
With two blog posts, we argue for more use of simple models beyond Amdahl’s Law. This Part 1 discusses Bottleneck Analysis and Little’s Law, while Part 2 presents the M/M/1 Queue.
Computer systems, from the Internet-of-Things devices to datacenters, are complex and optimizing them can enhance capability and save money. Existing systems can be studied with measurement, while prospective systems are most often studied by extrapolating from measurements of prior systems or via simulation software that mimics target system function and provides performance metrics. Developing simulators, however, is time-consuming and requires a great deal of infrastructure development regarding a prospective system.
Analytic models—including simple ones like Amdahl’s Law—represent a third, often underused, evaluation method that can provide insight for both practice and research, albeit with less accuracy. Amdahl’s Law specifically gives an upper bound on the speedup of an N-processor computer system as 1/[(1-f) + f/N] where f is the fraction of work parallelizable. More generally, if a component X is used by a work fraction f and can be sped up by speedup S_x, Amdahl’s Law gives an upper bound on overall speedup as 1/[(1-f) + f/S_x]. While simple, Amdahl’s Law has proven useful, including quickly showing what is not possible.
Our thesis is that analytic models can complement measurement and simulations to give quick insight, show what is not possible, provide a double-check, and suggest future directions. To this end, we present three simple models that we find useful like Amdahl’s Law, split here into two blog posts. This post discusses Bottleneck Analysis and Little’s Law, while Part 2 touts the M/M/1 Queue. These three models, also presented together in an arXiv paper, can give initial answers to questions like:
- What is the maximum throughput through several subsystems in series and parallel?
- How many buffers are needed to track pending requests as a function of needed bandwidth and expected latency?
- Can one both minimize latency and maximize throughput for unscheduled work? (Answered in Part 2.)
These models are useful for insight regarding the basic computer system performance metrics of latency and throughput (bandwidth). Recall that latency—in units of time—is the time it takes to do a task (e.g., an instruction or network transaction). Throughput (called bandwidth in communication)—in units of tasks per time—is the rate at which tasks are completed. Throughput can be as simple as the reciprocal of latency but can be up to N times larger for N-way parallelism or N-stage pipelining.
Bottleneck Analysis
Bottleneck Analysis can yield an upper bound on the throughput (bandwidth) of a system from the throughput of its subsystems. It provides a quick calculation for what a system may or can’t do. If throughput is bottlenecked too low, no amount of buffering or other latency-reducing techniques can help.
Bottleneck Analysis gives the maximum throughput of a system from the throughputs of the system’s subsystems with two rules that can be applied recursively:
- The maximum throughput of K sub-systems in parallel is the sum of the subsystem throughputs.
- The maximum throughput of K sub-systems in series is the minimum of the subsystem throughputs.
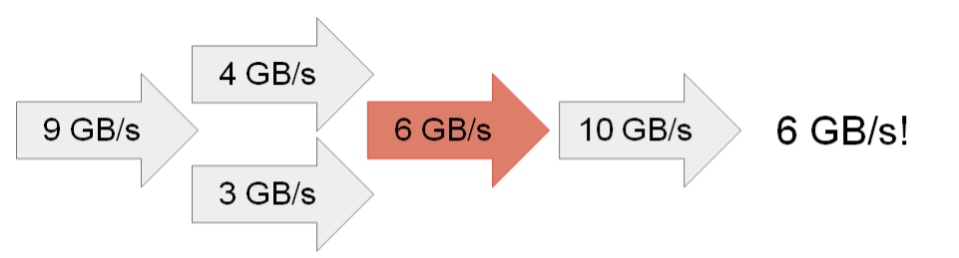
Figure 1: Bottleneck Analysis (bottleneck is colored)
Consider an example and literature pointers. Figure 1 gives an example where the arrows represent subsystems and bottleneck analysis finds the system’s maximum throughput to be: 6 GB/s = MIN(9, (4+3), 6, 10). The Roofline and Gables models use bottleneck analysis to provide insight regarding multicore chips and Systems on a Chip (SoCs), respectively. Lazowska, et al. (now online) more fully develops bottleneck analysis and other methods.
Bottleneck Analysis can also bring attention to system balance: decreasing all non-bottlenecked throughputs until they are (near) bottlenecks can reduce cost without changing throughput. Generally, systems should be bottlenecked by the most expensive subsystem(s) first. However, Bottleneck Analysis ignores latency, which can be important as the next two models show.
Little’s Law
Little’s Law shows how total latency and throughput can relate. A colleague and I used to remark that Little’s Law was our key industrial consulting tool. Consider a system in Figure 2 in steady state where tasks arrive, stay in the system, and depart. Let R be the rate (throughput, bandwidth) that tasks arrive (and, in steady state, they must depart at the same rate R), T be the average number of tasks in the system, and L be the average latency a task spends in the system. Little’s Law says:
Average number of tasks in system T = average latency L * average arrival rate R.
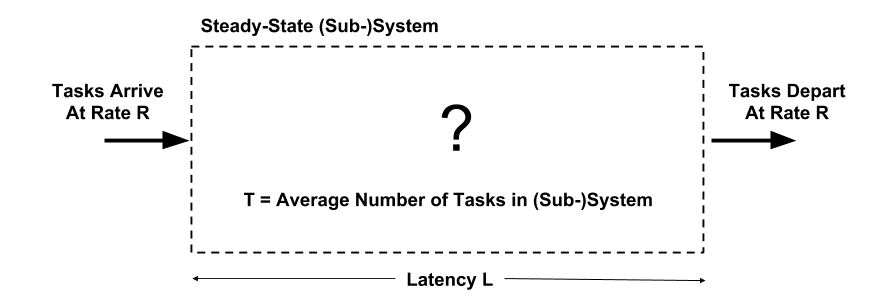
Figure 2: (Sub-)System for Little’s Law
For example, how many buffers must a cache have to record outstanding misses if it receives 2 memory references per cycle at 2.5 GHz, has a miss ratio of 6.25%, and its average miss latency is 100 ns? Little’s Law reveals the answer of 32 buffers. (To check the math: L = 100 ns; R = 0.3125 Gmisses/s = (2 ref./cycle)*(2.5 GB/s)*(0.0625 misses/ref.); T = 32 ≥ 100*0.3125.) However, as we will see later, more buffers will be needed for the common case when misses occur unscheduled and bursts make some miss latencies (much) larger than 100 ns.
A beauty of Little’s Law is that it is tri-directional: given any two of its parameters, one can calculate the third. This is important as some parameters may be easier to measure than others. Assume that your organization processes travel reimbursements and wants to know the average processing time (latency). If 200 requests arrive per day and there are 10,000 requests pending in the system, then Little’s Law reveals an average of 50 days to process each request = 10,000 requests / (200 requests/day).
Forecast to Blog Post Part 2
While Little’s Law provides a black-box result it does not expose trade-offs. In our second blog post, we will present the M/M/1 queue that confronts us with a stark, required trade-off among (a) allowing unscheduled task arrivals, (b) minimizing latency, and (c) maximizing throughput.
About the Author: Mark D. Hill is John P. Morgridge Professor and Gene M. Amdahl Professor of Computer Sciences at the University of Wisconsin-Madison. He is a fellow of IEEE and the ACM, serves as Chair of the Computer Community Consortium (2018-20) and served as Wisconsin Computer Sciences Department Chair 2014-17.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
