, and built on decades of research in the PL community on how to optimize such languages (starting with the Self project, which started in the late 80s).
Unfortunately, languages like Python have proven resistant to efficient implementation, partly because of their design, and partly because of limitations imposed by the need to interop with C code. The current state-of-the-art Python compiler, pypy, often yields around a 2x improvement in performance (and sometimes less). This is something, but it’s nowhere close to making up the gap between Python and C. Part of the appeal of Python is that there is a vast array of libraries available for it; when these are written in C, they can go a long way to alleviating Python’s performance problems. But any time memory and application logic moves into Python land, it’s game over.
So what can we as a research community do to tackle this challenge? I suggest it’s long past time to move beyond C and SPEC benchmarks and our exclusive focus on “metal” languages. We need to start focusing on code written in languages where we can reasonably expect a vast number of cycles to be consumed, specifically JavaScript and Python. Just as we did before for C and C++, we can establish a foundation for understanding and improving performance for applications written in these languages.
- We need to incorporate JavaScript and Python workloads into our evaluations. There are already standard benchmark suites for JavaScript performance in the browser, and we can include applications written in node.js (server-side JavaScript), Python web servers, and more. This is where cycles are being spent today, and we need evaluation that matches modern workloads. For example, we should care less if a proposed mobile chip or compiler optimization slows down SPEC, and care more if it speeds up Python or JavaScript!
- We need to understand these applications and their interactions with all levels of the stack. Are caches large enough for this code? Can we do something to optimize giant event loops running bytecode interpreters at the architecture level (perhaps by revisiting ideas from long ago)? What about branch prediction tables? Is there room for accelerators? Better performance counters that will yield actionable insights? Who knows! But let’s find out and see if we can help. (There’s some work on hardware proposals for these systems, like Zhu et al., MICRO 15, Gope et al., ISCA 17, and Choi et al., ISCA 17, but we need more!)
- We need research on tool support to help programmers write more efficient applications. For example, existing profilers for these languages are essentially re-implementations of gprof and perf, ignoring the aspects of scripting languages that make them different. Python programmers need to distinguish between time and memory spent in pure Python (optimizable) from time and memory spent in C libraries (not so much). They need help tracking down expensive and insidious traffic across the language boundaries (copying and serialization). We have been developing a new profiler for Python called Scalene, that does exactly this, but plenty of work remains to be done.
To sum up: yes, metal languages will continue to be important, but so will the irrational exuberance languages. We as a community should lead the way in developing systems (at the hardware and software levels) that will make them run faster.

About the Author: Emery D. Berger is a professor in the College of Information and Computer Sciences at the University of Massachusetts Amherst.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
