
What is Multi-modal AI?
Prior research on developing on-device AI solutions have primarily focused on improving the TOPS (Tera Operations Per Second) or TOPS/Watt of AI accelerators by leveraging sparsity, quantization, or efficient neural network architectures searched using AutoML. While co-designing hardware, software, and algorithm for high energy-efficiency is certainly a crucial component in realizing efficient on-device AI solutions, an important research space that has rather been unexplored by computer system designers is how emerging, “multi-modal” learning algorithms are to be efficiently executed in on-device AI systems. Multi-modal AI is an emerging field of study that learns to consolidate disconnected heterogeneous data from various sensors and data inputs into a single AI algorithm. A quote from Dr. David Ludden, Professor of Psychology, captures how our brain utilizes a multi-modal approach to better interpret the environment surrounding us and draw meaningful conclusions:
“Our intuition tell us that our senses are separate streams of information. We see with our eyes, hear with our ears, feel with our skin, smell with our nose, taste with our tongue. In actuality, though, the brain uses the imperfect information from each sense to generate a virtual reality that we call consciousness. It’s our brain’s best guess as to what’s out there in the world. But that best guess isn’t always right.”
Based on similar intuitions, AI algorithms that combine signals from different modalities (e.g., vision + speech + text) can enable robust inference but more importantly, it opens up new insights that would have been impossible to reap under the current, uni-modal AI algorithms. Google for instance has begun using multi-modal learning to optimize how smartphone users interact with Google Assistant via both speech and touch for personalized experience. Using both vision and speech for gesture recognition in AR/VR devices, in-car assistant in autonomous vehicle’s human-machine interface, and conversational AI algorithms are another emerging application domain that heavily utilizes multi-modality (Figure 1). All of these application domains can significantly benefit from accelerated on-device AI processing as they require fast response time for end-user satisfaction.
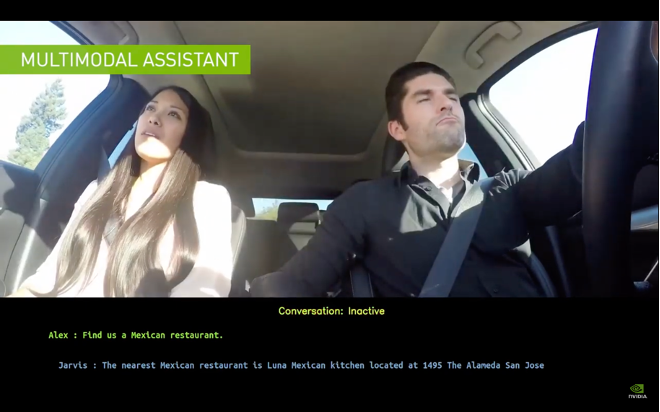
Figure 1. Example usage of multi-modal AI in NVIDIA’s conversational AI.
Task-level Parallelism in Multi-modal AI
While combining a heterogeneous mix of different modalities for improving AI algorithmic performance seems intriguing, a crucial challenge lies in how the features of each modality are synergistically combined for better algorithmic performance. One popular method of mixing different modalities is to have the frontend of multi-modal learning applications be fed in with multiple, independent input data streams coming in from different sensors (i.e., image, speech, text, touch). As shown in Figure 2, each of these input streams are executed by a deep neural network (DNN) for feature extraction, all of which are fused altogether by a backend processing stage for feature interaction. There is a rich set of prior literature discussing the best ways of fusing different feature modalities; one popular method being simply concatenating the output feature vectors of each modality stream. An interesting property of these multi-modal AI workloads, from a computer architect’s perspective, is that the three DNN executing stages at the frontend can all be processed independently, exhibiting task-level parallelism for parallel execution.
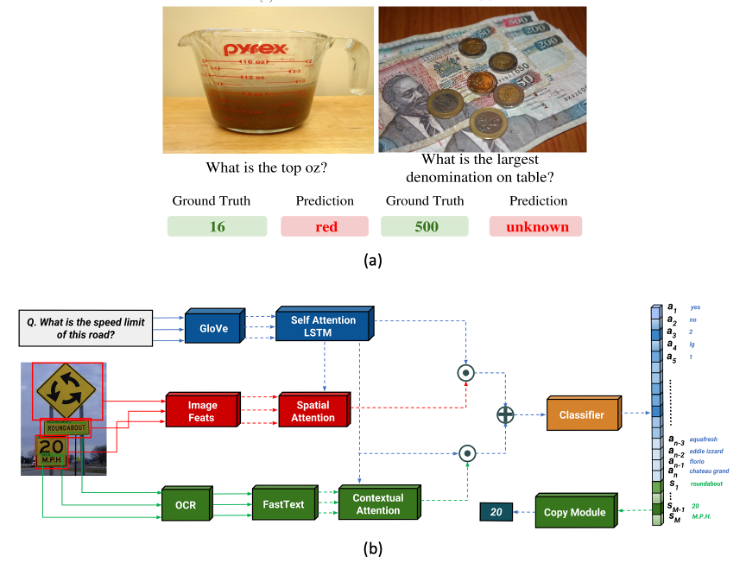
Figure 2: An example (a) VQA (Visual Question Answering) application, utilizing (b) multi-modal AI (text and vision). Figures are from Singh et al. “Towards VQA Models That Can Read”, CVPR’19
Heterogeneous Computing in On-Device AI?
Unlike server-oriented AI systems utilizing homogeneous compute devices (e.g., GPU-/NPU-only), today’s most representative on-device AI systems (e.g., Samsung’s Exynos SoC, Apple’s M1 SoC, and Tesla’s Full Self Driving computer) contain a heterogeneous set of processor architectures including CPUs, GPUs, DSPs, and now NPUs (Figure 3). Each of these processor architectures are optimized under a different design objective (e.g., latency-optimized CPUs vs. throughput-optimized GPUs and NPUs), exhibiting complementary compute and memory access capabilities. As noted above, multi-modal AI algorithms exhibit significant task-level parallelism enabling parallel execution of (parts of) different modalities, but with several, application-specific constraints that require sequential or synchronous execution.

Figure 3: Heterogeneous computing devices within SoCs in (a) Apple’s M1 chip with on-package unified memory and (b) Tesla’s FSD chip. While details of the FSD chip from a “systems” perspective is scarce, Apple did reveal that the unified memory system built inside M1 is truly “unified” in the sense that it helps remove redundant data copies across different processor address spaces (a classic problem in heterogeneous architectures sharing the same physical memory over two disparate virtual address spaces).
Given these conditions, these (multi-tasked) multi-modal AI workloads open up an interesting research space. Some examples include: (i) how should the software layer partition the multi-modal task and schedule them over the heterogeneous set of processor architectures available on-device, or (ii) how should the memory subsystem (e.g., memory controller) handle the heterogeneous memory access locality properties of multi-modal AI. The computer architecture community is no stranger to such “heterogeneous computing” architectures, a recent example being heterogeneous CPU+GPU computing using CUDA/OpenCL. For instance, the work on “CPU-assisted GPGPU on fused CPU-GPU architectures”, published in HPCA-2012, presented a collaborative CPU-GPU execution model where the CPU runs ahead of the GPU to prefetch GPU’s data into shared LLC for improved throughput. Work by Lee et al. (HPCA-2012) and Ausavarungnirun et al. (ISCA-2012) presented “heterogeneity-aware” on-chip cache partitioning algorithm and memory scheduling algorithm, respectively, for integrated CPU-GPU systems, demonstrating the merits of an application-aware architecture design.
Of course, none of these prior works explored the efficacy of these schemes for emerging AI workloads. Nonetheless, it will be interesting to see if the lessons our community has learned from prior heterogeneous computing literature can also be applied for multi-modal AI, so hopefully this article can spur another interesting research direction in the areas of AI systems research.
About the author: Minsoo Rhu is an associate professor at the School of Electrical Engineering at KAIST (Korea Advanced Institute of Science and Technology). His current research interests include computer system architecture, machine learning accelerators, and ASIC/FPGA prototyping.
Disclaimer: These posts are written by individual contributors to share their thoughts on the Computer Architecture Today blog for the benefit of the community. Any views or opinions represented in this blog are personal, belong solely to the blog author and do not represent those of ACM SIGARCH or its parent organization, ACM.
