
Background
These are exciting and challenging times for computer architects. The looming end of Moore’s law and the breakdown of Dennard scaling force everybody to put on their thinking caps and envision what future processors will look like when transistors stop improving. One of the leading approaches to mitigate the effects of the end of Moore’s law is the shift towards specialized “accelerator” chips.
The accelerator approach has a solid rationale: if transistor budgets cannot improve, we need to build efficient chips that are tailored for specific domains and deliver better application gains under a non-improving budget. Another key driver for accelerators stems from the growing popularity of domains such as deep learning and graph processing that produce classes of “killer apps” for specialized chips. These are compute-intensive applications with high levels of parallelism and computation pattern reuse. Conditions have matured for us to enter an accelerator “golden age,” and almost every large tech company embeds domain-specific GPUs, FPGAs, and ASIC chips in data centers and mobile SoCs.
One thing to be mindful about with accelerator chips is that they are… chips. As such, they are implemented using transistors, and enjoy the “free lunch” provided by Moore’s law in the form of still-improving transistor budgets. Looking forward, since the number of ways to map a computational problem to hardware under a fixed transistor budget is limited, the HW/SW optimization space is finite (albeit potentially large). Therefore, much like general-purpose processors, accelerators are prone to the end of Moore’s law. This observation raises the pressing question: Empirically, how much have existing accelerators depended on the (nearly-ending) improvement in transistor budgets, and by how much did they improve their targeted-domain, independent of their transistor budget?
Accelerator Evaluation: How to Separate-Out Moore’s “Free Lunch” Component?
When comparing accelerators, saying something like: “our new accelerator ‘A’ has 2x the FLOPs as the competitor’s accelerator ‘B'” is insufficient. We would also want to know whether accelerator A has, for example, 4x as many transistors than accelerator B, or maybe that its underlying circuitry is 3x faster since it was implemented using a newer CMOS technology. If two people are racing on the same track, racing times matter – but wouldn’t we also want to know that one is riding a bike while the other is driving a Lamborghini?
With that in mind, we need to decouple the two components that comprise an accelerator’s “gain” (e.g., throughput, energy-efficiency, area-efficiency, etc.) (I) The CMOS-driven component: the ability of the chip to deliver better gains due to an improved transistor budget, for example: higher transistor count, faster or more energy-efficient transistors, and so on. (II) the Chip Specialization Return (CSR) component, which is the question of: “how good of a job the accelerator chip designer(s) did, using the transistor budget given?”
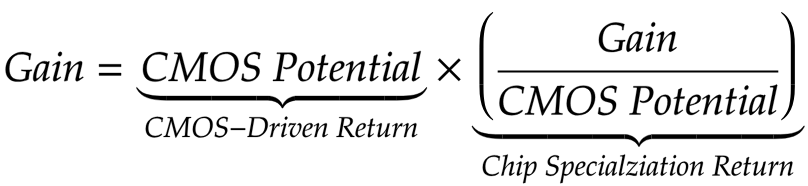
There are two main reasons for evaluating accelerators using CSR. (I) In contrast to absolute gains, CSR provides a way of assessing the HW/SW optimization quality of an accelerator, eliminating the “free lunch” technology scaling factor. (II) Once Moore’s law ends, CSR is likely all we are left with, and we should empirically analyze what it gave us, as it would serve as an indicator of what we can get in the future.
Chip specialization is almost impossible to quantify. The HW/SW optimization stack consists of many moving pieces that contribute to specialization returns: architectural decisions, different accelerator platforms (e.g., GPUs vs. ASICs), advancements in chip design methodologies and tools, implementation of new and more hardware-friendly algorithms for the same domain, different programming platforms (e.g., HDL vs. HLS), new software libraries, and so on. Instead, it might be simpler to characterize the CMOS-driven return and consequently, derive CSR. This characterization can be done using a chip-level CMOS potential tool that we have developed, called: Rankine. A chip’s CMOS potential is determined by its physical characteristics (e.g., CMOS node, die size, TDP, etc.), and by the target gain. For example, chip X is expected to be twice as fast as chip Y that has the same number of transistors, but with a slower CMOS node that has 2x switching delay. Therefore, much like physical potentials, the absolute value of a CMOS potential is meaningless, but it is useful when comparing accelerators. For a given application and a group of accelerators with different reported gains and physical characteristics, by calculating the CMOS potential (relative to a baseline accelerator), it is possible to decouple the contribution of the (nearly-ending) CMOS potential from the contribution of specialization to the reported gains.
Demystified Pitfalls in Existing Accelerators
An analysis of accelerators in popular domains, while using of Rankine to separate the contributions of CMOS and CSR, uncovered a few trends. Specialization returns are still improving in emerging domains such as deep-learning, as they enjoy the slew of recent innovations (e.g., saving FLOPS using algorithmic-mapping ). However, that was not the case for other domains such as graphics processing using GPUs, video decoding using ASICs, and Bitcoin mining using ASICs. These domains suffer from diminishing specialization returns that are only quantifiable using the CSR (or similar) analysis. In each domain, newer accelerators benefited from high transistor count and fast and energy-efficient circuity due to newer CMOS nodes. When normalizing by CMOS potential, it appears that specialization returns over the past years were modest (and sometimes even non-existent).
The observed diminishing specialization returns stem from several “pitfall patterns”: (i) Computational Confinement: Domains that have a fixed and straightforward hardware implementation have limited optimization opportunities that further improve specialization returns beyond a reasonable accelerator design. Bitcoin mining is an example of a confined domain. Miners employ brute-force parallelism of fixed SHA256 functions. Miner designs did not drastically change aside from a few one-time optimizations. (ii) Massive Parallelism: Domains like GPU graphics processing benefit from the increase in the number of on-chip processing elements, enabled via higher transistor counts. Therefore, parallelism is not a sustainable driving force, and it will become limited by the same dark silicon that limits general-purpose multi-core architectures. (iii) Domain Maturity: Since there can be a finite number of ways to map a computation to fixed-hardware, once a domain becomes well-studied, accelerators converge to similar (near-optimal) designs. Video decoding is an example of a domain studied over three decades, and for which recent ASIC designs consist of similar building blocks.
Interestingly, the abovementioned “pitfall patterns” were also identified as the same properties that make applications “acceleratable” in the first place: confined and massively-parallel applications are natural candidates for hardware mapping, and mature domains are popular and stable enough to justify the efforts of optimizing accelerators to execute them.
Lessons Learned and Final Thoughts
- Accelerators can deliver significant gains, but we must also be mindful about how much of these gains come from HW/SW optimization under a fixed-budget (good) and how much comes from having more hardware budget (not as good). It is important to do this analysis, since, in many cases, chip specialization delivered diminishing returns that were overshadowed by the gain attained through CMOS scaling.
- Accelerators have an inherent paradox: an application that is important enough will have HW/SW-optimized accelerators designed for it, but once we have a mature (near-optimal) accelerator design for it, we will encounter diminishing returns. The space of fixed HW/SW optimization is finite (albeit potentially large), and every explored option cannot be re-explored. Optimization gains are non-recurring.
- We cannot optimize infinitely. For any given application, we are likely to find out that accelerators run into an “accelerator wall” quickly after Moore’s law finally dies, and transistor budgets plateau. Therefore, chip-based specialization is not a long-term remedy for the end of Moore’s law. As IT research tends to precede future booming markets, we must start exploring specialization techniques that are not solely driven by transistor scaling, such as package-level integration, system-level co-optimization, the employment of still-scaling emerging memories, or other “beyond-CMOS” forms of computing.
About the Authors: Adi Fuchs is a PhD candidate in the Electrical Engineering department at Princeton University.
David Wentzlaff is an associate professor in the Electrical Engineering department at Princeton University.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
