
In the process of writing a short introduction to RISC-V, we compared RISC-V vector code to SIMD. We were struck by the insidiousness of the SIMD instruction extensions of ARM, MIPS, and x86. We decided to share those insights in this blog, based on Chapter 8 of our book.
Like an opioid, SIMD starts off innocently enough. An architect partitions the existing 64-bit registers and ALU into many 8-, 16-, or 32-bit pieces and then computes on them in parallel. The opcode supplies the data width and the operation. Data transfers are simply loads and stores of a single 64-bit register. How could anyone be against that?
To accelerate SIMD, architects subsequently double the width of the registers to compute more partitions concurrently. Because ISAs traditionally embrace backwards binary compatibility, and the opcode specifies the data width, expanding the SIMD registers also expands the SIMD instruction set. Each subsequent step of doubling the width of SIMD registers and the number of SIMD instructions leads ISAs down the path of escalating complexity, which is borne by processor designers, compiler writers, and assembly language programmers. The IA-32 instruction set has grown from 80 to around 1400 instructions since 1978, largely fueled by SIMD.
An older and, in our opinion, more elegant alternative to exploit data-level parallelism is vector architectures. Vector computers gather objects from main memory and put them into long, sequential vector registers. Pipelined execution units compute very efficiently on these vector registers. Vector architectures then scatter the results back from the vector registers to main memory.
While a simple vector processor might execute one vector element at a time, element operations are independent by definition, and so a processor could theoretically compute all of them simultaneously. The widest data for RISC-V is 64 bits, and today’s vector processors typically execute two, four, or eight 64-bit elements per clock cycle. Hardware handles the fringe cases when the vector length is not a multiple of the number of the elements executed per clock cycle. Like SIMD, vectors can operate on variable data widths. A vector processor with N 64-bit elements per register also computes on vectors with 2N 32-bit, 4N 16-bit, and 8N 8-bit elements.
Even the simple DAXPY function (below) illustrates our argument.
void daxpy(size_t n, double a, const double x[], double y[])
{
for (size_t i = 0; i < n; i++) {
y[i] = a*x[i] + y[i];
}
}
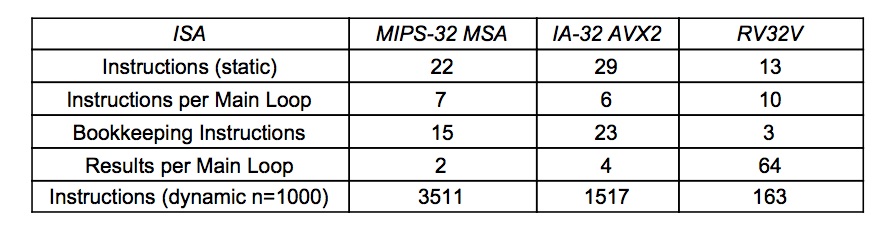
Figure 1. Number of instructions and total number of instructions executed for n = 1000. The bookkeeping code includes replicating the scalar variable a for use in SIMD execution, the stripmining code to handle when n is not a multiple of the SIMD register width, and to skip the main loop if n is 0. Figures 2–4 and text in the Appendix describe the compiled DAXPY code for each ISA.
Figure 1 summarizes the number of instructions in DAXPY of programs for MIPS-32 SIMD Architecture (MSA), IA-32 AVX2, and RV32V. (Figures 2 to 4 in the appendix shows the compiler output for RISC-V, MIPS-32, and IA-32.) The SIMD computation code is dwarfed by the bookkeeping code. Two-thirds to three-fourths of the code for MIPS-32 MSA and IA-32 AVX2 is SIMD overhead, either to prepare the data for the main SIMD loop or to handle the fringe elements when n is not a multiple of the number of floating-point numbers in a SIMD register.
RV32V code in Figure 2 of in the Appendix doesn’t need such bookkeeping code, which slashes the static number of instructions. Unlike SIMD, it has a vector length register vl, which makes the vector instructions work at any value of n.
However, the most significant difference between SIMD and vector processing is not the static code size. The SIMD instructions execute 10 to 20 times more instructions than RV32V because each SIMD loop does only 2 or 4 elements instead of 64 in the vector case. The extra instruction fetches and instruction decodes means higher energy to perform the same task.
Comparing the results in Figures 3 and 4 of the Appendix to the scalar versions of DAXPY, SIMD roughly doubles the size of the code in instructions and bytes, despite the main loop remaining the same size. The reduction in the dynamic number of instructions executed is a factor of 2 or 4, depending on the width of the SIMD registers. However, the RV32V vector static code size increases by a factor of only 1.2 yet the dynamic instruction count is a factor of 43 smaller.
While dynamic instruction count is a large difference, in our view that is the second most significant disparity between SIMD and vector. The worst is that size of the ISA mushrooms as well as the bookkeeping code. ISAs like MIPS-32 and IA-32 that follow the backwards binary compatible doctrine must duplicate all the old SIMD instructions defined for narrower SIMD registers every time they double the SIMD width. Hundreds of MIPS-32 and IA-32 instructions were created over many generations of SIMD ISAs and hundreds more are in their future, as the recent AVX-512 extension demonstrates once again. The cognitive load on the assembly language programmer of this brute force approach to data-level parallelism must be staggering. How can one remember what vfmadd213pd means and when to use it?
In comparison, RV32V code is unaffected by the size of the memory for vector registers. Not only is RV32V unchanged if vector memory size expands, you don’t even have to recompile. Since the processor supplies the value of maximum vector length mvl, the code in Figure 2 is untouched if the processor designer doubles or halves the vector memory.
In conclusion, as SIMD ISAs dictate the hardware, achieving greater data-level parallelism means changing the instruction set and the compiler. One can argue that SIMD violates the design principle of isolating architecture from implementation. In contrast, vector ISAs allow processor designers to choose the resources for data parallelism for their application without affecting the programmer or the compiler.
We think the high contrast in cost-energy-performance, complexity, and ease of programming between the vector approach of RV32V versus the ever expanding SIMD architectures of ARMv7, MIPS-32, and IA-32 is one of the most persuasive argument for RISC-V.
Appendix: DAXPY code and remarks for RV32V, MIPS MSA, & x86 AVX
Figure 2 shows the vector code in RV32V, the optional vector extension for RISC-V. RV32V allows vector registers to be disabled when not in use to reduce the cost of context switching, so the first step is to enable two double-precision floating point registers. Let’s assume the maximum vector length (mvl) is this example is 64 elements.
The first instruction in the loop sets the vector length for the following vector instructions. The instruction setvl writes the smaller of the mvl and n into the vector length register vl and t0. The insight is that if the number of iterations of the loop is larger than n, the fastest the code can crunch the data is 64 values at time, so set vl to mvl. If n is smaller than mvl, then we can’t read or write beyond the end of x and y, so we should compute only on the last n elements in this final iteration.
The following instructions are two vector loads (vld), a mutiply-add (vfmadd) to do the computation, a vector store (vst), four instructions for address arithmetic (slli, add, sub, add), a test if the loop is finished (bnez) , and a return (ret).
The power of vector architecture is that each iteration of this 10-instruction loop launches 3×64 = 192 memory accesses and 2×64 = 128 floating-point multiplies and additions (assuming that n is at least 64). That averages about 19 memory accesses and 13 operations per instruction. These ratios for SIMD are an order of magnitude worse.
# a0 is n, a1 is pointer to x[0], a2 is pointer to y[0], fa0 is a 0: li t0, 2<<25 4: vsetdcfg t0 # enable 2 64b Fl.Pt. registers loop: 8: setvl t0, a0 # vl = t0 = min(mvl, n) c: vld v0, a1 # load vector x 10: slli t1, t0, 3 # t1 = vl * 8 (in bytes) 14: vld v1, a2 # load vector y 18: add a1, a1, t1 # increment pointer to x by vl*8 1c: vfmadd v1, v0, fa0, v1 # v1 += v0 * fa0 (y = a * x + y) 20: sub a0, a0, t0 # n -= vl (t0) 24: vst v1, a2 # store Y 28: add a2, a2, t1 # increment pointer to y by vl*8 2c: bnez a0, loop # repeat if n != 0 30: ret # return
Figure 2. DAXPY compiled into RV32V. This loop works for any value of n, including 0; setvl turns the vector operations into nops when n = 0. RV32V associates the data type and size with the vector register, which reduces the number of vector instructions.
We now show how the code mushrooms for SIMD. Figure 3 is the MIPS SIMD Architecture (MSA) version and Figure 4 is for IA-32 using SSE and AVX2 instructions. (ARMv7 NEON doesn’t support double-precision floating point operations, so it can’t help DAXPY.)
Each MSA SIMD instruction can operate on two floating-point numbers since the MSA registers are 128 bits wide. Unlike RV32V, because there is no vector length register, MSA requires extra bookkeeping instructions to check for problem values of n. When n is odd, there is extra code to compute a single floating-point multiply-add since MSA must operate on pairs of operands. In the unlikely but possible case when n is zero, the branch at location 10 will skip the main computation loop. If it doesn’t branch around the loop, the instruction at location 18 (splati.d) puts copies of a in both halves of the SIMD register w2. To add scalar data in SIMD, we need to replicate it to be as wide as the SIMD register.
Inside the main loop, two load instructions (ld.d) read two elements of y and of x into SIMD registers w0 and w1, three instructions perform address arithmetic (addiu, addiu, addu), the multiply-add instruction (fmadd.d) does the computation, then a test for loop termination (bne) followed by a store (st.d) in the branch delay slot that saves the result. After the main loop terminates, the code checks to see if n is odd. If so, it performs the last multiply-add using scalar instructions. The final instruction (jr) returns to the calling site.
Intel has gone through many generations of SIMD extensions, which Figure 4 uses. The SSE expansion to 128-bit SIMD led to the xmm registers and instructions that can use them, and the expansion to 256-bit SIMD as part of AVX created the ymm registers and their instructions.
The first group of instructions at addresses 0 to 25 load the variables from memory, make four copies of a in a 256-bit ymm register, and tests to ensure n is at least 4 before entering the main loop. (The caption of Figure 4 explains how in more detail.)
The main loop does the heart of the DAXPY computation. The AVX instruction vmovapd at address 27 loads 4 elements of x into ymm0. The AVX instruction vfmadd213pd at address 2c multiplies 4 copies of a (ymm2) times 4 elements of x (ymm0), adds 4 elements of y (in memory at address ecx+edx*8), and puts the 4 sums into ymm0. The following AVX instruction at address 32, vmovapd, stores the 4 results into y. The next three instructions increment counters and repeat the loop if needed.
Similar to the code for MIPS MSA, the “fringe” code between addresses 3e and 57 deals with the cases when n is not a multiple of 4.
# a0 is n, a2 is pointer to x[0], a3 is pointer to y[0], $w13 is a 0: li a1,-2 4: and a1,a0,a1 # a1 = floor(n/2)*2 (mask bit 0) 8: sll t0,a1,0x3 # t0 = byte address of a1 c: addu v1,a3,t0 # v1 = &y[a1] 10: beq a3,v1,38 # if y==&y[a1] goto Fringe # (t0==0 so n is 0 | 1) 14: move v0,a2 # (delay slot) v0 = &x[0] 18: splati.d $w2,$w13[0] # w2 = fill SIMD reg. with copies of a Main Loop: 1c: ld.d $w0,0(a3) # w0 = 2 elements of y 20: addiu a3,a3,16 # incr. pointer to y by 2 FP numbers 24: ld.d $w1,0(v0) # w1 = 2 elements of x 28: addiu v0,v0,16 # incr. pointer to x by 2 FP numbers 2c: fmadd.d $w0,$w1,$w2 # w0 = w0 + w1 * w2 30: bne v1,a3,1c # if (end of y != ptr to y) go to Loop 34: st.d $w0,-16(a3) # (delay slot) store 2 elts of y Fringe: 38: beq a1,a0,50 # if (n is even) goto Done 3c: addu a2,a2,t0 # (delay slot) a2 = &x[n-1] 40: ldc1 $f1,0(v1) # f1 = y[n-1] 44: ldc1 $f0,0(a2) # f0 = x[n-1] 48: madd.d $f13,$f1,$f13,$f0# f13 = f1+f0*f13 (muladd if n is odd) 4c: sdc1 $f13,0(v1) # y[n-1] = f13 (store odd result) Done: 50: jr ra # return 54: nop # (delay slot)
Figure 3. DAXPY compiled into MIPS32 MSA. The bookkeeping overhead of SIMD is evident when comparing this code to the RV32V code in Figure 2. The first part of the MIPS MSA code (addresses 0 to 18) duplicate the scalar variable a in a SIMD register and to check to ensure n is at least 2 before entering the main loop. The third part of the MIPS MSA code (addresses 38 to 4c) handle the fringe case when n is not a multiple of 2. Such bookkeeping code is unneeded in RV32V because the vector length register vl and setvl instruction handle it. This code was generated by gcc with flags set to produce small code.
# eax is i, n is esi, a is xmm1,
# pointer to x[0] is ebx, pointer to y[0] is ecx
0: push esi
1: push ebx
2: mov esi,[esp+0xc] # esi = n
6: mov ebx,[esp+0x18] # ebx = x
a: vmovsd xmm1,[esp+0x10] # xmm1 = a
10: mov ecx,[esp+0x1c] # ecx = y
14: vmovddup xmm2,xmm1 # xmm2 = {a,a}
18: mov eax,esi
1a: and eax,0xfffffffc # eax = floor(n/4)*4
1d: vinsertf128 ymm2,ymm2,xmm2,0x1 # ymm2 = {a,a,a,a}
23: je 3e # if n < 4 goto Fringe
25: xor edx,edx # edx = 0
Main Loop:
27: vmovapd ymm0,[ebx+edx*8] # load 4 elements of x
2c: vfmadd213pd ymm0,ymm2,[ecx+edx*8] # 4 mul adds
32: vmovapd [ecx+edx*8],ymm0 # store into 4 elements of y
37: add edx,0x4
3a: cmp edx,eax # compare to n
3c: jb 27 # repeat loop if < n
Fringe:
3e: cmp esi,eax # any fringe elements?
40: jbe 59 # if (n mod 4) == 0 go to Done
Fringe Loop:
42: vmovsd xmm0,[ebx+eax*8] # load element of x
47: vfmadd213sd xmm0,xmm1,[ecx+eax*8] # 1 mul add
4d: vmovsd [ecx+eax*8],xmm0 # store into element of y
52: add eax,0x1 # increment Fringe count
55: cmp esi,eax # compare Loop and Fringe counts
57: jne 42 <daxpy+0x42> # repeat FringeLoop if != 0
Done:
59: pop ebx # function epilogue
5a: pop esi
5b: ret
Figure 4. DAXPY compiled into IA-32 SSE and AVX2. The SSE instruction vmovsd at address a loads a into half of the 128-bit xmm1 register. The SSE instruction vmovddup at address 14 duplicates a into both halves of xmm1 for later SIMD computation. The AVX instruction vinsertf128 at address 1d makes four copies of a in ymm2 starting from the two copies of a in xmm1. The three AVX instructions at addresses 42 to 4d (vmovsd, vfmadd213sd, vmovsd) handle when mod(n,4) ≄ 0. They perform the DAXPY computation one element at a time, with the loop repeating until the function has performed exactly n multiple-add operations. Once again, such code is unnecessary for RV32V because the vector length register vl and the setvl instruction makes the loop work for any value of n.
About the Authors: David Patterson is a Professor of the Graduate School in Computer Science at UC Berkeley and a Distinguished Engineer at Google. Andrew Waterman is Chief Engineer at SiFive and holds a PhD in Computer Science from UC Berkeley.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
